State-of-the-Art (SOTA) AI Models: LLMs, NLP, and Computer Vision
Learn about the state-of-the-art (SOTA) AI models transforming machine learning. This article explores advancements in large language models (LLMs), natural language processing (NLP), and computer vision. See how they achieve unprecedented accuracy and efficiency and why they matter in real-world.


Introduction
Artificial Intelligence has made astonishing strides in recent years. Every few months, researchers announce a new state-of-the-art (SOTA) model – meaning the best-known AI model for a particular task at that time. These SOTA models set new records in accuracy, capability, or efficiency on benchmarks, often reaching or even surpassing human-level performance in specialized tasks. They’re powered by advanced machine learning techniques and massive amounts of data. In this article, we’ll explore the latest breakthroughs in large language models (LLMs) and natural language processing (NLP), as well as computer vision – highlighting notable models and why they matter.
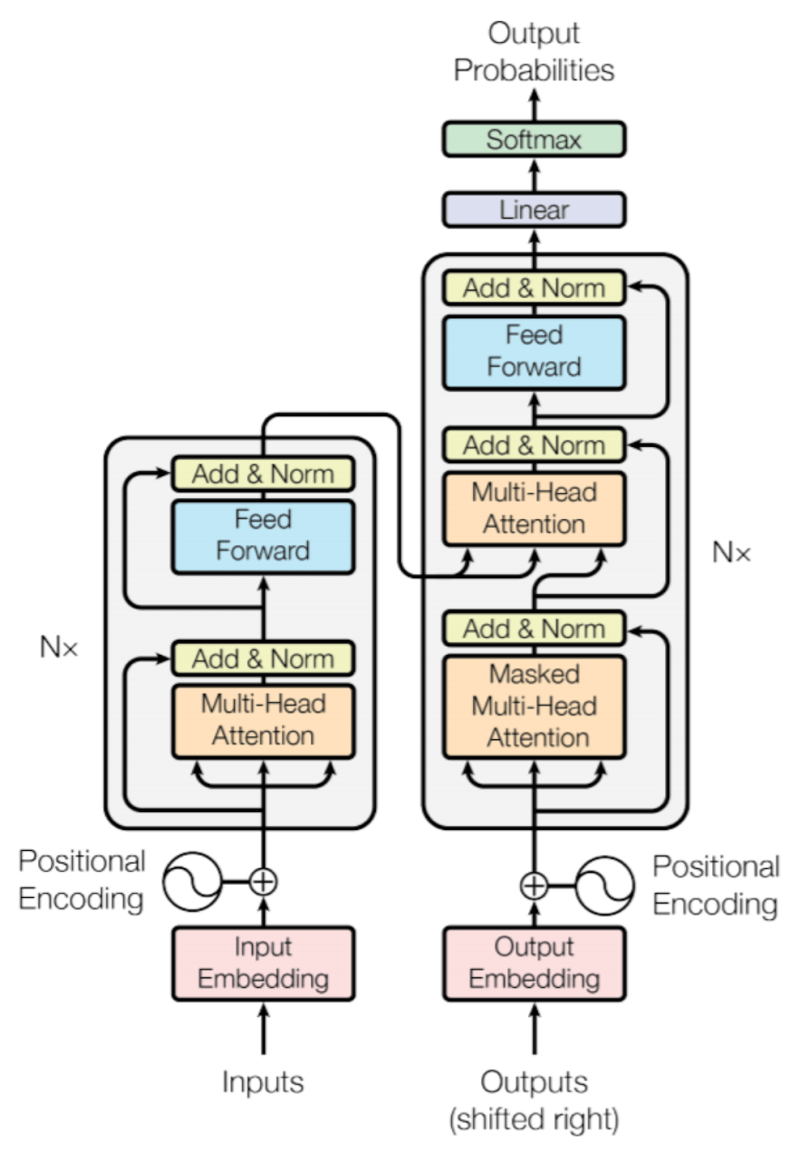
One key driver behind many recent SOTA models is the Transformer architecture. Introduced by researchers in 2017’s “Attention Is All You Need” paper, Transformers revolutionized how AI systems handle language and sequences. Unlike older recurrent neural networks, Transformers process input in parallel and use an attention mechanism to decide which parts of the data are most important (Vision Transformer: What It Is & How It Works [2024 Guide]). This innovation enabled a new generation of models that can learn from unprecedented amounts of data and context. The impact was soon felt across AI subfields – from language understanding to image analysis (Transformer (deep learning architecture) - Wikipedia). In simple terms, the Transformer allowed AI to scale up big and versatile models that are the foundation of today’s AI breakthroughs.
Now, let’s dive into specific domains and see what the state-of-the-art looks like in practice.
SOTA in Natural Language Processing (NLP) and LLMs
NLP deals with teaching machines to understand and generate human language. The past few years have seen large language models (LLMs) dominate this field. LLMs are AI models trained on billions of words (from books, websites, etc.) to predict and produce text. Early milestones included BERT (2018) by Google, which introduced bidirectional understanding of context and achieved state-of-the-art results on many NLP benchmarks at the time. BERT’s success opened the floodgates to even larger models and novel techniques for language tasks.
Today’s headline-makers are models like OpenAI’s GPT-3 and GPT-4, Google’s PaLM 2, and Meta’s LLaMA. These models are incredibly advanced – they can carry on conversations, write code, summarize articles, and much more. For instance, OpenAI’s GPT-4 (released 2023) is a multimodal LLM that accepts text and image inputs and produces text outputs. It has demonstrated human-level performance on various professional and academic benchmarks (GPT-4 | OpenAI). For example, GPT-4 can pass a simulated bar exam in the top 10% of test-takers (where its predecessor GPT-3.5 was in the bottom 10%) (GPT-4 | OpenAI). This leap in capability showcases how far language models have come.
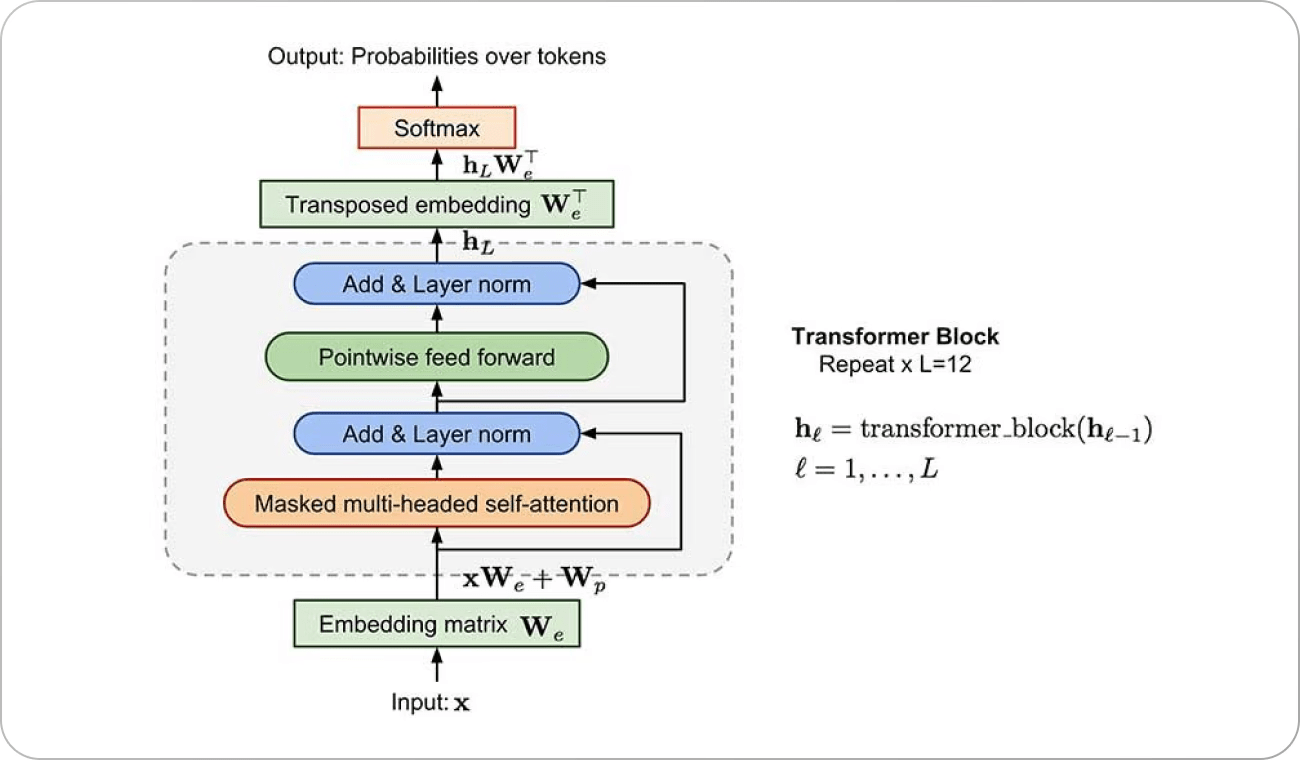
These models are called “state-of-the-art” because on tasks like language comprehension, question answering, or creative writing, they outperform all previous systems. They leverage massive neural network architectures with many parameters (GPT-4 is rumored to use trillions of parameters) and are trained with advanced techniques to follow instructions and stay factual. The result is that interacting with modern LLMs can feel eerily like conversing with a knowledgeable human. ChatGPT, built on GPT-3.5 and GPT-4, famously brought this experience to millions of users, demonstrating how SOTA NLP can be applied in the real world as a helpful assistant.
It’s not just English text or general knowledge either – specialized language models exist for coding (like GitHub’s Copilot, based on OpenAI Codex), for multiple languages, and even for scientific research. Large language models are a prime example of foundation models (more on this later) – they serve as a base that can be adapted to many language tasks with minimal additional training. The upshot is that SOTA NLP models have made language translation more accurate, virtual assistants more intelligent, and information more accessible than ever before.
SOTA in Computer Vision (CV)
Computer vision is the field of AI that enables machines to interpret and understand visual data like images or videos. SOTA models in vision can recognize objects in photos, detect activities in videos, and even generate images. Let’s break down a few key tasks and the state-of-the-art models addressing them:
- Image Classification: deciding what main object or scene an image contains (e.g. “cat” or “dog”). For many years, convolutional neural networks (CNNs) led the pack in image classification. A landmark was AlexNet in 2012, which was the first deep CNN to achieve SOTA performance on the ImageNet challenge, beating older approaches. From there, CNNs like VGG, ResNet, and EfficientNet continued to raise the bar. These models could identify thousands of object categories with superhuman accuracy on benchmark datasets. Recently, the introduction of Vision Transformers (ViT) by Google showed that transformer-based models (so successful in NLP) can also excel in vision. In fact, Vision Transformers have been found to outperform the state-of-the-art CNNs in both efficiency and accuracy for image recognition tasks (Vision Transformer: What It Is & How It Works [2024 Guide]). In practice, this means models can classify images faster and with even fewer errors.
- Object Detection: locating and classifying multiple objects within an image (drawing bounding boxes around each). One popular family of models leading object detection is the YOLO series (You Only Look Once). YOLO models are known for their speed and accuracy, making real-time detection feasible. The latest iterations like YOLOv8 (and beyond) are described as “state-of-the-art computer vision models” for detection and segmentation. They can simultaneously identify dozens of objects in an image or video frame with high precision. For example, a single YOLOv8 model can detect people, cars, traffic signs, animals – you name it – all at once and at speeds suitable for video streaming. This is crucial for applications like autonomous driving or security systems.

The above image demonstrates how a SOTA vision model pinpoints different objects. This level of capability comes from sophisticated model architectures and large-scale training. YOLOv8, for instance, introduces architectural improvements over its predecessors to better extract features and handle objects of different sizes (How to Detect Objects with YOLOv8). In parallel, other detection models like Detectron2 (from Facebook AI) and Transformer-based detectors (like DETR) have pushed the envelope in accuracy, especially for challenging scenarios.
- Image Segmentation: a step beyond detection, segmentation means labeling every pixel in an image with its object class (essentially “cutting out” the objects precisely). Models like Mask R-CNN were early SOTA in segmentation, allowing, say, every pixel of a cat to be labeled as cat, separate from the background pixels. More recently, there’s excitement around models like Segment Anything Model (SAM) by Meta AI, which aims to segment any object given just a hint from the user – a testament to how robust segmentation algorithms have become. Even YOLOv8 mentioned above includes segmentation capabilities (How to Detect Objects with YOLOv8), showing that one model can now handle multiple vision tasks at high performance.
Another trend in SOTA vision models is combining modalities and leveraging massive pre-training, similar to NLP. CLIP by OpenAI, for example, learned to match images with text descriptions – effectively understanding visuals in a more general way. And just as “foundation models” exist in NLP, vision is seeing large pre-trained models (like Google’s CoAtNet or Meta’s DINOv2) that can be fine-tuned for various vision tasks with minimal data. The bottom line: today’s best vision models see the world with increasing clarity, enabling applications from medical image analysis (finding tumors in scans) to everyday tech like your phone’s camera recognizing faces and scenes automatically.
Generative AI and Multimodal Foundation Models
A particularly exciting area of AI is generative modeling – where AI doesn’t just understand content, but creates it. Recent state-of-the-art models have shown an almost magical ability to generate text, images, and more, blurring the line between human-made and machine-made content. These generative models often span multiple domains (text, vision, audio), so we call them multimodal models or more generally foundation models.
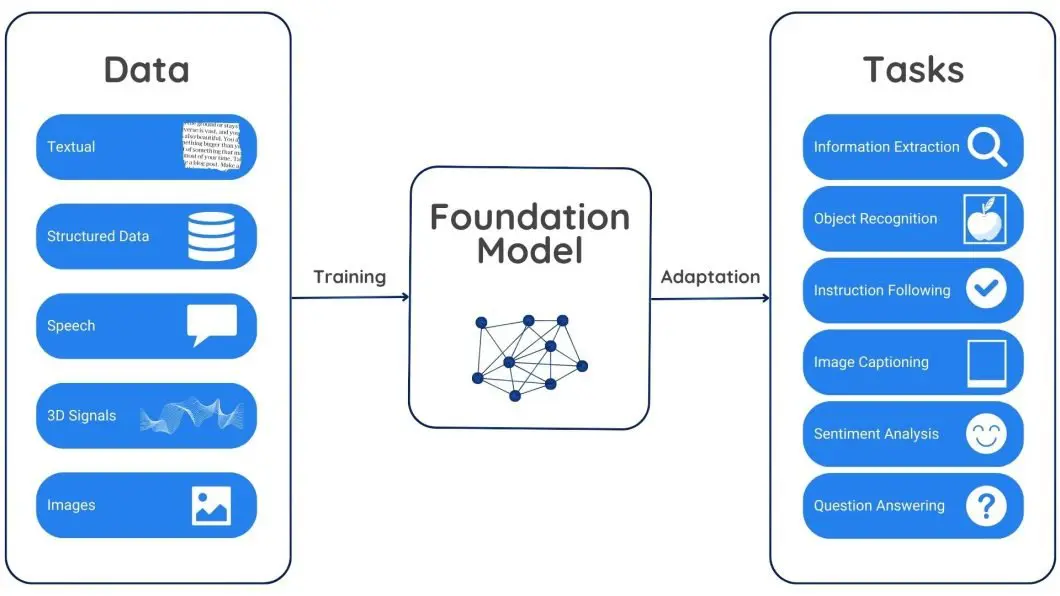
Foundation models are large-scale neural networks pre-trained on vast amounts of data (often in a self-supervised way) (Foundation Models in Modern AI Development (2025 Guide) - viso.ai). The idea is to learn a broad understanding of the world – whether through language, images, or other signals – and then fine-tune that general knowledge for specific tasks. Modern examples of foundation models include GPT-4 and BERT for language, DALL-E 3 and Stable Diffusion for images, and CLIP which connects text and vision. Even multitalented models like Gato from DeepMind (which can play games, caption images, chat, etc.) fall into this category.
In the generative art realm, SOTA models like Stable Diffusion and OpenAI’s DALL-E can create stunning visuals from a simple text prompt. Want a picture of “a castle in the clouds in Van Gogh’s style”? These models can paint it for you. They’ve been trained on millions of images to learn the relationships between words and visual elements. Similarly, generative music models and voice synthesis models can produce songs or clone a person’s voice after training on large audio datasets.
Another leap has been multimodal LLMs – models that handle more than one type of input/output. GPT-4, as mentioned, accepts images and can generate text about them (describing what’s in a photo, for example). Google’s recent model PaLM-E combines vision and language for robotic tasks.
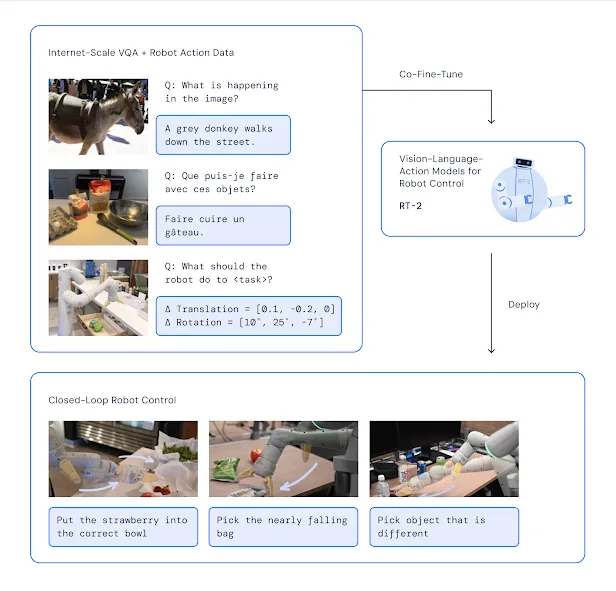
We co-fine-tune a pre-trained vision-language model on robotics and web data. The resulting model takes in robot camera images and directly predicts actions for a robot to perform.
And Google DeepMind’s upcoming Gemini is reported to merge advanced language understanding with cutting-edge visual reasoning (2023: A Year of Groundbreaking Advances in AI and Computing - Google DeepMind). These efforts aim to create AI that can see, talk, and think in an integrated way, much like humans use multiple senses and modes of communication together.
The convergence of these technologies means AI systems are becoming extremely versatile. An AI assistant today can analyze an image you upload, figure out what it is, and have a conversation with you about it – a scenario that was pure science fiction not long ago. State-of-the-art generative models are enabling creative tools as well: artists use them to brainstorm ideas or generate backgrounds, writers use AI to draft content, and game designers use AI to generate graphics and dialogue. We’re essentially witnessing the rise of AI as a content creator and a general problem-solver, built on the back of foundation models that encapsulate a wide breadth of knowledge.
Real-World Impact and the Rapid Pace of Progress
SOTA AI models aren’t just laboratory experiments – they’re rapidly making their way into products and services that affect our daily lives. Virtually every industry is feeling the impact of these advancements:
Healthcare
AI-powered vision systems are supporting radiologists by detecting tumors, fractures, and other abnormalities in medical scans with increasing accuracy. Natural language processing (NLP) models assist in summarizing patient histories or transcribing doctor notes into medical records. Some hospitals also use predictive models to assess patient risks or optimize treatment schedules. While these systems do not replace medical professionals, they function as a secondary layer of analysis that can reduce oversight and administrative burden.
Finance and Banking
In finance, machine learning models are widely used for fraud detection by recognizing unusual spending patterns in real time. AI helps underwrite loans by analyzing credit histories and alternative data, while trading firms use algorithms to make split-second market decisions. Customer-facing AI assistants support users with account-related questions or basic financial advice. These tools allow financial institutions to process information at a scale impossible for human teams alone.
Autonomous Systems and Robotics
Autonomous vehicles rely on advanced computer vision models to detect traffic signs, pedestrians, and road conditions. Robotics is increasingly powered by multimodal models that combine visual input and language understanding to follow instructions, such as in warehouse automation or robotic arms in manufacturing. Research projects like Google’s PaLM-E show how language models can translate visual perception into physical actions, allowing robots to interact with the world more flexibly. While still developing, these systems are moving from controlled environments to real-world deployment.
Customer Service and Education
Language models are now standard in customer support, like answering questions, generating responses, or triaging issues before human intervention. In education, AI is used for tutoring, language learning, and interactive problem-solving. Another emerging use is AI-based interview simulation, where students can practice conversational scenarios in a structured format. Among the tools in this area is Confetto, which provides medically oriented interview simulations and feedback for students preparing for medical school admissions. This reflects a broader shift in AI use, from delivering information to simulating human interaction for learning and assessment.
Creative Work and Media
Generative AI has reshaped creative fields by helping produce images, video concepts, text drafts, music, and visual effects. Designers use models like Stable Diffusion or Midjourney to prototype visuals, while writers experiment with AI to develop ideas or refine storylines. In film and gaming, AI assists with dialogue generation, worldbuilding, and character animation. These tools don’t replace human creativity, but they offer a new layer of support, turning simple prompts into starting points for professional work.
In essence, modern SOTA models serve as a bridge from theoretical AI research to practical applications. Each improvement in accuracy or capability enables new uses that were previously unreliable. As one article succinctly put it: “SOTA has an immense impact on real-world applications across various domains... enabling advancements in diagnosis, recommendation systems, image recognition, speech processing, and more.” (What Is SOTA In Machine Learning | Robots.net) Industries are being revolutionized as AI systems become more competent. Tasks that used to require expert human effort (like translating between languages or inspecting thousands of images for defects) can now be done – at least in part – by AI with SOTA models guiding the way.
It’s important to note, however, that “state-of-the-art” does not mean “perfect.” For example, GPT-4, while incredibly advanced, can still make factual errors or exhibit biases it learned from data. SOTA vision models might misidentify objects in unusual conditions. Researchers are actively working on these reliability issues, and each generation of model is generally more reliable than the last. In fact, OpenAI reported that GPT-4 was their best-ever model in terms of factual accuracy and adherence to desired behavior, thanks to training improvements – but they also acknowledge it’s “far from perfect” (GPT-4 | OpenAI). So, as much as we celebrate the achievements, ongoing research is crucial to iron out limitations.
Another striking aspect of SOTA AI is how quickly it evolves. What’s the best today might be old news next year. The AI research community is large and very active – new papers and models come out literally every day. There are thousands of benchmarks used to measure AI progress, and they are constantly being updated. (For a sense of scale, the website Papers With Code, which tracks SOTA results, lists over 12,000 benchmarks and 157,000+ research papers in its database (Browse the State-of-the-Art in Machine Learning | Papers With Code)!) This rapid progress means that AI capabilities often follow an upward curve – for instance, language models have roughly doubled their parameter count (and along with it, often their performance on certain tasks) every year or two recently.
From a user’s perspective, this pace of change can be exciting but also overwhelming. Today’s cutting-edge AI chatbot might get a major upgrade within months, becoming even more fluent and knowledgeable. Vision models that recently struggled with certain image types might suddenly get much better with a new architecture. For businesses and developers, keeping up with SOTA means continuously learning and sometimes retraining systems to use the newest techniques.
The good news is that many SOTA models are being shared openly. Some are released as open source, and others via public APIs, which means the accessibility of advanced AI is higher than ever. You don’t need to be a giant tech company to leverage them. This democratization helps spread the benefits around. We see startups building on top of GPT-4 for everything from legal document analysis to personal fitness coaching. We see non-profits using vision models to track wildlife populations from camera footage. Such real-world deployments are proof that SOTA AI is not just about impressive benchmarks; it’s a tool that can be applied to solve real problems (when used correctly).
Conclusion
State-of-the-art AI and machine learning models represent the pinnacle of what we can achieve in tasks like language understanding and computer vision today. Thanks to innovations like the Transformer architecture and the paradigm of large-scale pre-training, machines have acquired abilities that were unthinkable a decade ago – holding conversations, explaining jokes, detecting cancer in scans, or creating a piece of digital art from scratch. Importantly, all this is delivered in ways increasingly accessible to the average person, whether through a smartphone app or an online service.
While the underlying technology is undeniably complex, the takeaway for most of us is that AI is getting smarter, more capable, and more helpful at a breathtaking rate. SOTA models push the boundaries and then quickly find their way into tools we use. It’s an exciting time: AI is evolving from niche research into a general-purpose ally in many aspects of life. Of course, with great power comes responsibility – and there’s active discussion on ethics, fairness, and safety of these models – but the trajectory of progress is clear.
In summary, today’s AI can read, write, see, and create at levels that often rival human expertise, all thanks to state-of-the-art models in NLP, vision, and beyond. And as researchers continue to collaborate and iterate, tomorrow’s models will likely be even more impressive. For the average person, it’s worth keeping an eye on these developments, because they are not just tech headlines – they are milestones on a journey toward more intelligent machines that impact our everyday lives. The world of SOTA AI/ML is fast-moving, but it’s also increasingly user-friendly, turning cutting-edge science into something you can tangibly experience. The future, it seems, is arriving one breakthrough at a time – and it’s a future where AI will play an ever more creative and powerful role.
References:
- OpenAI – “GPT-4 Technical Report” (Mar 2023), highlights that GPT-4 is a large multimodal model with human-level performance on many benchmarks (GPT-4 | OpenAI).
- Roboflow Blog – “How to Detect Objects with YOLOv8” (Dec 2023), notes that YOLOv8 is a state-of-the-art computer vision model for detection and segmentation (How to Detect Objects with YOLOv8).
- V7 Labs – “Vision Transformer (ViT) Guide” (Dec 2022), explains that Vision Transformer models have begun to outperform state-of-the-art CNNs in image recognition tasks (Vision Transformer: What It Is & How It Works [2024 Guide]).
- Viso.ai – “Foundation Models in Modern AI” (Sep 2024), describes foundation models like GPT-4, BERT, DALL-E 3, etc. as pioneering examples at the forefront of the AI revolution (Foundation Models in Modern AI Development (2025 Guide) - viso.ai).
- Papers With Code – Browse the State of the Art, an online tracker for AI research, listing 12,472 benchmarks and 157,434 papers as of early 2025 (Browse the State-of-the-Art in Machine Learning | Papers With Code), illustrating the rapid growth of SOTA achievements.
- Robots.net – “What Is SOTA in Machine Learning” (2023), discusses the impact of SOTA models, noting that they have revolutionized industries, enabling advancements in diagnosis, recommendation systems, image recognition, speech processing, and more (What Is SOTA In Machine Learning | Robots.net).