
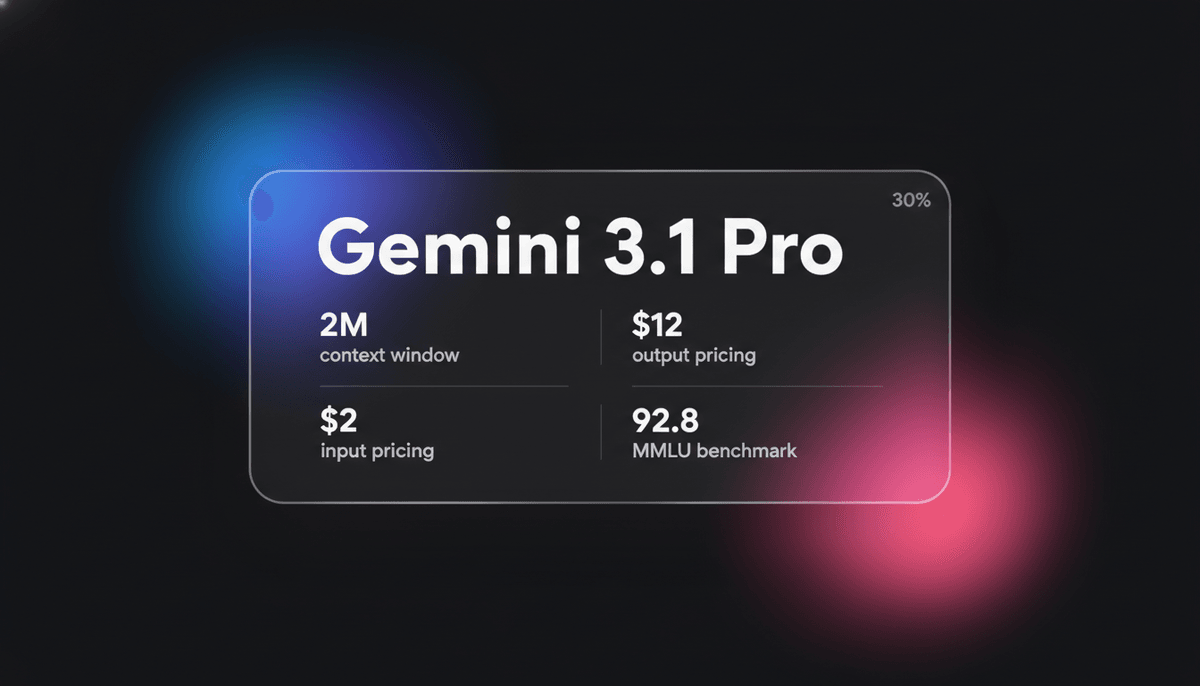
Gemini 3.1 Pro
Gemini 3.1 Pro هو موديل Google الـ multimodal النخبوي الذي يتميز بمحرك DeepThink للـ reasoning، وcontext window يتجاوز 1M، ونتائج منطقية ARC-AGI رائدة في...
حول Gemini 3.1 Pro
تعرف على قدرات Gemini 3.1 Pro والميزات وكيف يمكن أن يساعدك في تحقيق نتائج أفضل.
يمثل Gemini 3.1 Pro تنفيذاً ناضجاً لإطار عمل Sparse Mixture-of-Experts (MoE)، مقترناً بشكل أصلي بمحرك معالجة multimodal متقدم. الميزة البارزة في البنية هي إتاحة طبقة DeepThink System 2، والتي تسمح للموديل بالمداولة داخلياً قبل الالتزام بـ output token. يقدم هذا الموديل نظام تفكير فريداً من ثلاث درجات: منخفضة، ومتوسطة، وعالية، مما يسمح للمطورين بالتحكم الصريح في المقايضة بين الـ latency والتكلفة وعمق الـ reasoning.
بفضل الـ 1-million-token context window الضخم، تم تحسين Gemini 3.1 Pro للغاية لسير العمل المعقد في التمويل وتحليلات البيانات وترحيل الأكواد للمستودعات بأكملها. وهو يظهر قدرة ناشئة على حل أنماط منطقية جديدة، مسجلاً 77.1% غير مسبوقة على benchmark ARC-AGI-2. وهذا يجعله خياراً مفضلاً للمطورين الذين يحتاجون إلى تفاعلات multimodal ذات latency منخفض وأداء معرفي عالٍ لمهام الـ agentic المستقلة.
حالات استخدام Gemini 3.1 Pro
اكتشف الطرق المختلفة لاستخدام Gemini 3.1 Pro لتحقيق نتائج رائعة.
تحليل مستودع الكود بالكامل
استخدام الـ 1M context window لاستيعاب مستودعات برمجية كاملة لإعادة الهيكلة ورسم خرائط التبعية.
لجان الوكلاء المستقلين (Agentic Committees)
إدارة مهام عمل agentic متعددة الخطوات حيث يتناقش الوكلاء الفرعيون الداخليون ويتحققون من الحلول قبل التنفيذ.
توليف البحوث العلمية
تحليل آلاف الأوراق البحثية ومجموعات البيانات المعقدة لاستخراج الذكاء المهيكل والرؤى الواقعية.
إنشاء محتوى متعدد الوسائط
معالجة النصوص والصور والصوت في وقت واحد لتوليد مواد تعليمية معقدة ووسائط تفاعلية.
الأتمتة عبر الواجهة الطرفية (Terminal)
تنفيذ أوامر bash معقدة ومعالجة أنظمة الملفات بدقة عالية عبر أوضاع الـ reasoning المتقدمة.
تدقيق بيانات المؤسسات
تحليل البيانات المالية غير المهيكلة والمستندات القانونية لتحديد فجوات الامتثال باسترجاع واقعي شبه مثالي.
نقاط القوة
القيود
البدء السريع API
google/gemini-3.1-pro-preview
import { GoogleGenAI } from "@google/genai";
const genAI = new GoogleGenAI(process.env.GOOGLE_API_KEY);
const model = genAI.getGenerativeModel({
model: "gemini-3.1-pro-preview",
thinkingConfig: { tier: "high" }
});
const prompt = "Analyze this entire codebase for security vulnerabilities.";
const result = await model.generateContent(prompt);
console.log(result.response.text());ثبت SDK وابدأ في إجراء استدعاءات API في دقائق.
ماذا يقول الناس عن Gemini 3.1 Pro
شاهد رأي المجتمع في Gemini 3.1 Pro
“تمثل نتيجة 77.1% لـ Gemini 3.1 Pro التحول الأكثر اضطراباً في السوق؛ فهي تضاعف أكثر من ضعف الرقم القياسي السابق في ARC-AGI.”
“نتائج الـ benchmarks البرمجية لا تكذب. وجد هذا الموديل خطأً في المستودع الخاص بي فات تماماً على 3.5 و GPT-4o.”
“الضجة حول Gemini 3.1 مثيرة حقاً. لقد حطم الـ benchmarks لكن المستخدمين الحقيقيين يقولون أن النبرة والمزاج غير متسقين.”
“محرك DeepThink يمكن أن يؤدي إلى تأخيرات كبيرة، تصل أحياناً لأكثر من 90 ثانية، عند معالجة المهام التي تتطلب منطقاً عميقاً.”
“الـ context caching هو الميزة القاتلة هنا. أنا أشغل بوت توثيق كامل بملاليم مقارنة بـ GPT-4o.”
“فشل Gemini في مناقشة Python على الإطلاق في مهمة تخطيط معقدة... بعض المنطق لم يكن موجوداً في خطته النهائية.”
فيديوهات عن Gemini 3.1 Pro
شاهد الدروس والمراجعات والنقاشات عن Gemini 3.1 Pro
“Gemini 3.1 Pro يولد أكثر نسخة تفصيلية لهذا المعبد حتى الآن”
“Gemini يمتلك أوسع نافذة سياق بمليون token بفارق كبير”
“دقة الـ multimodal في معالجة الصوت أفضل بشكل ملحوظ من 3.0”
“ثبات الـ throughput للـ tokens يظل مستقراً حتى مع امتلاء الـ context window”
“الاسترجاع طويل المدى مثالي تقريباً عبر كامل المليون token”
“في الألغاز التي لا يجب أن تكون في بيانات تدريبه، يتفوق Gemini 3 على جميع الموديلات الأخرى”
“يمكن لـ 3.1 Pro تقليل وقت تشغيل سكربت الـ fine-tuning من 300 ثانية إلى 47 ثانية”
“خطوات منطق DeepThink واضحة تماماً في التتبع، مما يظهر مداولة حقيقية”
“نصل إلى تشبع الـ benchmark حيث يهم ARC-AGI فقط للتقدم”
“مسار الـ AGI يتسارع بناءً على قفزات الـ reasoning التجريدي هذه”
“أعتقد حقاً أن 3.1 يبدو كخطوة للأمام، حتى لو كانت طفيفة جداً”
“يبدو أنه يتفوق على Gemini 3.0 Pro عندما نختبر نفس الـ prompts جنباً إلى جنب”
“دقة البرمجة في إعادة هيكلة Python المعقدة هي الأعلى التي رأيتها”
“موثوقية الـ API تحسنت بشكل كبير خلال الشهر الماضي من الاختبار”
“الأداء الواقعي يطابق أخيراً ضجيج نتائج الـ benchmark”
عزز سير عملك مع أتمتة الذكاء الاصطناعي
يجمع Automatio بين قوة وكلاء الذكاء الاصطناعي وأتمتة الويب والتكاملات الذكية لمساعدتك على إنجاز المزيد في وقت أقل.
نصائح احترافية لـ Gemini 3.1 Pro
نصائح الخبراء لمساعدتك على تحقيق أقصى استفادة من Gemini 3.1 Pro وتحقيق نتائج أفضل.
اختيار درجة الـ Reasoning
استخدم وضع التفكير العالي (High) للرياضيات أو المنطق المعقد، ولكن انتقل إلى المنخفض (Low) للتنسيق القياسي لتوفير الـ compute.
استخدام Context Caching
قم بتنفيذ context caching للتوثيق الثابت لتقليل أسعار الـ input بنسبة تصل إلى 90% لكل مليون token.
الأدوات المهيكلة (Structured Artifacts)
استفد من قدرة الموديل على توليد قوائم مهام منظمة لتسهيل الإشراف البشري أثناء الـ agentic runs.
الـ Prompting المتعدد الوسائط
اجمع بين مدخلات الفيديو والصوت لمنح الموديل سياقاً كاملاً لسيناريوهات العالم الحقيقي بدلاً من الأوصاف النصية فقط.
الشهادات
ماذا يقول مستخدمونا
انضم إلى الآلاف من المستخدمين الراضين الذين حولوا سير عملهم
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
ذو صلة AI Models
Claude Opus 4.7
Anthropic
Claude Opus 4.7 is Anthropic's flagship model with a 1-million-token context, adaptive reasoning, and 3.3x vision resolution for enterprise-scale agents.
Gemini 3.1 Flash Live Preview
Gemini 3.1 Flash Live Preview is Google's ultra-low-latency, audio-to-audio model featuring a 131K context window, high-fidelity multimodal reasoning, and...
GPT-5.5
OpenAI
GPT-5.5 is OpenAI's flagship frontier model with a 1M context window and five reasoning effort levels, optimized for autonomous agentic workflows and coding.
Grok-3
xAI
Grok-3 is xAI's flagship reasoning model, featuring deep logic deduction, a 128k context window, and real-time integration with X for live research and coding.
Kimi K3
Moonshot
Kimi K3 is Moonshot AI's 2.8T MoE model with a 1M token context window, native multimodal vision, and frontier-tier coding performance for complex agents.
GPT-5.2 Pro
OpenAI
GPT-5.2 Pro is OpenAI's 2025 flagship reasoning model featuring Extended Thinking for SOTA performance in mathematics, coding, and expert knowledge work.
Qwen 3.7 Max
alibaba
Qwen 3.7 Max is Alibaba’s flagship AI model for deep reasoning and autonomous agent tasks, featuring a 256k context window and top-tier coding performance.
Gemini 3 Pro
Google's Gemini 3 Pro is a multimodal powerhouse featuring a 1M token context window, native video processing, and industry-leading reasoning performance.
الأسئلة الشائعة حول Gemini 3.1 Pro
ابحث عن إجابات للأسئلة الشائعة حول Gemini 3.1 Pro