
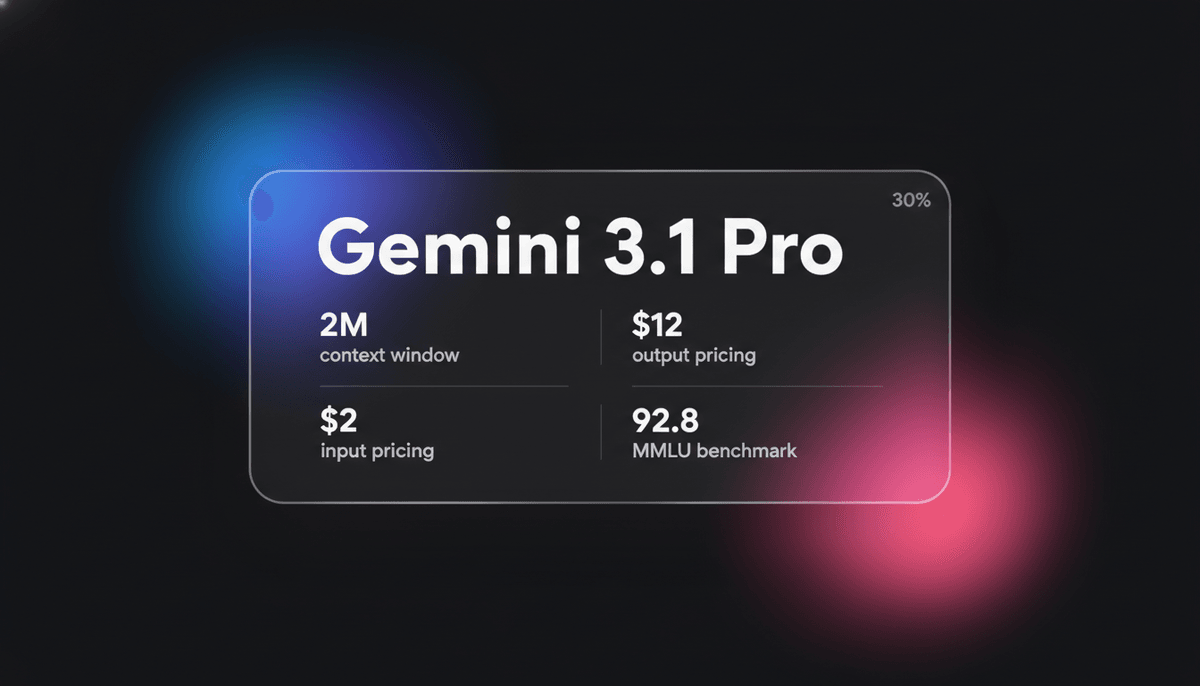
Gemini 3.1 Pro
Gemini 3.1 Pro হলো Google-এর elite multimodal model, যাতে রয়েছে DeepThink reasoning ইঞ্জিন, ১M+ context window এবং ইন্ডাস্ট্রি-লিডিং ARC-AGI লজিক স্কোর।
Gemini 3.1 Pro সম্পর্কে
Gemini 3.1 Pro এর ক্ষমতা, বৈশিষ্ট্য এবং কীভাবে এটি আপনাকে ভালো ফলাফল অর্জন করতে সাহায্য করতে পারে জানুন।
Gemini 3.1 Pro হলো Sparse Mixture-of-Experts (MoE) ফ্রেমওয়ার্কের একটি পরিণত সংস্করণ, যা একটি উন্নত multimodal প্রসেসিং ইঞ্জিনের সাথে যুক্ত। এই আর্কিটেকচারের সবচেয়ে বড় বৈশিষ্ট্য হলো DeepThink System 2 লেয়ার, যা model-টিকে আউটপুট token তৈরির আগে অভ্যন্তরীণভাবে চিন্তাভাবনা করতে দেয়। এটি একটি অনন্য তিন-স্তরের থিংকিং সিস্টেম প্রদান করে (Low, Medium, High), যা ডেভেলপারদের latency, খরচ এবং reasoning-এর গভীরতার মধ্যে ভারসাম্য রক্ষা করতে দেয়।
বিশাল ১-মিলিয়ন-token context window-সহ, Gemini 3.1 Pro ফিন্যান্স, ডেটা অ্যানালিটিক্স এবং পুরো-রিপোজিটরি কোড মাইগ্রেশনের মতো জটিল কাজের জন্য অত্যন্ত অপ্টিমাইজ করা। এটি novel logic pattern সমাধানের ক্ষেত্রে অসাধারণ দক্ষতা প্রদর্শন করে, যা ARC-AGI-২ benchmark-এ ৭৭.১% স্কোর করেছে। এটি সেই সব ডেভেলপারদের জন্য পছন্দের পছন্দ, যারা autonomous agentic কাজের জন্য লো-latency multimodal ইন্টারঅ্যাকশন এবং উচ্চ-স্তরের কগনিটিভ পারফরম্যান্স প্রয়োজন মনে করেন।
Gemini 3.1 Pro এর ব্যবহারের ক্ষেত্র
দুর্দান্ত ফলাফল অর্জন করতে Gemini 3.1 Pro ব্যবহারের বিভিন্ন উপায় আবিষ্কার করুন।
পুরো রিপোজিটরি কোড বিশ্লেষণ
রিফ্যাক্টরিং এবং ডিপেনডেন্সি ম্যাপিংয়ের জন্য ১M context window ব্যবহার করে পুরো সফটওয়্যার রিপোজিটরি ইনজেস্ট করা।
Autonomous Agent কমিটি
এমন multi-step agentic ওয়ার্কফ্লো পরিচালনা করা যেখানে ইন্টারনাল সাব-এজেন্টরা কাজ সম্পাদনের আগে সমাধান নিয়ে বিতর্ক ও যাচাই করে।
বৈজ্ঞানিক গবেষণা সংশ্লেষণ
কাঠামোগত বুদ্ধিমত্তা এবং তথ্যবহুল ইনসাইট বের করার জন্য হাজার হাজার গবেষণাপত্র ও জটিল ডেটাসেট বিশ্লেষণ করা।
Multimodal কন্টেন্ট তৈরি
জটিল ইন্সট্রাকশনাল ম্যাটেরিয়াল এবং ইন্টারঅ্যাক্টিভ মিডিয়া তৈরির জন্য একই সাথে text, image এবং audio প্রসেস করা।
টার্মিনাল-ভিত্তিক অটোমেশন
অ্যাডভান্সড reasoning মোডের মাধ্যমে জটিল bash কমান্ড চালানো এবং ফাইল সিস্টেম ম্যানিপুলেট করা।
এন্টারপ্রাইজ ডেটা অডিটিং
প্রায় নিখুঁত তথ্য পুনরুদ্ধারের সাথে কমপ্লায়েন্সের ঘাটতি শনাক্ত করতে অসংগঠিত আর্থিক ডেটা এবং আইনি নথিপত্র পার্স করা।
শক্তি
সীমাবদ্ধতা
API দ্রুত শুরু
google/gemini-3.1-pro-preview
import { GoogleGenAI } from "@google/genai";
const genAI = new GoogleGenAI(process.env.GOOGLE_API_KEY);
const model = genAI.getGenerativeModel({
model: "gemini-3.1-pro-preview",
thinkingConfig: { tier: "high" }
});
const prompt = "Analyze this entire codebase for security vulnerabilities.";
const result = await model.generateContent(prompt);
console.log(result.response.text());SDK ইনস্টল করুন এবং কয়েক মিনিটের মধ্যে API কল করা শুরু করুন।
Gemini 3.1 Pro সম্পর্কে মানুষ কী বলছে
Gemini 3.1 Pro সম্পর্কে কমিউনিটি কী ভাবছে দেখুন
“Gemini 3.1 Pro-এর ৭৭.১% স্কোর বাজারের সবচেয়ে বড় পরিবর্তন; এটি ARC-AGI-তে আগের সর্বোচ্চ স্কোরকে দ্বিগুণেরও বেশি ছাড়িয়ে গেছে।”
“কোডিং benchmark মিথ্যা বলে না। এই model-টি আমার রিপোজিটরিতে এমন একটি বাগ খুঁজে পেয়েছে যা ৩.৫ এবং GPT-4o ধরতে পারেনি।”
“Gemini ৩.১ বিতর্কটি বেশ আকর্ষণীয়। এটি benchmark চূর্ণ করেছে কিন্তু ব্যবহারকারীরা বলছেন যে টোন এবং ভাব অসামঞ্জস্যপূর্ণ।”
“DeepThink ইঞ্জিন গভীর logic-এর কাজে ৯০ সেকেন্ডের বেশি সময় নিতে পারে।”
“Context caching এখানকার মূল ফিচার। আমি GPT-4o-এর তুলনায় খুব কম খরচে পুরো ডকুমেন্টেশন বট চালাচ্ছি।”
“Gemini একটি জটিল পরিকল্পনা কাজে Python নিয়ে আলোচনা করতে ব্যর্থ হয়েছে... এর চূড়ান্ত পরিকল্পনায় কিছু লজিক একেবারেই ছিল না।”
Gemini 3.1 Pro সম্পর্কে ভিডিও
Gemini 3.1 Pro সম্পর্কে টিউটোরিয়াল, রিভিউ এবং আলোচনা দেখুন
“Gemini 3.1 Pro এখন পর্যন্ত এই প্যাগোডার সবচেয়ে বিস্তারিত সংস্করণ তৈরি করেছে [০২:৪১]”
“Gemini-তে এখন পর্যন্ত সবচেয়ে বড় ১ মিলিয়ন token-এর উইন্ডো রয়েছে [১৫:২১]”
“অডিও প্রসেসিংয়ের ক্ষেত্রে multimodal সক্ষমতা ৩.০-এর চেয়ে লক্ষণীয়ভাবে ভালো [১৮:১০]”
“context window পূর্ণ হয়ে গেলেও token throughput স্থিতিশীল থাকে [২২:০৫]”
“পুরো মিলিয়ন tokens জুড়ে দীর্ঘমেয়াদী recall প্রায় নিখুঁত [৩০:১৫]”
“যেসব ধাঁধা এর ট্রেনিং ডেটায় থাকার কথা নয়, সেগুলোতে Gemini ৩ সিরিজ অন্য সব model-কে ছাড়িয়ে গেছে [০৪:০৩]”
“৩.১ Pro সত্যিই fine-tuning স্ক্রিপ্টের রানটাইম ৩০০ সেকেন্ড থেকে কমিয়ে ৪৭ সেকেন্ড করতে পারে [১০:৪৪]”
“DeepThink লজিক ধাপগুলো ট্রেসে স্পষ্টভাবে দৃশ্যমান, যা প্রকৃত চিন্তাভাবনা প্রকাশ করে [১৪:২২]”
“আমরা benchmark স্যাচুরেশনে পৌঁছে যাচ্ছি যেখানে প্রগতির জন্য শুধু ARC-AGI সত্যিই গুরুত্বপূর্ণ [১৮:৫০]”
“এই abstract reasoning লাফগুলোর ওপর ভিত্তি করে AGI ট্র্যাজেক্টরি ত্বরান্বিত হচ্ছে [২৫:১২]”
“আমার মনে হয় ৩.১ সত্যিই আগের চেয়ে উন্নত, যদিও তা খুব সামান্য [০৮:০১]”
“পাশাপাশি একই প্রম্পট পরীক্ষা করার সময় এটি Gemini ৩.০ Pro-এর চেয়ে ভালো পারফর্ম করছে বলে মনে হয় [০৮:১৪]”
“জটিল Python রিফ্যাক্টরে কোডিং নির্ভুলতা আমার দেখা সবচেয়ে সেরা [১২:৪৫]”
“গত মাসের পরীক্ষার তুলনায় API নির্ভরযোগ্যতা উল্লেখযোগ্যভাবে উন্নত হয়েছে [১৫:৩০]”
“বাস্তব জগতের পারফরম্যান্স শেষ পর্যন্ত benchmark স্কোরের হাইপের সাথে মিলেছে [১৯:১০]”
আপনার ওয়ার্কফ্লো সুপারচার্জ করুন AI অটোমেশন দিয়ে
Automatio AI এজেন্ট, ওয়েব অটোমেশন এবং স্মার্ট ইন্টিগ্রেশনের শক্তি একত্রিত করে আপনাকে কম সময়ে আরও বেশি অর্জন করতে সাহায্য করে।
Gemini 3.1 Pro এর জন্য প্রো টিপস
Gemini 3.1 Pro থেকে সর্বাধিক পেতে এবং ভালো ফলাফল অর্জন করতে বিশেষজ্ঞ টিপস।
Reasoning Tier নির্বাচন
জটিল গণিত বা logic-এর জন্য High thinking mode ব্যবহার করুন, তবে compute বাঁচাতে সাধারণ ফরম্যাটিংয়ের জন্য Low mode-এ সুইচ করুন।
Context Caching
স্ট্যাটিক ডকুমেন্টেশনের জন্য context caching ব্যবহার করুন, যা প্রতি মিলিয়ন tokens-এ ইনপুট খরচ ৯০% পর্যন্ত কমাতে পারে।
Structured Artifacts
agentic রান চলাকালীন মানুষের তত্ত্বাবধান সহজ করতে model-টির structured task list তৈরির ক্ষমতা কাজে লাগান।
Multimodal Prompting
শুধু text বর্ণনার পরিবর্তে, বাস্তব জগতের পরিস্থিতির পূর্ণ context দিতে video এবং audio ইনপুট যুক্ত করুন।
প্রশংসাপত্র
আমাদের ব্যবহারকারীরা কী বলেন
হাজার হাজার সন্তুষ্ট ব্যবহারকারীদের সাথে যোগ দিন যারা তাদের ওয়ার্কফ্লো রূপান্তরিত করেছেন
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
সম্পর্কিত AI Models
Claude Opus 4.7
Anthropic
Claude Opus 4.7 is Anthropic's flagship model with a 1-million-token context, adaptive reasoning, and 3.3x vision resolution for enterprise-scale agents.
Gemini 3.1 Flash Live Preview
Gemini 3.1 Flash Live Preview is Google's ultra-low-latency, audio-to-audio model featuring a 131K context window, high-fidelity multimodal reasoning, and...
GPT-5.5
OpenAI
GPT-5.5 is OpenAI's flagship frontier model with a 1M context window and five reasoning effort levels, optimized for autonomous agentic workflows and coding.
Grok-3
xAI
Grok-3 is xAI's flagship reasoning model, featuring deep logic deduction, a 128k context window, and real-time integration with X for live research and coding.
Kimi K3
Moonshot
Kimi K3 is Moonshot AI's 2.8T MoE model with a 1M token context window, native multimodal vision, and frontier-tier coding performance for complex agents.
GPT-5.2 Pro
OpenAI
GPT-5.2 Pro is OpenAI's 2025 flagship reasoning model featuring Extended Thinking for SOTA performance in mathematics, coding, and expert knowledge work.
Qwen 3.7 Max
alibaba
Qwen 3.7 Max is Alibaba’s flagship AI model for deep reasoning and autonomous agent tasks, featuring a 256k context window and top-tier coding performance.
Gemini 3 Pro
Google's Gemini 3 Pro is a multimodal powerhouse featuring a 1M token context window, native video processing, and industry-leading reasoning performance.
Gemini 3.1 Pro সম্পর্কে সাধারণ প্রশ্নাবলী
Gemini 3.1 Pro সম্পর্কে সাধারণ প্রশ্নের উত্তর খুঁজুন