Jak scrapovat GOV.UK | Průvodce webovým scrapingem britské vlády
Komplexní průvodce scrapováním GOV.UK pro vládní pokyny, aktualizace politik a oficiální statistiky. Naučte se extrahovat vysoce hodnotná data z veřejného...
Detekována anti-bot ochrana
- Omezení rychlosti
- Omezuje požadavky na IP/relaci v čase. Lze obejít rotujícími proxy, zpožděním požadavků a distribuovaným scrapingem.
- User-Agent Filtering
- Blokování IP
- Blokuje známé IP datových center a označené adresy. Vyžaduje rezidenční nebo mobilní proxy pro efektivní obejití.
O GOV.UK
Objevte, co GOV.UK nabízí a jaká cenná data lze extrahovat.
GOV.UK je centrální digitální portál vlády Spojeného království, který poskytuje jednotné přístupové místo ke službám a informacím všech ministerstev a úřadů. Byl vytvořen organizací Government Digital Service (GDS) a nahradil stovky jednotlivých webových stránek úřadů sjednoceným, uživatelsky přívětivým rozhraním navrženým pro transparentnost a efektivitu.
Platforma obsahuje masivní úložiště dat, včetně legislativních pokynů, oficiálních statistik, politických dokumentů a oznámení o veřejných zakázkách. Protože britská vláda uplatňuje politiku 'open data by default', je většina informací na GOV.UK publikována pod licencí Open Government Licence, což z ní činí zlatý důl pro výzkumníky, právní firmy a firmy.
Scrapování GOV.UK je vysoce hodnotné pro monitorování regulačních změn, sledování ekonomických ukazatelů a získávání konkurenčních informací z oznámení o veřejných zakázkách. Organizace tato data využívají k automatizaci procesů dodržování předpisů (compliance) a k udržení náskoku před politickým vývojem, který ovlivňuje jejich odvětví.
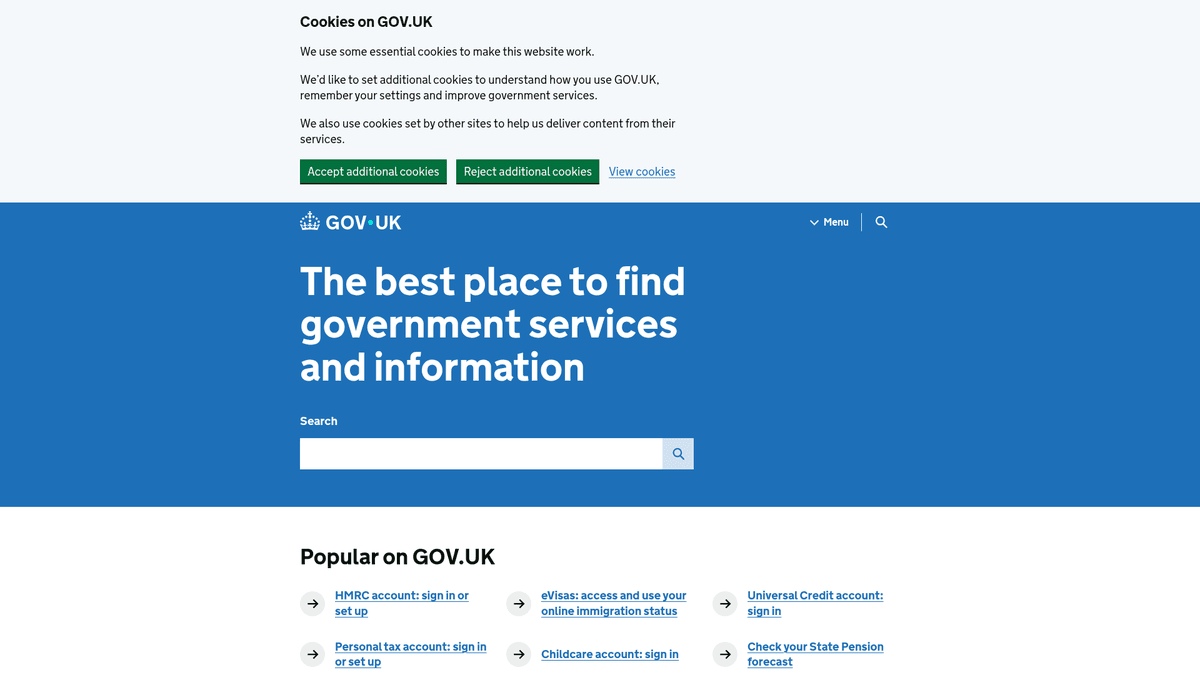
Proč Scrapovat GOV.UK?
Objevte obchodní hodnotu a případy použití pro extrakci dat z GOV.UK.
Monitorování aktualizací souladu s předpisy
Sledování změn politik v reálném čase
Agregace ekonomických a statistických dat
Objevování veřejných zakázek a smluvních příležitostí
Archivace právních a historických dokumentů
Provádění akademického socioekonomického výzkumu
Výzvy Scrapování
Technické výzvy, se kterými se můžete setkat při scrapování GOV.UK.
Hluboce vnořená hierarchická struktura stránek
Vysoký objem dokumentů a PDF příloh
Přísný rate limit 3 000 požadavků za 5 minut
Drobné variace v rozložení mezi různými odděleními
Scrapujte GOV.UK pomocí AI
Žádný kód není potřeba. Extrahujte data během minut s automatizací poháněnou AI.
Jak to funguje
Popište, co potřebujete
Řekněte AI, jaká data chcete extrahovat z GOV.UK. Stačí to napsat přirozeným jazykem — žádný kód ani selektory.
AI extrahuje data
Naše umělá inteligence prochází GOV.UK, zpracovává dynamický obsah a extrahuje přesně to, co jste požadovali.
Získejte svá data
Získejte čistá, strukturovaná data připravená k exportu jako CSV, JSON nebo k odeslání přímo do vašich aplikací.
Proč používat AI pro scrapování
AI usnadňuje scrapování GOV.UK bez psaní kódu. Naše platforma poháněná umělou inteligencí rozumí, jaká data chcete — stačí je popsat přirozeným jazykem a AI je automaticky extrahuje.
How to scrape with AI:
- Popište, co potřebujete: Řekněte AI, jaká data chcete extrahovat z GOV.UK. Stačí to napsat přirozeným jazykem — žádný kód ani selektory.
- AI extrahuje data: Naše umělá inteligence prochází GOV.UK, zpracovává dynamický obsah a extrahuje přesně to, co jste požadovali.
- Získejte svá data: Získejte čistá, strukturovaná data připravená k exportu jako CSV, JSON nebo k odeslání přímo do vašich aplikací.
Why use AI for scraping:
- No-code konfigurace pro složitou navigaci
- Plánované spouštění pro monitorování změn politik
- Přímý export do Google Sheets nebo CSV
- Automatická extrakce skrytých odkazů na dokumenty
No-code webové scrapery pro GOV.UK
Alternativy point-and-click k AI scrapingu
Několik no-code nástrojů jako Browse.ai, Octoparse, Axiom a ParseHub vám může pomoci scrapovat GOV.UK bez psaní kódu. Tyto nástroje obvykle používají vizuální rozhraní pro výběr dat, i když mohou mít problémy se složitým dynamickým obsahem nebo anti-bot opatřeními.
Typický workflow s no-code nástroji
Běžné výzvy
Křivka učení
Pochopení selektorů a logiky extrakce vyžaduje čas
Selektory se rozbijí
Změny webu mohou rozbít celý pracovní postup
Problémy s dynamickým obsahem
Weby s hodně JavaScriptem vyžadují složitá řešení
Omezení CAPTCHA
Většina nástrojů vyžaduje ruční zásah u CAPTCHA
Blokování IP
Agresivní scrapování může vést k zablokování vaší IP
No-code webové scrapery pro GOV.UK
Několik no-code nástrojů jako Browse.ai, Octoparse, Axiom a ParseHub vám může pomoci scrapovat GOV.UK bez psaní kódu. Tyto nástroje obvykle používají vizuální rozhraní pro výběr dat, i když mohou mít problémy se složitým dynamickým obsahem nebo anti-bot opatřeními.
Typický workflow s no-code nástroji
- Nainstalujte rozšíření prohlížeče nebo se zaregistrujte na platformě
- Přejděte na cílový web a otevřete nástroj
- Vyberte datové prvky k extrakci kliknutím
- Nakonfigurujte CSS selektory pro každé datové pole
- Nastavte pravidla stránkování pro scrapování více stránek
- Vyřešte CAPTCHA (často vyžaduje ruční řešení)
- Nakonfigurujte plánování automatických spuštění
- Exportujte data do CSV, JSON nebo připojte přes API
Běžné výzvy
- Křivka učení: Pochopení selektorů a logiky extrakce vyžaduje čas
- Selektory se rozbijí: Změny webu mohou rozbít celý pracovní postup
- Problémy s dynamickým obsahem: Weby s hodně JavaScriptem vyžadují složitá řešení
- Omezení CAPTCHA: Většina nástrojů vyžaduje ruční zásah u CAPTCHA
- Blokování IP: Agresivní scrapování může vést k zablokování vaší IP
Příklady kódu
import requests
from bs4 import BeautifulSoup
# PRO TIP: Připojte .json k mnoha URL adresám GOV.UK pro získání surových dat
url = 'https://www.gov.uk/search/news-and-communications'
headers = {'User-Agent': 'ResearchBot/1.0 (contact@example.com)'}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
for item in soup.select('.gem-c-document-list__item'):
title = item.select_one('.gem-c-document-list__item-title').text.strip()
link = item.select_one('a')['href']
print(f'Aktualizace: {title} | https://www.gov.uk{link}')
except Exception as e:
print(f'Chyba: {e}')Kdy použít
Nejlepší pro statické HTML stránky s minimem JavaScriptu. Ideální pro blogy, zpravodajské weby a jednoduché e-commerce produktové stránky.
Výhody
- ●Nejrychlejší provedení (bez režie prohlížeče)
- ●Nejnižší spotřeba zdrojů
- ●Snadná paralelizace s asyncio
- ●Skvělé pro API a statické stránky
Omezení
- ●Nemůže spustit JavaScript
- ●Selhává na SPA a dynamickém obsahu
- ●Může mít problémy se složitými anti-bot systémy
Jak scrapovat GOV.UK pomocí kódu
Python + Requests
import requests
from bs4 import BeautifulSoup
# PRO TIP: Připojte .json k mnoha URL adresám GOV.UK pro získání surových dat
url = 'https://www.gov.uk/search/news-and-communications'
headers = {'User-Agent': 'ResearchBot/1.0 (contact@example.com)'}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
for item in soup.select('.gem-c-document-list__item'):
title = item.select_one('.gem-c-document-list__item-title').text.strip()
link = item.select_one('a')['href']
print(f'Aktualizace: {title} | https://www.gov.uk{link}')
except Exception as e:
print(f'Chyba: {e}')Python + Playwright
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
try:
page.goto('https://www.gov.uk/search/all?keywords=data+protection')
page.wait_for_selector('.gem-c-document-list__item')
titles = page.locator('.gem-c-document-list__item-title').all_text_contents()
for t in titles:
print(f'Extrahováno: {t.strip()}')
finally:
browser.close()Python + Scrapy
import scrapy
class GovSpider(scrapy.Spider):
name = 'gov_spider'
start_urls = ['https://www.gov.uk/search/news-and-communications']
def parse(self, response):
for article in response.css('.gem-c-document-list__item'):
yield {
'title': article.css('.gem-c-document-list__item-title::text').get().strip(),
'link': response.urljoin(article.css('a::attr(href)').get())
}
next_page = response.css('a[rel="next"]::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
try {
await page.goto('https://www.gov.uk/search/news-and-communications', { waitUntil: 'networkidle2' });
const results = await page.evaluate(() =>
Array.from(document.querySelectorAll('.gem-c-document-list__item-title'))
.map(el => el.innerText.trim())
);
console.log(results);
} finally {
await browser.close();
}
})();Co Můžete Dělat S Daty GOV.UK
Prozkoumejte praktické aplikace a poznatky z dat GOV.UK.
Systém varování před regulačními změnami
Právní týmy a týmy pro compliance mohou sledovat specifické kategorie pokynů a okamžitě detekovat změny zákonů.
Jak implementovat:
- 1Denně scrapujte sekci 'Guidance and Regulation'.
- 2Extrahujte text dokumentu a časová razítka poslední aktualizace.
- 3Porovnejte obsah s předchozími verzemi a zvýrazněte rozdíly (diffs).
- 4Odesílejte automatická upozornění příslušným interním zainteresovaným stranám.
Použijte Automatio k extrakci dat z GOV.UK a vytvoření těchto aplikací bez psaní kódu.
Co Můžete Dělat S Daty GOV.UK
- Systém varování před regulačními změnami
Právní týmy a týmy pro compliance mohou sledovat specifické kategorie pokynů a okamžitě detekovat změny zákonů.
- Denně scrapujte sekci 'Guidance and Regulation'.
- Extrahujte text dokumentu a časová razítka poslední aktualizace.
- Porovnejte obsah s předchozími verzemi a zvýrazněte rozdíly (diffs).
- Odesílejte automatická upozornění příslušným interním zainteresovaným stranám.
- Sledování výběrových řízení
Obchodní týmy mohou scrapovat oznámení o zakázkách a hledat nové příležitosti ve vládních kontraktech.
- Zaměřte se na kategorii vyhledávání 'Procurement' na GOV.UK.
- Scrapujte termíny uzávěrek, kontaktní e-maily a hodnoty zakázek.
- Filtrujte výsledky podle klíčových slov z vašeho obvětví.
- Importujte potenciální zákazníky přímo do CRM pro další kontakt.
- Analýza ekonomických trendů
Ekonomové mohou agregovat statistické publikace pro dlouhodobé studie o výkonnosti Spojeného království.
- Identifikujte URL adresy řad statistických dat.
- Scrapujte přímé odkazy na soubory CSV nebo Excel.
- Stahujte a čistěte datasety pomocí automatizovaných skriptů.
- Slučujte data do centralizované databáze pro vizualizaci.
- Archiv veřejné politiky
Novináři a výzkumníci mohou vytvářet prohledávatelný archiv oficiálních vládních oznámení.
- Průběžně scrapujte sekci 'News and Communications'.
- Extrahujte titulky, texty článků a tagy oddělení.
- Indexujte data v prohledávatelné platformě jako Elasticsearch.
- Analyzujte náladu (sentiment) a frekvenci specifických klíčových slov politik.
- Automatizovaní poradní boti
Neziskové organizace mohou využívat oficiální pokyny k napájení chatbotů, kteří pomáhají občanům najít informace o dávkách.
- Scrapujte stránky s pokyny k dávkám a bydlení.
- Namapujte extrahovaný text do vektorové databáze pro RAG (Retrieval-Augmented Generation).
- Nastavte trigger pro aktualizaci databáze při změně obsahu na GOV.UK.
- Poskytujte přesné odpovědi na dotazy uživatelů v reálném čase.
- Vyhledávač grantových příležitostí
Vzdělávací instituce mohou vyhledávat granty a příležitosti k financování výzkumných projektů.
- Scrapujte kategorii financování 'Education, Training and Skills'.
- Extrahujte kritéria způsobilosti a termíny pro podání žádostí.
- Kategorizujte granty podle oddělení a výše financování.
- Automatizujte týdenní e-mailové přehledy pro členy fakulty.
Zrychlete svuj workflow s AI automatizaci
Automatio kombinuje silu AI agentu, webove automatizace a chytrych integraci, aby vam pomohl dosahnout vice za kratsi cas.
Profesionální Tipy Pro Scrapování GOV.UK
Odborné rady pro úspěšnou extrakci dat z GOV.UK.
Připojte '.json' k téměř jakékoli URL adrese GOV.UK, abyste získali podkladová metadata bez nutnosti parsování HTML.
Identifikujte prvky pomocí CSS tříd začínajících na 'gem-c-', protože jsou součástí standardního GDS Design System.
Nastavte popisný řetězec User-Agent, který obsahuje vaši e-mailovou adresu, aby vás GDS mohl kontaktovat, pokud by váš bot způsoboval problémy.
Dodržujte rate limit 3 000 požadavků za 5 minut, abyste se vyhnuli dočasným zákazům IP adres.
Pro hromadné objevování se zaměřte na stránky 'Search', protože poskytují čisté, stránkované seznamy dokumentů.
Kontrolujte časové razítko 'Last Updated', abyste se vyhnuli opětovnému scrapování nezměněného obsahu.
Reference
Co rikaji nasi uzivatele
Pridejte se k tisicum spokojenych uzivatelu, kteri transformovali svuj workflow
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Souvisejici Web Scraping
Casto kladene dotazy o GOV.UK
Najdete odpovedi na bezne otazky o GOV.UK