Sådan scraper du GOV.UK | Guide til web scraping af den britiske regering
Omfattende guide til scraping af GOV.UK for regeringsvejledning, politikopdateringer og officielle statistikker. Lær at udtrække værdifulde data fra den...
Anti-bot beskyttelse opdaget
- Hastighedsbegrænsning
- Begrænser forespørgsler pr. IP/session over tid. Kan omgås med roterende proxyer, forespørgselsforsinkelser og distribueret scraping.
- User-Agent Filtering
- IP-blokering
- Blokerer kendte datacenter-IP'er og markerede adresser. Kræver bolig- eller mobilproxyer for effektiv omgåelse.
Om GOV.UK
Opdag hvad GOV.UK tilbyder og hvilke værdifulde data der kan udtrækkes.
GOV.UK er den centrale digitale portal for den britiske regering, som giver samlet adgang til tjenester og information fra alle ministerier og styrelser. Den er skabt af Government Digital Service (GDS) og erstattede hundredvis af individuelle styrelsers hjemmesider med en samlet, brugervenlig grænseflade designet til gennemsigtighed og effektivitet.
Platformen indeholder et massivt arkiv af data, herunder lovgivningsmæssig vejledning, officielle statistikker, hvidbøger om politik og udbudsbekendtgørelser. Da den britiske regering følger en politik om 'åbne data som standard', udgives de fleste oplysninger på GOV.UK under Open Government Licence, hvilket gør det til en guldgrube for forskere, advokatfirmaer og virksomheder.
Scraping af GOV.UK er yderst værdifuldt til at overvåge lovgivningsmæssige ændringer, spore økonomiske indikatorer og indsamle konkurrencemæssig efterretning fra offentlige udbudsannonceringer. Organisationer bruger disse data til at automatisere compliance-workflows og være på forkant med politiske udviklinger, der påvirker deres brancher.
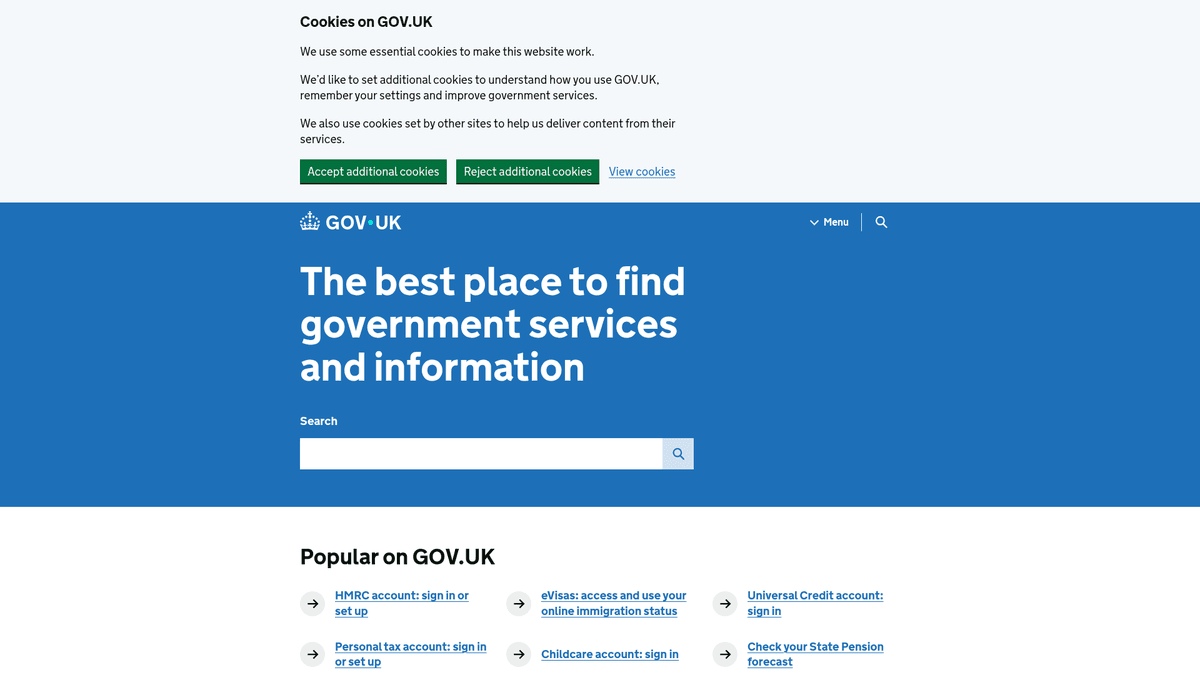
Hvorfor Skrabe GOV.UK?
Opdag forretningsværdien og brugsscenarier for dataudtrækning fra GOV.UK.
Overvåg opdateringer om lovoverholdelse
Spor politikændringer i realtid
Aggregér økonomiske og statistiske data
Opdag offentlige udbuds- og kontraktmuligheder
Arkivér juridiske og historiske dokumenter
Udfør akademisk socioøkonomisk forskning
Skrabningsudfordringer
Tekniske udfordringer du kan støde på når du skraber GOV.UK.
Dybt indlejret hierarkisk sidestruktur
Stor mængde dokumenter og PDF-vedhæftninger
Streng rate limit på 3.000 anmodninger pr. 5 minutter
Mindre layoutvariationer mellem forskellige afdelinger
Skrab GOV.UK med AI
Ingen kode nødvendig. Udtræk data på minutter med AI-drevet automatisering.
Sådan fungerer det
Beskriv hvad du har brug for
Fortæl AI'en hvilke data du vil udtrække fra GOV.UK. Skriv det bare på almindeligt sprog — ingen kode eller selektorer nødvendige.
AI udtrækker dataene
Vores kunstige intelligens navigerer GOV.UK, håndterer dynamisk indhold og udtrækker præcis det du bad om.
Få dine data
Modtag rene, strukturerede data klar til eksport som CSV, JSON eller send direkte til dine apps og workflows.
Hvorfor bruge AI til skrabning
AI gør det nemt at skrabe GOV.UK uden at skrive kode. Vores AI-drevne platform bruger kunstig intelligens til at forstå hvilke data du ønsker — beskriv det på almindeligt sprog, og AI udtrækker dem automatisk.
How to scrape with AI:
- Beskriv hvad du har brug for: Fortæl AI'en hvilke data du vil udtrække fra GOV.UK. Skriv det bare på almindeligt sprog — ingen kode eller selektorer nødvendige.
- AI udtrækker dataene: Vores kunstige intelligens navigerer GOV.UK, håndterer dynamisk indhold og udtrækker præcis det du bad om.
- Få dine data: Modtag rene, strukturerede data klar til eksport som CSV, JSON eller send direkte til dine apps og workflows.
Why use AI for scraping:
- No-code-konfiguration til kompleks navigering
- Planlagte kørsler til overvågning af politikændringer
- Direkte eksport til Google Sheets eller CSV
- Automatisk udtrækning af skjulte dokumentlinks
No-code webscrapere til GOV.UK
Point-and-click alternativer til AI-drevet scraping
Flere no-code værktøjer som Browse.ai, Octoparse, Axiom og ParseHub kan hjælpe dig med at scrape GOV.UK uden at skrive kode. Disse værktøjer bruger typisk visuelle interfaces til at vælge data, selvom de kan have problemer med komplekst dynamisk indhold eller anti-bot foranstaltninger.
Typisk workflow med no-code værktøjer
Almindelige udfordringer
Indlæringskurve
At forstå selektorer og ekstraktionslogik tager tid
Selektorer går i stykker
Webstedsændringer kan ødelægge hele din arbejdsgang
Problemer med dynamisk indhold
JavaScript-tunge sider kræver komplekse løsninger
CAPTCHA-begrænsninger
De fleste værktøjer kræver manuel indgriben for CAPTCHAs
IP-blokering
Aggressiv scraping kan føre til blokering af din IP
No-code webscrapere til GOV.UK
Flere no-code værktøjer som Browse.ai, Octoparse, Axiom og ParseHub kan hjælpe dig med at scrape GOV.UK uden at skrive kode. Disse værktøjer bruger typisk visuelle interfaces til at vælge data, selvom de kan have problemer med komplekst dynamisk indhold eller anti-bot foranstaltninger.
Typisk workflow med no-code værktøjer
- Installer browserudvidelse eller tilmeld dig platformen
- Naviger til målwebstedet og åbn værktøjet
- Vælg dataelementer med point-and-click
- Konfigurer CSS-selektorer for hvert datafelt
- Opsæt pagineringsregler til at scrape flere sider
- Håndter CAPTCHAs (kræver ofte manuel løsning)
- Konfigurer planlægning for automatiske kørsler
- Eksporter data til CSV, JSON eller forbind via API
Almindelige udfordringer
- Indlæringskurve: At forstå selektorer og ekstraktionslogik tager tid
- Selektorer går i stykker: Webstedsændringer kan ødelægge hele din arbejdsgang
- Problemer med dynamisk indhold: JavaScript-tunge sider kræver komplekse løsninger
- CAPTCHA-begrænsninger: De fleste værktøjer kræver manuel indgriben for CAPTCHAs
- IP-blokering: Aggressiv scraping kan føre til blokering af din IP
Kodeeksempler
import requests
from bs4 import BeautifulSoup
# PRO TIP: Tilføj .json til mange GOV.UK-URL'er for rå data
url = 'https://www.gov.uk/search/news-and-communications'
headers = {'User-Agent': 'ResearchBot/1.0 (contact@example.com)'}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
for item in soup.select('.gem-c-document-list__item'):
title = item.select_one('.gem-c-document-list__item-title').text.strip()
link = item.select_one('a')['href']
print(f'Opdatering: {title} | https://www.gov.uk{link}')
except Exception as e:
print(f'Fejl: {e}')Hvornår skal det bruges
Bedst til statiske HTML-sider med minimal JavaScript. Ideel til blogs, nyhedssider og simple e-handelsprodukt sider.
Fordele
- ●Hurtigste udførelse (ingen browser overhead)
- ●Laveste ressourceforbrug
- ●Let at parallelisere med asyncio
- ●Fremragende til API'er og statiske sider
Begrænsninger
- ●Kan ikke køre JavaScript
- ●Fejler på SPA'er og dynamisk indhold
- ●Kan have problemer med komplekse anti-bot systemer
Sådan scraper du GOV.UK med kode
Python + Requests
import requests
from bs4 import BeautifulSoup
# PRO TIP: Tilføj .json til mange GOV.UK-URL'er for rå data
url = 'https://www.gov.uk/search/news-and-communications'
headers = {'User-Agent': 'ResearchBot/1.0 (contact@example.com)'}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
for item in soup.select('.gem-c-document-list__item'):
title = item.select_one('.gem-c-document-list__item-title').text.strip()
link = item.select_one('a')['href']
print(f'Opdatering: {title} | https://www.gov.uk{link}')
except Exception as e:
print(f'Fejl: {e}')Python + Playwright
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
try:
page.goto('https://www.gov.uk/search/all?keywords=data+protection')
page.wait_for_selector('.gem-c-document-list__item')
titles = page.locator('.gem-c-document-list__item-title').all_text_contents()
for t in titles:
print(f'Udtrukket: {t.strip()}')
finally:
browser.close()Python + Scrapy
import scrapy
class GovSpider(scrapy.Spider):
name = 'gov_spider'
start_urls = ['https://www.gov.uk/search/news-and-communications']
def parse(self, response):
for article in response.css('.gem-c-document-list__item'):
yield {
'title': article.css('.gem-c-document-list__item-title::text').get().strip(),
'link': response.urljoin(article.css('a::attr(href)').get())
}
next_page = response.css('a[rel="next"]::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
try {
await page.goto('https://www.gov.uk/search/news-and-communications', { waitUntil: 'networkidle2' });
const results = await page.evaluate(() =>
Array.from(document.querySelectorAll('.gem-c-document-list__item-title'))
.map(el => el.innerText.trim())
);
console.log(results);
} finally {
await browser.close();
}
})();Hvad Du Kan Gøre Med GOV.UK-Data
Udforsk praktiske anvendelser og indsigter fra GOV.UK-data.
Lovgivningsmæssigt varslingssystem
Juridiske og compliance-teams kan overvåge specifikke vejledningskategorier for straks at opdage lovændringer.
Sådan implementeres:
- 1Scrape sektionen 'Guidance and Regulation' dagligt.
- 2Udtræk dokumenttekst og 'last updated'-tidsstempler.
- 3Sammenlign indhold med tidligere versioner for at fremhæve ændringer.
- 4Send automatiserede advarsler til relevante interne interessenter.
Brug Automatio til at udtrække data fra GOV.UK og bygge disse applikationer uden at skrive kode.
Hvad Du Kan Gøre Med GOV.UK-Data
- Lovgivningsmæssigt varslingssystem
Juridiske og compliance-teams kan overvåge specifikke vejledningskategorier for straks at opdage lovændringer.
- Scrape sektionen 'Guidance and Regulation' dagligt.
- Udtræk dokumenttekst og 'last updated'-tidsstempler.
- Sammenlign indhold med tidligere versioner for at fremhæve ændringer.
- Send automatiserede advarsler til relevante interne interessenter.
- Tracker for udbudsmuligheder
Salgsteams kan scrape udbudsbekendtgørelser for at finde nye kontraktmuligheder hos staten.
- Målret søgekategorien 'Procurement' på GOV.UK.
- Scrape deadlines, kontakt-e-mails og kontraktværdier.
- Filtrer resultater efter branche-nøgleord, der er relevante for din virksomhed.
- Importer emner direkte i et CRM til opfølgning.
- Analyse af økonomiske trends
Økonomer kan aggregere statistiske udgivelser til longitudinelle studier af Storbritanniens resultater.
- Identificer URL'er til statistiske dataserier.
- Scrape direkte links til CSV- eller Excel-filer.
- Download og rens datasættene ved hjælp af automatiserede scripts.
- Flet data ind i en centraliseret database til visualisering.
- Arkiv over offentlig politik
Journalister og forskere kan oprette et søgbart arkiv over officielle regeringsmeddelelser.
- Scrape sektionen 'News and Communications' løbende.
- Udtræk overskrifter, brødtekst og tags for afdelinger.
- Indekser dataene på en søgbar platform som Elasticsearch.
- Analyser sentiment og hyppighed af specifikke politiske nøgleord.
- Automatiserede rådgivnings-bots
Non-profit organisationer kan bruge officiel vejledning til at drive chatbots, der hjælper borgere med at finde information om ydelser.
- Scrape sider med vejledning om ydelser og boligforhold.
- Mapp den udtrukne tekst til en vector database til RAG (Retrieval-Augmented Generation).
- Opsæt en trigger til at opdatere databasen, når indholdet på GOV.UK ændres.
- Giv præcise svar i realtid på brugerforespørgsler.
- Søgemaskine til tilskudsmuligheder
Uddannelsesinstitutioner kan finde tilskuds- og finansieringsmuligheder til forskningsprojekter.
- Scrape funding-kategorien 'Education, Training and Skills'.
- Udtræk berettigelseskriterier og ansøgningsfrister.
- Kategoriser tilskud efter afdeling og finansieringsbeløb.
- Automater ugentlige e-mail-resuméer til fakultetsmedlemmer.
Supercharg din arbejdsgang med AI-automatisering
Automatio kombinerer kraften fra AI-agenter, webautomatisering og smarte integrationer for at hjælpe dig med at udrette mere på kortere tid.
Professionelle Tips til Skrabning af GOV.UK
Ekspertråd til succesfuld dataudtrækning fra GOV.UK.
Tilføj '.json' til næsten enhver GOV.UK-URL for at få de underliggende metadata uden HTML-parsing.
Identificer elementer ved hjælp af CSS-klasser, der starter med 'gem-c-', da disse er en del af det standardiserede GDS Design System.
Indstil en beskrivende User-Agent-streng, der inkluderer din e-mailadresse, så GDS kan kontakte dig, hvis din bot skaber problemer.
Hold dig under rate limit på 3.000 anmodninger pr. 5 minutter for at undgå midlertidige IP-blokeringer.
Fokusér på 'Search'-siderne til storstilet dataindsamling, da de giver rene, paginerede lister over dokumenter.
Tjek 'Last Updated'-tidsstemplet for at undgå at scrape uændret indhold igen.
Anmeldelser
Hvad vores brugere siger
Slut dig til tusindvis af tilfredse brugere, der har transformeret deres arbejdsgang
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Relateret Web Scraping
Ofte stillede spørgsmål om GOV.UK
Find svar på almindelige spørgsmål om GOV.UK