
Gemini 3.1 Pro
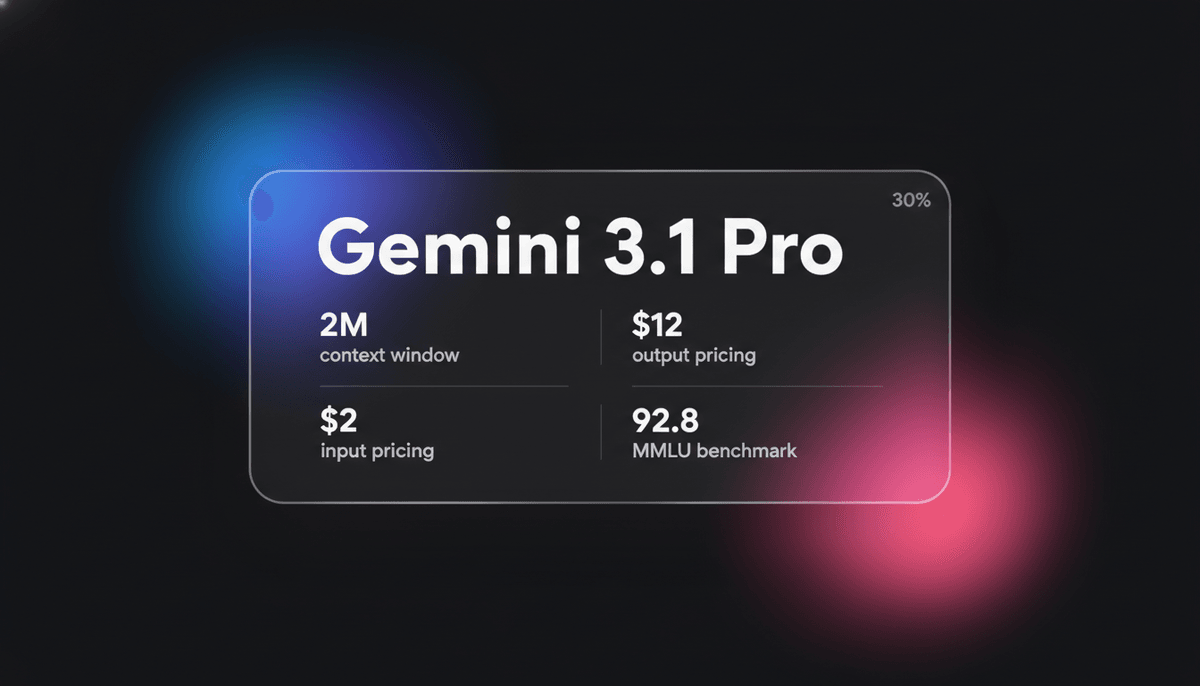
Gemini 3.1 Pro er Googles elitære multimodale model med DeepThink reasoning-motoren, et 1M+ context window og markedsledende ARC-AGI-logikscores.
Om Gemini 3.1 Pro
Lær om Gemini 3.1 Pros muligheder, funktioner og hvordan den kan hjælpe dig med at opnå bedre resultater.
Gemini 3.1 Pro repræsenterer en moden eksekvering af Sparse Mixture-of-Experts (MoE)-frameworket, der er indbygget sammen med en avanceret multimodal behandlingsmotor. Arkitekturens mest fremtrædende egenskab er demokratiseringen af DeepThink System 2-laget, som tillader modellen at overveje internt, før den committer til et output-token. Denne model introducerer et unikt tænkesystem i tre niveauer: Low, Medium og High, hvilket giver udviklere mulighed for eksplicit at styre afvejningen mellem latency, omkostninger og reasoning-dybde.
Med et massivt 1-million-token context window er Gemini 3.1 Pro stærkt optimeret til komplekse workflows inden for finans, dataanalyse og kodeoverførsler af hele repositories. Den demonstrerer en emergent evne til at løse nye logiske mønstre og scorer en hidtil uset 77,1 % på ARC-AGI-2 benchmarken. Dette gør den til et foretrukket valg for udviklere, der kræver både multimodal interaktion med lav latency og kognitiv ydeevne på højt niveau til autonome agentic-opgaver.
Anvendelser for Gemini 3.1 Pro
Opdag de forskellige måder, du kan bruge Gemini 3.1 Pro til at opnå gode resultater.
Kodeanalyse af hele repositories
Udnyttelse af 1M context window til at indlæse hele software-repositories til refaktorering og afhængighedskortlægning.
Autonome agent-komitéer
Styring af agentic-arbejdsgange i flere trin, hvor interne under-agenter debatterer og verificerer løsninger før eksekvering.
Syntese af videnskabelig forskning
Analyse af tusindvis af forskningsartikler og komplekse datasæt for at udtrække struktureret intelligens og faktuel indsigt.
Multimodal indholdsskabelse
Samtidig behandling af tekst, billeder og lyd for at generere komplekst undervisningsmateriale og interaktive medier.
Terminal-baseret automatisering
Eksekvering af komplekse bash-kommandoer og manipulation af filsystemer med høj præcision via avancerede reasoning-tilstande.
Revision af virksomhedsdata
Parsing af ustrukturerede finansielle data og juridiske dokumenter for at identificere compliance-huller med næsten perfekt faktuel genkaldelse.
Styrker
Begrænsninger
API hurtig start
google/gemini-3.1-pro-preview
import { GoogleGenAI } from "@google/genai";
const genAI = new GoogleGenAI(process.env.GOOGLE_API_KEY);
const model = genAI.getGenerativeModel({
model: "gemini-3.1-pro-preview",
thinkingConfig: { tier: "high" }
});
const prompt = "Analyze this entire codebase for security vulnerabilities.";
const result = await model.generateContent(prompt);
console.log(result.response.text());Installér SDK'et og begynd at foretage API-kald på få minutter.
Hvad folk siger om Gemini 3.1 Pro
Se hvad fællesskabet mener om Gemini 3.1 Pro
“Gemini 3.1 Pro's score på 77,1 % repræsenterer det mest forstyrrende markedsskift; det mere end fordobler den tidligere rekord på ARC-AGI.”
“Kodnings-benchmarks lyver ikke. Denne model fandt en fejl i mit repo, som 3.5 og GPT-4o fuldstændigt missede.”
“Gemini 3.1-balladen er virkelig interessant. Den knuste benchmarks, men rigtige brugere siger, at tonen og viben er inkonsekvent.”
“DeepThink-motoren kan føre til betydelige forsinkelser, nogle gange over 90 sekunder, ved behandling af opgaver, der kræver dyb logik.”
“Context caching er dræberfunktionen her. Jeg kører en hel dokumentations-bot for småpenge sammenlignet med GPT-4o.”
“Gemini fejlede i at diskutere Python overhovedet i en kompleks planlægningsopgave... noget logik var bare ikke til stede i dens endelige plan.”
Videoer om Gemini 3.1 Pro
Se vejledninger, anmeldelser og diskussioner om Gemini 3.1 Pro
“Gemini 3.1 Pro genererer den mest detaljerede version af denne pagode indtil videre”
“Gemini har langt det bredeste vindue på en million tokens”
“Den multimodale troskab i lydbehandling er mærkbart bedre end i 3.0”
“Token-gennemstrømningen forbliver stabil, selv når context window fyldes op”
“Genkaldelse på lang sigt er stort set perfekt på tværs af alle en million tokens”
“På gåder, der ikke burde være i dens træningsdata, udkonkurrerer Gemini 3-serien alle andre modeller”
“3.1 Pro kunne faktisk reducere køretiden for et fine-tuning-script fra 300 sekunder til 47 sekunder”
“DeepThink logik-trin er tydeligt synlige i sporingen og viser reel overvejelse”
“Vi når mætningspunktet for benchmarks, hvor kun ARC-AGI virkelig betyder noget for fremskridt”
“AGI-banen accelererer baseret på disse spring i abstrakt reasoning”
“Jeg synes, at 3.1 helt ærligt føles som et skridt op, selvom det er meget lille”
“Den ser ud til at udkonkurrere Gemini 3.0 Pro, når vi tester præcis de samme prompts side om side”
“Kodningspræcision på komplekse Python-refaktoreringer er den højeste, jeg har set”
“API-pålideligheden er forbedret markant over den sidste måneds test”
“Ydeevne i den virkelige verden lever endelig op til hypen fra benchmark-resultaterne”
Supercharg din arbejdsgang med AI-automatisering
Automatio kombinerer kraften fra AI-agenter, webautomatisering og smarte integrationer for at hjælpe dig med at udrette mere på kortere tid.
Pro-tips til Gemini 3.1 Pro
Eksperttips til at hjælpe dig med at få mest muligt ud af Gemini 3.1 Pro og opnå bedre resultater.
Valg af reasoning-niveau
Brug High thinking-tilstand til kompleks matematik eller logik, men skift til Low for standardformatering for at spare på compute.
Context Caching
Implementér context caching for statisk dokumentation for at reducere inputpriser med op til 90 % pr. million tokens.
Strukturerede artefakter
Udnyt modellens evne til at generere strukturerede opgavelister for lettere menneskeligt tilsyn under agentic-kørsler.
Multimodal prompting
Kombinér video- og lydinput for at give modellen fuld kontekst af virkelige scenarier frem for kun tekstbeskrivelser.
Anmeldelser
Hvad vores brugere siger
Slut dig til tusindvis af tilfredse brugere, der har transformeret deres arbejdsgang
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Relateret AI Models
Claude Opus 4.7
Anthropic
Claude Opus 4.7 is Anthropic's flagship model with a 1-million-token context, adaptive reasoning, and 3.3x vision resolution for enterprise-scale agents.
Gemini 3.1 Flash Live Preview
Gemini 3.1 Flash Live Preview is Google's ultra-low-latency, audio-to-audio model featuring a 131K context window, high-fidelity multimodal reasoning, and...
GPT-5.5
OpenAI
GPT-5.5 is OpenAI's flagship frontier model with a 1M context window and five reasoning effort levels, optimized for autonomous agentic workflows and coding.
Grok-3
xAI
Grok-3 is xAI's flagship reasoning model, featuring deep logic deduction, a 128k context window, and real-time integration with X for live research and coding.
Kimi K3
Moonshot
Kimi K3 is Moonshot AI's 2.8T MoE model with a 1M token context window, native multimodal vision, and frontier-tier coding performance for complex agents.
GPT-5.2 Pro
OpenAI
GPT-5.2 Pro is OpenAI's 2025 flagship reasoning model featuring Extended Thinking for SOTA performance in mathematics, coding, and expert knowledge work.
Qwen 3.7 Max
alibaba
Qwen 3.7 Max is Alibaba’s flagship AI model for deep reasoning and autonomous agent tasks, featuring a 256k context window and top-tier coding performance.
Gemini 3 Pro
Google's Gemini 3 Pro is a multimodal powerhouse featuring a 1M token context window, native video processing, and industry-leading reasoning performance.
Ofte stillede spørgsmål om Gemini 3.1 Pro
Find svar på almindelige spørgsmål om Gemini 3.1 Pro