Wie man die California Natural Resources Agency (resources.ca.gov) scrapt
Scrapen Sie Umweltdaten, Förderlisten und staatliche Aufzeichnungen der California Natural Resources Agency. Nutzen Sie die CKAN API oder Python für die...
Anti-Bot-Schutz erkannt
- Rate Limiting
- Begrenzt Anfragen pro IP/Sitzung über Zeit. Kann mit rotierenden Proxys, Anfrageverzögerungen und verteiltem Scraping umgangen werden.
- IP-Blockierung
- Blockiert bekannte Rechenzentrums-IPs und markierte Adressen. Erfordert Residential- oder Mobile-Proxys zur effektiven Umgehung.
- User-Agent Filtering
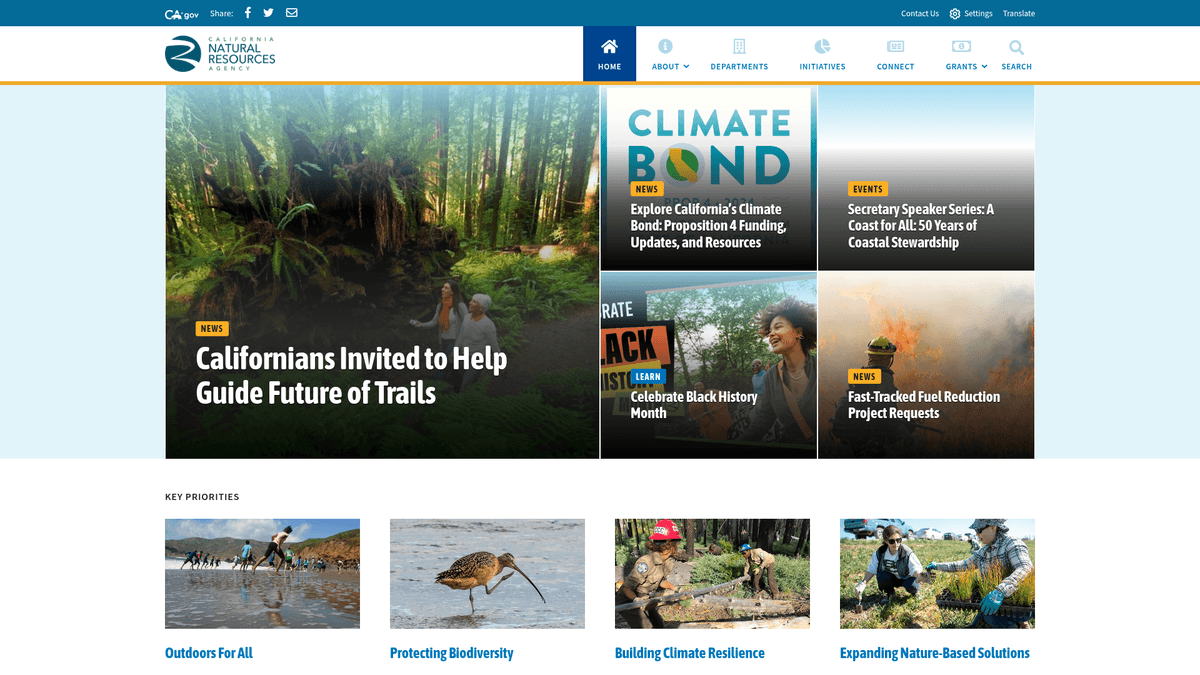
Über California Natural Resources Agency
Entdecken Sie, was California Natural Resources Agency bietet und welche wertvollen Daten extrahiert werden können.
Die California Natural Resources Agency (CNRA) ist eine staatliche Behörde auf Kabinettsebene, die für die Verwaltung und Wiederherstellung der natürlichen, historischen und kulturellen Ressourcen Kaliforniens zuständig ist. Sie beaufsichtigt zahlreiche Abteilungen, darunter Fish and Wildlife, Water Resources sowie Forestry and Fire Protection. Die offizielle Website, resources.ca.gov, dient als primäres Portal für den öffentlichen Zugang zu Umweltrichtlinien, Initiative-Datensätzen und Aufzeichnungen staatlich finanzierter Projekte.
Die auf der Website verfügbaren Daten umfassen Details zu Förderprogrammen, Sitzungsprotokolle und detaillierte Umweltverträglichkeitsberichte. Diese Informationen sind entscheidend für Umweltberater, akademische Forscher und Rechtsexperten, die das Umweltmanagement und die politische Umsetzung auf staatlicher Ebene überwachen müssen. Dieses Portal ist besonders wertvoll für diejenigen, die Kaliforniens ehrgeizige Klimaziele und Biodiversitätsinitiativen verfolgen.
Das Scrapen dieser Daten ermöglicht die Erstellung aggregierter Datenbanken, mit denen langfristige ökologische Trends, Mittelverteilungen und der Status des Umweltschutzes im gesamten Bundesstaat verfolgt werden können. Durch die Automatisierung des Extraktionsprozesses können Benutzer die manuelle Dokumentenprüfung umgehen und groß angelegte Analysen der Ressourcenmanagementstrategien Kaliforniens durchführen.
Warum California Natural Resources Agency Scrapen?
Entdecken Sie den Geschäftswert und die Anwendungsfälle für die Datenextraktion von California Natural Resources Agency.
Finanzierung der Klimaresilienz verfolgen
Überwachen Sie, wie Gelder aus Proposition 4 und andere Klima-Anleihen spezifischen regionalen Projekten in ganz Kalifornien zugewiesen werden.
Umweltverträglichkeitsberichte bündeln
Sammeln Sie Umweltverträglichkeitsberichte (EIRs) verschiedener Abteilungen, um die kumulativen ökologischen Auswirkungen der Infrastruktur auf Bundesstaatsebene zu analysieren.
Förderfähigkeit überwachen
Bleiben Sie über sich ändernde Anforderungen für Zuschüsse für Stammes-naturbasierte Lösungen (Tribal Nature-Based Solutions) und den Ocean Protection Council auf dem Laufenden, um Antragsteller zu unterstützen.
Wassermanagement analysieren
Extrahieren Sie historische und aktuelle Aktualisierungen zu Stauseeständen und Dürrestrategien, um Vorhersagemodelle für die Wasserverfügbarkeit zu erstellen.
Geschäftskontakte identifizieren
Finden Sie staatlich geförderte Restaurierungsprojekte, die spezialisierte Umweltberatung, Ingenieurwesen oder wissenschaftliche Dienstleistungen erfordern.
Historische Archivierung der Politik
Erstellen Sie ein umfassendes digitales Archiv der Ressourcenmanagement-Geschichte Kaliforniens, indem Sie langfristige Publikationslisten und Pressemitteilungen scrapen.
Scraping-Herausforderungen
Technische Herausforderungen beim Scrapen von California Natural Resources Agency.
Komplexes Subdomain-Ökosystem
Die Behörde operiert über Dutzende von Subdomains wie water.ca.gov und parks.ca.gov, jede mit einzigartigen HTML-Architekturen und CSS-Selektoren.
Cloudflare Bot-Management
Es werden fortschrittliche Sicherheitsmaßnahmen implementiert, um automatisierten Datenverkehr zu erkennen und zu blockieren, was ausgefeilte Stealth-Header und Bypass-Techniken erfordert.
Fragmentierte Dokumentenspeicherung
Ein großer Teil der technischen Daten ist in PDF-Dateien eingeschlossen und nicht direkt auf den Seiten verfügbar, was eine mehrstufige Extraktion und PDF-Parsing erfordert.
Asynchrones Laden von Inhalten
Suchschnittstellen für Förderlisten und Datenportale basieren oft auf JavaScript oder AJAX, wodurch statisches HTML-Scraping ineffektiv wird.
Scrape California Natural Resources Agency mit KI
Kein Code erforderlich. Extrahiere Daten in Minuten mit KI-gestützter Automatisierung.
So funktioniert's
Beschreibe, was du brauchst
Sag der KI, welche Daten du von California Natural Resources Agency extrahieren möchtest. Tippe es einfach in natürlicher Sprache ein — kein Code oder Selektoren nötig.
KI extrahiert die Daten
Unsere künstliche Intelligenz navigiert California Natural Resources Agency, verarbeitet dynamische Inhalte und extrahiert genau das, was du angefordert hast.
Erhalte deine Daten
Erhalte saubere, strukturierte Daten, bereit zum Export als CSV, JSON oder zum direkten Senden an deine Apps und Workflows.
Warum KI zum Scraping nutzen
KI macht es einfach, California Natural Resources Agency zu scrapen, ohne Code zu schreiben. Unsere KI-gestützte Plattform nutzt künstliche Intelligenz, um zu verstehen, welche Daten du möchtest — beschreibe es einfach in natürlicher Sprache und die KI extrahiert sie automatisch.
How to scrape with AI:
- Beschreibe, was du brauchst: Sag der KI, welche Daten du von California Natural Resources Agency extrahieren möchtest. Tippe es einfach in natürlicher Sprache ein — kein Code oder Selektoren nötig.
- KI extrahiert die Daten: Unsere künstliche Intelligenz navigiert California Natural Resources Agency, verarbeitet dynamische Inhalte und extrahiert genau das, was du angefordert hast.
- Erhalte deine Daten: Erhalte saubere, strukturierte Daten, bereit zum Export als CSV, JSON oder zum direkten Senden an deine Apps und Workflows.
Why use AI for scraping:
- Integrierter Anti-Bot-Bypass: Automatio übernimmt die komplexe Aufgabe, Cloudflare und Rate-Limits automatisch zu umgehen, ohne dass manuelle Skriptänderungen erforderlich sind.
- Visuelle Datenauswahl: Ordnen Sie Datenfelder über verschiedene Abteilungs-Subdomains hinweg einfach über eine visuelle Schnittstelle zu und passen Sie sich an unterschiedliche Layouts an, ohne Code zu schreiben.
- Natives Sammeln von PDF-Links: Extrahieren und organisieren Sie automatisch Tausende von direkten Download-Links für Umweltberichte in strukturierten Tabellenkalkulationen oder Datenbanken.
- Cloud-basiertes Scheduling: Führen Sie Scraper nach einem wiederkehrenden Zeitplan aus, um neue Förderankündigungen oder Richtlinien-Updates in dem Moment zu erfassen, in dem sie auf dem Portal veröffentlicht werden.
No-Code Web Scraper für California Natural Resources Agency
Point-and-Click-Alternativen zum KI-gestützten Scraping
Verschiedene No-Code-Tools wie Browse.ai, Octoparse, Axiom und ParseHub können Ihnen beim Scrapen von California Natural Resources Agency helfen. Diese Tools verwenden visuelle Oberflächen zur Elementauswahl, haben aber Kompromisse im Vergleich zu KI-gestützten Lösungen.
Typischer Workflow mit No-Code-Tools
Häufige Herausforderungen
Lernkurve
Das Verständnis von Selektoren und Extraktionslogik braucht Zeit
Selektoren brechen
Website-Änderungen können den gesamten Workflow zerstören
Probleme mit dynamischen Inhalten
JavaScript-lastige Seiten erfordern komplexe Workarounds
CAPTCHA-Einschränkungen
Die meisten Tools erfordern manuelle Eingriffe bei CAPTCHAs
IP-Sperrung
Aggressives Scraping kann zur Sperrung Ihrer IP führen
No-Code Web Scraper für California Natural Resources Agency
Verschiedene No-Code-Tools wie Browse.ai, Octoparse, Axiom und ParseHub können Ihnen beim Scrapen von California Natural Resources Agency helfen. Diese Tools verwenden visuelle Oberflächen zur Elementauswahl, haben aber Kompromisse im Vergleich zu KI-gestützten Lösungen.
Typischer Workflow mit No-Code-Tools
- Browser-Erweiterung installieren oder auf der Plattform registrieren
- Zur Zielwebseite navigieren und das Tool öffnen
- Per Point-and-Click die zu extrahierenden Datenelemente auswählen
- CSS-Selektoren für jedes Datenfeld konfigurieren
- Paginierungsregeln zum Scrapen mehrerer Seiten einrichten
- CAPTCHAs lösen (erfordert oft manuelle Eingabe)
- Zeitplanung für automatische Ausführungen konfigurieren
- Daten als CSV, JSON exportieren oder per API verbinden
Häufige Herausforderungen
- Lernkurve: Das Verständnis von Selektoren und Extraktionslogik braucht Zeit
- Selektoren brechen: Website-Änderungen können den gesamten Workflow zerstören
- Probleme mit dynamischen Inhalten: JavaScript-lastige Seiten erfordern komplexe Workarounds
- CAPTCHA-Einschränkungen: Die meisten Tools erfordern manuelle Eingriffe bei CAPTCHAs
- IP-Sperrung: Aggressives Scraping kann zur Sperrung Ihrer IP führen
Code-Beispiele
import requests
from bs4 import BeautifulSoup
# Ziel-URL für den News-Bereich
url = 'https://resources.ca.gov/Newsroom'
headers = {'User-Agent': 'Mozilla/5.0'}
try:
# GET-Anfrage senden
response = requests.get(url, headers=headers)
response.raise_for_status()
# HTML-Inhalt parsen
soup = BeautifulSoup(response.text, 'html.parser')
articles = soup.select('.news-list-item')
for article in articles:
# Headline extrahieren
title = article.find('h3').text.strip()
print(f'News: {title}')
except Exception as e:
print(f'Ein Fehler ist aufgetreten: {e}')Wann verwenden
Am besten für statische HTML-Seiten, bei denen Inhalte serverseitig geladen werden. Der schnellste und einfachste Ansatz, wenn kein JavaScript-Rendering erforderlich ist.
Vorteile
- ●Schnellste Ausführung (kein Browser-Overhead)
- ●Geringster Ressourcenverbrauch
- ●Einfach zu parallelisieren mit asyncio
- ●Ideal für APIs und statische Seiten
Einschränkungen
- ●Kann kein JavaScript ausführen
- ●Scheitert bei SPAs und dynamischen Inhalten
- ●Kann bei komplexen Anti-Bot-Systemen Probleme haben
Wie man California Natural Resources Agency mit Code scrapt
Python + Requests
import requests
from bs4 import BeautifulSoup
# Ziel-URL für den News-Bereich
url = 'https://resources.ca.gov/Newsroom'
headers = {'User-Agent': 'Mozilla/5.0'}
try:
# GET-Anfrage senden
response = requests.get(url, headers=headers)
response.raise_for_status()
# HTML-Inhalt parsen
soup = BeautifulSoup(response.text, 'html.parser')
articles = soup.select('.news-list-item')
for article in articles:
# Headline extrahieren
title = article.find('h3').text.strip()
print(f'News: {title}')
except Exception as e:
print(f'Ein Fehler ist aufgetreten: {e}')Python + Playwright
from playwright.sync_api import sync_playwright
def scrape_grants():
with sync_playwright() as p:
# Starten des Headless-Browsers
browser = p.chromium.launch(headless=True)
page = browser.new_page()
# Navigieren zur Seite mit Fördergeldern
page.goto('https://resources.ca.gov/grants')
# Warten auf das Laden der Inhaltselemente
page.wait_for_selector('.grant-item')
grants = page.query_selector_all('.grant-item')
for grant in grants:
# Titel aus dem Header-Element extrahieren
title = grant.query_selector('h3').inner_text()
print(f'Fördermöglichkeit: {title}')
browser.close()
scrape_grants()Python + Scrapy
import scrapy
class CNRASpider(scrapy.Spider):
name = 'cnra'
start_urls = ['https://resources.ca.gov/Newsroom']
def parse(self, response):
# Loop durch jede News-Artikel-Auflistung
for article in response.css('div.news-list-item'):
yield {
'title': article.css('h3::text').get().strip(),
'link': article.css('a::attr(href)').get()
}
# Einfache Paginierung handhaben, falls ein 'Weiter'-Button existiert
next_page = response.css('a.next::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
// Browser starten und neue Seite öffnen
const browser = await puppeteer.launch();
const page = await browser.newPage();
// Zur 'About Us' Führungsseite navigieren
await page.goto('https://resources.ca.gov/About-Us/Who-We-Are');
// Profildaten der Führungsebene extrahieren
const leadership = await page.evaluate(() => {
return Array.from(document.querySelectorAll('.staff-profile')).map(p => p.innerText.trim());
});
console.log('Behördenleitung:', leadership);
await browser.close();
})();Was Sie mit California Natural Resources Agency-Daten machen können
Entdecken Sie praktische Anwendungen und Erkenntnisse aus California Natural Resources Agency-Daten.
Überwachung staatlicher Fördergelder
Gemeinnützige Umweltorganisationen können die Verteilung staatlicher Mittel verfolgen, um regionalen Bedarf und unterversorgte Gebiete zu identifizieren.
So implementieren Sie es:
- 1Scrapen Sie wöchentlich den Bereich 'Grants' (Förderungen) von resources.ca.gov.
- 2Extrahieren Sie Förderbeträge, Standorte der Empfänger und Projektkategorien.
- 3Geokodieren Sie die Standorte und visualisieren Sie die Daten für eine geografische Gap-Analyse.
Verwenden Sie Automatio, um Daten von California Natural Resources Agency zu extrahieren und diese Anwendungen ohne Code zu erstellen.
Was Sie mit California Natural Resources Agency-Daten machen können
- Überwachung staatlicher Fördergelder
Gemeinnützige Umweltorganisationen können die Verteilung staatlicher Mittel verfolgen, um regionalen Bedarf und unterversorgte Gebiete zu identifizieren.
- Scrapen Sie wöchentlich den Bereich 'Grants' (Förderungen) von resources.ca.gov.
- Extrahieren Sie Förderbeträge, Standorte der Empfänger und Projektkategorien.
- Geokodieren Sie die Standorte und visualisieren Sie die Daten für eine geografische Gap-Analyse.
- Umwelt-Compliance-Index
Beratungsunternehmen können einen suchbaren Index historischer Umweltverträglichkeitsprüfungen für Immobilienrecherchen ihrer Kunden aufbauen.
- Crawlen Sie die Projektseiten der Abteilungen nach Dokumentenlinks.
- Extrahieren Sie PDF-Metadaten und direkte Download-URLs.
- Indexieren Sie den Dokumententext für interne Suchwerkzeuge und Kundenberichte.
- Analyse von Politiktrends
Akademische Forscher können Verschiebungen in den Prioritäten der staatlichen Umweltpolitik analysieren, indem sie Sitzungsprotokolle scrapen.
- Scrapen Sie öffentliche Sitzungsprotokolle und Richtliniendokumente.
- Wenden Sie Natural Language Processing (NLP) an, um wiederkehrende Themen zu identifizieren.
- Korrelieren Sie diese Themen mit Legislaturperioden und Haushaltszyklen.
- Verfolgung von Wasserressourcen
Hydrologen können die Sammlung von Grundwasserstandsdaten für die Modellierung von Dürreauswirkungen automatisieren.
- Greifen Sie auf die CKAN API-Endpunkte des Open-Data-Portals zu.
- Rufen Sie regelmäßige Grundwassermessungen für spezifische kalifornische Countys ab.
- Integrieren Sie die Daten in Zeitreihen-Datenbanken zur Visualisierung.
- Lead-Generierung für Berater
Ingenieurbüros können potenzielle Partner identifizieren, indem sie verfolgen, welche Kommunalverwaltungen staatliche Infrastrukturzuschüsse erhalten.
- Überwachen Sie Bekanntmachungen über Förderzusagen im Newsroom der Behörde.
- Extrahieren Sie Namen der Empfängerorganisationen und Kontaktinformationen.
- Kontaktieren Sie Organisationen für technische Partnerschaftsmöglichkeiten.
Optimieren Sie Ihren Workflow mit KI-Automatisierung
Automatio kombiniert die Kraft von KI-Agenten, Web-Automatisierung und intelligenten Integrationen, um Ihnen zu helfen, mehr in weniger Zeit zu erreichen.
Profi-Tipps für das Scrapen von California Natural Resources Agency
Expertentipps für die erfolgreiche Datenextraktion von California Natural Resources Agency.
CKAN API priorisieren
Prüfen Sie immer zuerst data.cnra.ca.gov, da dort eine strukturierte API für viele Datensätze angeboten wird, was den Bedarf an komplexem HTML-Parsing reduziert.
Nach Abteilungen segmentieren
Erstellen Sie separate Scraper für verschiedene Subdomains wie wildlife.ca.gov, um die spezifischen Layout-Variationen der einzelnen Behörden effektiver zu verwalten.
Residential Proxies nutzen
Nutzen Sie residential proxies, um lokalen Datenverkehr zu simulieren. Dies hilft, IP-Sperren durch die Sicherheitsinfrastruktur auf Bundesstaatsebene bei hochvolumigen Scrapes zu vermeiden.
PDF-Parsing implementieren
Integrieren Sie Ihren Scraper mit einer Bibliothek zur PDF-Textextraktion, um die technischen Daten in den Tausenden von Berichten auf der Website zu erschließen.
Strukturänderungen überwachen
Regierungswebsites werden regelmäßig aktualisiert; richten Sie Monitoring-Alerts ein, um benachrichtigt zu werden, wenn CSS-Selektoren aufgrund eines Layout-Updates fehlschlagen.
Scraping-Frequenz optimieren
Da staatliche Aufzeichnungen und Fördermittel wöchentlich oder monatlich aktualisiert werden, vermeiden Sie aggressives tägliches Scraping, um Ihren Fußabdruck auf den Servern zu minimieren.
Erfahrungsberichte
Was Unsere Nutzer Sagen
Schliessen Sie sich Tausenden zufriedener Nutzer an, die ihren Workflow transformiert haben
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Verwandte Web Scraping
Häufig gestellte Fragen zu California Natural Resources Agency
Finden Sie Antworten auf häufige Fragen zu California Natural Resources Agency