
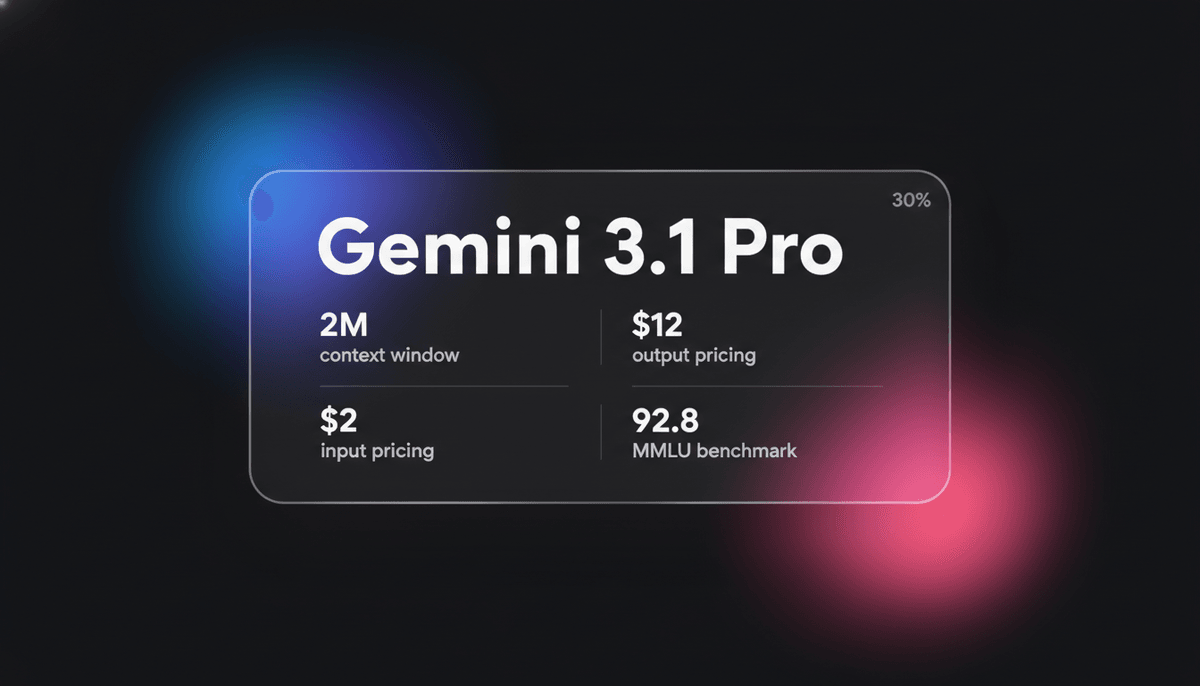
Gemini 3.1 Pro
Το Gemini 3.1 Pro είναι το elite multimodal model της Google με τη μηχανή reasoning DeepThink, context window 1M+ και κορυφαία σκορ λογικής ARC-AGI.
Σχετικά με το Gemini 3.1 Pro
Μάθετε για τις δυνατότητες, τα χαρακτηριστικά του Gemini 3.1 Pro και πώς μπορεί να σας βοηθήσει να επιτύχετε καλύτερα αποτελέσματα.
Το Gemini 3.1 Pro αντιπροσωπεύει μια ώριμη υλοποίηση του framework Sparse Mixture-of-Experts (MoE), συνδυασμένο εγγενώς με μια προηγμένη μηχανή multimodal επεξεργασίας. Το κορυφαίο χαρακτηριστικό της αρχιτεκτονικής είναι εκδημοκρατισμός του DeepThink System 2 layer, το οποίο επιτρέπει στο model να συλλογίζεται εσωτερικά πριν δεσμευτεί σε ένα output token. Αυτό το model εισάγει ένα μοναδικό σύστημα σκέψης τριών επιπέδων (Low, Medium, High), επιτρέποντας στους προγραμματιστές να ελέγχουν ρητά την εξισορρόπηση μεταξύ latency, κόστους και βάθους reasoning.
Με ένα τεράστιο context window 1 εκατομμυρίου tokens, το Gemini 3.1 Pro είναι βελτιστοποιημένο για σύνθετα workflows στα χρηματοοικονομικά, την αναλυτική δεδομένων και τις μετεγκαταστάσεις κώδικα ολόκληρων repositories. Επιδεικνύει μια αναδυόμενη ικανότητα επίλυσης νέων μοτίβων λογικής, σκοράροντας ένα πρωτόγνωρο 77,1% στο benchmark ARC-AGI-2. Αυτό το καθιστά την προτιμώμενη επιλογή για προγραμματιστές που απαιτούν τόσο multimodal αλληλεπιδράσεις χαμηλής latency όσο και γνωστική απόδοση υψηλού επιπέδου για αυτόνομες agentic εργασίες.
Περιπτώσεις χρήσης για Gemini 3.1 Pro
Ανακαλύψτε τους διαφορετικούς τρόπους που μπορείτε να χρησιμοποιήσετε το Gemini 3.1 Pro για εξαιρετικά αποτελέσματα.
Ανάλυση Κώδικα Ολόκληρου Repository
Αξιοποίηση του 1M context window για την εισαγωγή ολόκληρων software repositories για refactoring και χαρτογράφηση εξαρτήσεων.
Επιτροπές Αυτόνομων Agents
Καθοδήγηση agentic workflows πολλαπλών βημάτων όπου εσωτερικοί sub-agents συζητούν και επαληθεύουν λύσεις πριν από την εκτέλεση.
Σύνθεση Επιστημονικής Έρευνας
Ανάλυση χιλιάδων ερευνητικών εργασιών και σύνθετων συνόλων δεδομένων για την εξαγωγή δομημένης ευφυΐας και πραγματικών πληροφοριών.
Multimodal Δημιουργία Περιεχομένου
Ταυτόχρονη επεξεργασία κειμένου, εικόνων και ήχου για τη δημιουργία σύνθετου εκπαιδευτικού υλικού και διαδραστικών μέσων.
Αυτοματοποίηση μέσω Τερματικού
Εκτέλεση σύνθετων bash commands και χειρισμός συστημάτων αρχείων με υψηλή ακρίβεια μέσω προηγμένων reasoning modes.
Έλεγχος Δεδομένων Επιχειρήσεων
Parsing μη δομημένων οικονομικών δεδομένων και νομικών εγγράφων για τον εντοπισμό κενών συμμόρφωσης με σχεδόν τέλεια ανάκληση πληροφοριών.
Δυνατά σημεία
Περιορισμοί
Γρήγορη εκκίνηση API
google/gemini-3.1-pro-preview
import { GoogleGenAI } from "@google/genai";
const genAI = new GoogleGenAI(process.env.GOOGLE_API_KEY);
const model = genAI.getGenerativeModel({
model: "gemini-3.1-pro-preview",
thinkingConfig: { tier: "high" }
});
const prompt = "Analyze this entire codebase for security vulnerabilities.";
const result = await model.generateContent(prompt);
console.log(result.response.text());Εγκαταστήστε το SDK και αρχίστε να κάνετε κλήσεις API σε λίγα λεπτά.
Τι λένε οι άνθρωποι για το Gemini 3.1 Pro
Δείτε τι πιστεύει η κοινότητα για το Gemini 3.1 Pro
“Το σκορ 77,1% του Gemini 3.1 Pro αντιπροσωπεύει τη μεγαλύτερη ανατρεπτική αλλαγή στην αγορά· υπερδιπλασιάζει το προηγούμενο υψηλό στο ARC-AGI.”
“Τα coding benchmarks δεν λένε ψέματα. Αυτό το model βρήκε ένα bug στο repo μου που το 3.5 και το GPT-4o έχασαν εντελώς.”
“Ο χαμός με το Gemini 3.1 είναι πραγματικά ενδιαφέρων. Συνέτριψε τα benchmarks, αλλά οι πραγματικοί χρήστες λένε ότι ο τόνος και το vibe είναι ασυνεπή.”
“Η μηχανή DeepThink μπορεί να οδηγήσει σε σημαντικές καθυστερήσεις, μερικές φορές πάνω από 90 δευτερόλεπτα, κατά την επεξεργασία εργασιών που απαιτούν βαθιά λογική.”
“Το context caching είναι το killer feature εδώ. Τρέχω ένα ολόκληρο documentation bot με ελάχιστα χρήματα σε σύγκριση με το GPT-4o.”
“Το Gemini απέτυχε να συζητήσει καθόλου για Python σε μια σύνθετη εργασία σχεδιασμού... κάποια λογική απλώς δεν υπήρχε στο τελικό του πλάνο.”
Βίντεο για το Gemini 3.1 Pro
Δείτε οδηγούς, κριτικές και συζητήσεις για το Gemini 3.1 Pro
“Το Gemini 3.1 Pro παράγει την πιο λεπτομερή έκδοση αυτής της παγόδας μέχρι στιγμής”
“Το Gemini έχει μακράν το ευρύτερο window του ενός εκατομμυρίου tokens”
“Η multimodal πιστότητα στην επεξεργασία ήχου είναι αισθητά καλύτερη από την 3.0”
“Το throughput των tokens παραμένει σταθερό ακόμη και καθώς γεμίζει το context window”
“Η μακροπρόθεσμη ανάκληση είναι βασικά τέλεια σε ολόκληρο το εκατομμύριο των tokens”
“Σε γρίφους που δεν θα έπρεπε να βρίσκονται στα training data του, η σειρά Gemini 3 υπερέχει όλων των άλλων models”
“Το 3.1 Pro θα μπορούσε πράγματι να μειώσει το χρόνο εκτέλεσης ενός fine-tuning script από 300 δευτερόλεπτα σε 47 δευτερόλεπτα”
“Τα βήματα λογικής του DeepThink είναι σαφώς ορατά στο trace, δείχνοντας πραγματικό προβληματισμό”
“Φτάνουμε σε κορεσμό των benchmarks όπου μόνο το ARC-AGI έχει πραγματικά σημασία για την πρόοδο”
“Η τροχιά προς την AGI επιταχύνεται με βάση αυτά τα άλματα αφηρημένης λογικής”
“Πιστεύω ότι όπως το 3.1, αισθάνεται πραγματικά σαν ένα βήμα προς τα εμπρός, ακόμα κι αν είναι πολύ μικρό”
“Φαίνεται όντως να υπερέχει του Gemini 3.0 Pro όταν δοκιμάζουμε ακριβώς τα ίδια prompts το ένα δίπλα στο άλλο”
“Η ακρίβεια στον κώδικα σε σύνθετα Python refactors είναι η υψηλότερη που έχω δει”
“Η αξιοπιστία του API έχει βελτιωθεί σημαντικά κατά τον τελευταίο μήνα των δοκιμών”
“Η απόδοση στον πραγματικό κόσμο επιτέλους ανταποκρίνεται στο hype των σκορ των benchmarks”
Ενισχύστε τη ροή εργασίας σας με Αυτοματισμό AI
Το Automatio συνδυάζει τη δύναμη των AI agents, του web automation και των έξυπνων ενσωματώσεων για να σας βοηθήσει να επιτύχετε περισσότερα σε λιγότερο χρόνο.
Επαγγελματικές συμβουλές για Gemini 3.1 Pro
Εξειδικευμένες συμβουλές για να αξιοποιήσετε στο έπακρο το Gemini 3.1 Pro και να επιτύχετε καλύτερα αποτελέσματα.
Επιλογή Επιπέδου Reasoning
Χρησιμοποιήστε το High thinking mode για σύνθετα μαθηματικά ή λογική, αλλά μεταβείτε στο Low για τυπική μορφοποίηση ώστε να εξοικονομήσετε compute.
Context Caching
Εφαρμόστε context caching για στατική τεκμηρίωση ώστε να μειώσετε τις τιμές input έως και 90% ανά εκατομμύριο tokens.
Δομημένα Artifacts
Αξιοποιήστε την ικανότητα του model να παράγει δομημένες λίστες εργασιών για ευκολότερη ανθρώπινη επίβλεψη κατά τη διάρκεια agentic runs.
Multimodal Prompting
Συνδυάστε inputs βίντεο και ήχου για να δώσετε στο model πλήρες context πραγματικών σεναρίων αντί για περιγραφές μόνο με κείμενο.
Μαρτυρίες
Τι λένε οι χρήστες μας
Ενταχθείτε στις χιλιάδες ικανοποιημένων χρηστών που έχουν μεταμορφώσει τη ροή εργασίας τους
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Σχετικά AI Models
Claude Opus 4.7
Anthropic
Claude Opus 4.7 is Anthropic's flagship model with a 1-million-token context, adaptive reasoning, and 3.3x vision resolution for enterprise-scale agents.
Gemini 3.1 Flash Live Preview
Gemini 3.1 Flash Live Preview is Google's ultra-low-latency, audio-to-audio model featuring a 131K context window, high-fidelity multimodal reasoning, and...
GPT-5.5
OpenAI
GPT-5.5 is OpenAI's flagship frontier model with a 1M context window and five reasoning effort levels, optimized for autonomous agentic workflows and coding.
Grok-3
xAI
Grok-3 is xAI's flagship reasoning model, featuring deep logic deduction, a 128k context window, and real-time integration with X for live research and coding.
Kimi K3
Moonshot
Kimi K3 is Moonshot AI's 2.8T MoE model with a 1M token context window, native multimodal vision, and frontier-tier coding performance for complex agents.
GPT-5.2 Pro
OpenAI
GPT-5.2 Pro is OpenAI's 2025 flagship reasoning model featuring Extended Thinking for SOTA performance in mathematics, coding, and expert knowledge work.
Qwen 3.7 Max
alibaba
Qwen 3.7 Max is Alibaba’s flagship AI model for deep reasoning and autonomous agent tasks, featuring a 256k context window and top-tier coding performance.
Gemini 3 Pro
Google's Gemini 3 Pro is a multimodal powerhouse featuring a 1M token context window, native video processing, and industry-leading reasoning performance.
Συχνές ερωτήσεις για Gemini 3.1 Pro
Βρείτε απαντήσεις σε συνηθισμένες ερωτήσεις σχετικά με το Gemini 3.1 Pro