
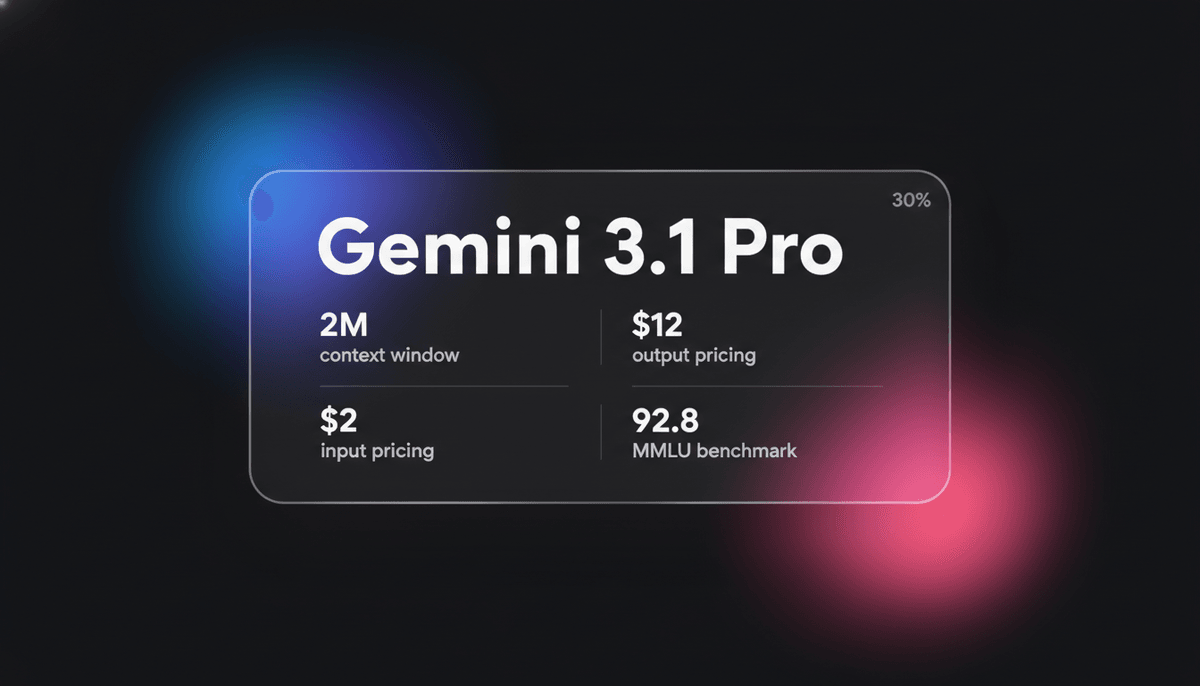
Gemini 3.1 Pro
مدل Gemini 3.1 Pro مدل multimodal برتر گوگل است که دارای موتور reasoning DeepThink، یک context window بیش از ۱ میلیون توکن و امتیازات منطقی پیشگامانه ARC-AGI...
درباره Gemini 3.1 Pro
درباره قابلیتهای Gemini 3.1 Pro، ویژگیها و نحوه کمک به شما در دستیابی به نتایج بهتر بیاموزید.
مدل Gemini 3.1 Pro نشاندهنده اجرای بالغ چارچوب Sparse Mixture-of-Experts (MoE) است که به طور بومی با یک موتور پردازش multimodal پیشرفته جفت شده است. ویژگی برجسته این معماری، دموکراتیزه کردن لایه DeepThink System 2 است که به مدل اجازه میدهد قبل از متعهد شدن به یک خروجی token، به صورت داخلی تأمل کند. این مدل یک سیستم فکری سه سطحی منحصر به فرد (پایین، متوسط و بالا) معرفی میکند که به توسعهدهندگان اجازه میدهد به صراحت تعادل بین latency، هزینه و عمق reasoning را کنترل کنند.
با یک context window یک میلیون توکنی، Gemini 3.1 Pro برای گردشکارهای پیچیده در امور مالی، تحلیل داده و مهاجرتهای کل پایگاهکد بهینهسازی شده است. این مدل توانایی نوظهوری در حل الگوهای منطقی نوین نشان میدهد و امتیاز بیسابقه ۷۷.۱٪ را در benchmark ARC-AGI-2 کسب کرده است. این ویژگیها آن را به انتخابی ارجح برای توسعهدهندگانی تبدیل میکند که به تعاملات multimodal با latency پایین و عملکرد شناختی سطح بالا برای کارهای agentic خودمختار نیاز دارند.
موارد استفاده برای Gemini 3.1 Pro
روشهای مختلف استفاده از Gemini 3.1 Pro برای دستیابی به نتایج عالی را کشف کنید.
تحلیل کل پایگاهکد (Repository)
استفاده از context window یک میلیونی برای وارد کردن کل مخازن نرمافزاری جهت بازنویسی و نگاشت وابستگیها.
کمیتههای Agentic خودمختار
هدایت گردشکارهای agentic چندمرحلهای که در آن زیر-agentهای داخلی قبل از اجرا، درباره راهحلها بحث و آنها را تأیید میکنند.
سنتز تحقیقات علمی
تحلیل هزاران مقاله پژوهشی و مجموعهدادههای پیچیده برای استخراج هوش ساختاریافته و بینشهای واقعی.
تولید محتوای Multimodal
پردازش همزمان متن، تصویر و صوت برای تولید مواد آموزشی پیچیده و رسانههای تعاملی.
اتوماسیون مبتنی بر ترمینال
اجرای دستورات bash پیچیده و دستکاری سیستمهای فایل با دقت بالا از طریق حالتهای reasoning پیشرفته.
حسابرسی دادههای سازمانی
تجزیه دادههای مالی بدون ساختار و اسناد حقوقی برای شناسایی شکافهای انطباق با فراخوانی دادههای بسیار دقیق.
نقاط قوت
محدودیتها
شروع سریع API
google/gemini-3.1-pro-preview
import { GoogleGenAI } from "@google/genai";
const genAI = new GoogleGenAI(process.env.GOOGLE_API_KEY);
const model = genAI.getGenerativeModel({
model: "gemini-3.1-pro-preview",
thinkingConfig: { tier: "high" }
});
const prompt = "Analyze this entire codebase for security vulnerabilities.";
const result = await model.generateContent(prompt);
console.log(result.response.text());SDK را نصب کنید و در عرض چند دقیقه شروع به فراخوانی API کنید.
مردم درباره Gemini 3.1 Pro چه میگویند
ببینید جامعه درباره Gemini 3.1 Pro چه فکر میکند
“امتیاز ۷۷.۱٪ مدل Gemini 3.1 Pro نشاندهنده مخربترین تغییر بازار است؛ این امتیاز رکورد قبلی در ARC-AGI را بیش از دو برابر میکند.”
“benchmarkهای کدنویسی دروغ نمیگویند. این مدل باگی را در مخزن من پیدا کرد که 3.5 و GPT-4o کاملاً از قلم انداخته بودند.”
“جنجال پیرامون gemini 3.1 واقعاً جالب است. این مدل benchmarkها را له کرد اما کاربران واقعی میگویند لحن و حس آن متناقض است.”
“موتور DeepThink میتواند منجر به تأخیرهای قابل توجهی شود، گاهی اوقات بیش از ۹۰ ثانیه، زمانی که کارهای نیازمند منطق عمیق را پردازش میکند.”
“Context caching ویژگی اصلی و فوقالعاده این مدل است. من یک بات کامل مستندات را با هزینهای ناچیز نسبت به GPT-4o اجرا میکنم.”
“Gemini در یک کار برنامهریزی پیچیده اصلاً در مورد Python بحث نکرد... بخشی از منطق در برنامه نهایی آن وجود نداشت.”
ویدیوهای درباره Gemini 3.1 Pro
آموزشها، بررسیها و بحثهای درباره Gemini 3.1 Pro را تماشا کنید
“Gemini 3.1 Pro دقیقترین نسخه از این پاگودا را تاکنون تولید میکند”
“Gemini تا کنون وسیعترین پنجره یک میلیون توکنی را دارد”
“دقت multimodal در پردازش صوتی به وضوح بهتر از 3.0 است”
“توان عملیاتی توکن (throughput) حتی با پر شدن context window ثابت میماند”
“فراخوانی طولانیمدت در کل یک میلیون توکن اساساً بینقص است”
“در پازلهایی که نباید در دادههای آموزشیاش باشند، سری Gemini 3 از تمام مدلهای دیگر بهتر عمل میکند”
“3.1 Pro میتواند زمان اجرای یک اسکریپت fine-tuning را از ۳۰۰ ثانیه به ۴۷ ثانیه کاهش دهد”
“مراحل منطقی DeepThink به وضوح در ردپا قابل مشاهده هستند که نشاندهنده تأمل واقعی است”
“ما در حال رسیدن به اشباع benchmark هستیم که در آن فقط ARC-AGI واقعاً برای پیشرفت مهم است”
“مسیر AGI بر اساس این جهشهای reasoning انتزاعی در حال شتاب گرفتن است”
“به نظرم 3.1 واقعاً حس یک ارتقا را میدهد، حتی اگر خیلی جزئی باشد”
“به نظر میرسد وقتی دقیقاً همان promptها را در کنار هم تست میکنیم، از Gemini 3.0 Pro بهتر عمل میکند”
“دقت کدنویسی در بازنویسیهای پیچیده Python بالاترین چیزی است که تا به حال دیدهام”
“قابلیت اطمینان API در ماه گذشته تستها به طور قابل توجهی بهبود یافته است”
“عملکرد در دنیای واقعی بالاخره با هیاهوی امتیازات benchmark مطابقت پیدا کرد”
گردش کار خود را با اتوماسیون AI
Automatio قدرت عاملهای AI، اتوماسیون وب و ادغامهای هوشمند را ترکیب میکند تا به شما کمک کند در زمان کمتر بیشتر انجام دهید.
نکات حرفهای برای Gemini 3.1 Pro
نکات تخصصی برای کمک به شما در استفاده حداکثری از Gemini 3.1 Pro و دستیابی به نتایج بهتر.
انتخاب سطح Reasoning
برای محاسبات پیچیده یا منطق، از حالت thinking بالا (High) استفاده کنید، اما برای قالببندی استاندارد جهت صرفهجویی در compute، آن را روی پایین (Low) قرار دهید.
Context Caching
برای مستندات ثابت، context caching را پیادهسازی کنید تا هزینههای ورودی را تا ۹۰٪ به ازای هر میلیون token کاهش دهید.
Artifacts ساختاریافته
از توانایی مدل در تولید لیستهای وظایف ساختاریافته استفاده کنید تا نظارت انسانی در طول اجرای agentic آسانتر شود.
Prompting چندوجهی (Multimodal)
ورودیهای ویدیویی و صوتی را ترکیب کنید تا به جای توصیفات متنی صرف، زمینه کاملتری از سناریوهای دنیای واقعی به مدل بدهید.
نظرات
کاربران ما چه میگویند
به هزاران کاربر راضی که گردش کار خود را متحول کردهاند بپیوندید
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
مرتبط AI Models
Claude Opus 4.7
Anthropic
Claude Opus 4.7 is Anthropic's flagship model with a 1-million-token context, adaptive reasoning, and 3.3x vision resolution for enterprise-scale agents.
Gemini 3.1 Flash Live Preview
Gemini 3.1 Flash Live Preview is Google's ultra-low-latency, audio-to-audio model featuring a 131K context window, high-fidelity multimodal reasoning, and...
GPT-5.5
OpenAI
GPT-5.5 is OpenAI's flagship frontier model with a 1M context window and five reasoning effort levels, optimized for autonomous agentic workflows and coding.
Grok-3
xAI
Grok-3 is xAI's flagship reasoning model, featuring deep logic deduction, a 128k context window, and real-time integration with X for live research and coding.
Kimi K3
Moonshot
Kimi K3 is Moonshot AI's 2.8T MoE model with a 1M token context window, native multimodal vision, and frontier-tier coding performance for complex agents.
GPT-5.2 Pro
OpenAI
GPT-5.2 Pro is OpenAI's 2025 flagship reasoning model featuring Extended Thinking for SOTA performance in mathematics, coding, and expert knowledge work.
Qwen 3.7 Max
alibaba
Qwen 3.7 Max is Alibaba’s flagship AI model for deep reasoning and autonomous agent tasks, featuring a 256k context window and top-tier coding performance.
Gemini 3 Pro
Google's Gemini 3 Pro is a multimodal powerhouse featuring a 1M token context window, native video processing, and industry-leading reasoning performance.
سوالات متداول درباره Gemini 3.1 Pro
پاسخ سوالات رایج درباره Gemini 3.1 Pro را بیابید