Comment scraper GOV.UK | Guide d'extraction de données du gouvernement britannique
Guide complet sur le scraping de GOV.UK pour les directives gouvernementales, les mises à jour de politiques et les statistiques officielles. Apprenez à...
Protection Anti-Bot Détectée
- Limitation de débit
- Limite les requêtes par IP/session dans le temps. Peut être contourné avec des proxys rotatifs, des délais de requête et du scraping distribué.
- User-Agent Filtering
- Blocage IP
- Bloque les IP de centres de données connues et les adresses signalées. Nécessite des proxys résidentiels ou mobiles pour contourner efficacement.
À Propos de GOV.UK
Découvrez ce que GOV.UK offre et quelles données précieuses peuvent être extraites.
GOV.UK est le portail numérique central du gouvernement du Royaume-Uni, offrant un point d'accès unique aux services et aux informations de tous les ministères et agences. Créé par le Government Digital Service (GDS), il a remplacé des centaines de sites d'agences individuelles par une interface unifiée et conviviale conçue pour la transparence et l'efficacité.
La plateforme contient un immense dépôt de données, notamment des guides législatifs, des statistiques officielles, des livres blancs politiques et des avis de marchés publics. Étant donné que le gouvernement britannique suit une politique de 'données ouvertes par défaut', la plupart des informations sur GOV.UK sont publiées sous la Open Government Licence, ce qui en fait une mine d'or pour les chercheurs, les cabinets juridiques et les entreprises.
Le scraping de GOV.UK est extrêmement précieux pour surveiller les changements réglementaires, suivre les indicateurs économiques et recueillir des renseignements concurrentiels à partir des annonces d'appels d'offres publics. Les organisations utilisent ces données pour automatiser les flux de travail de conformité et anticiper les développements politiques qui impactent leurs secteurs.
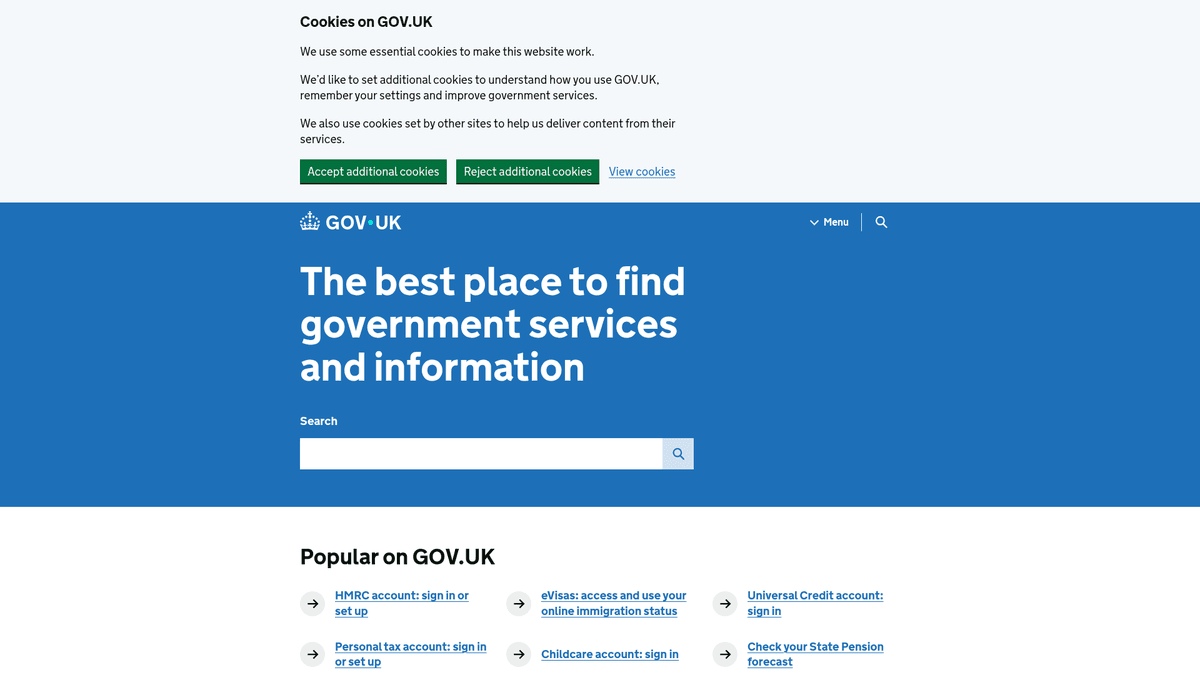
Pourquoi Scraper GOV.UK?
Découvrez la valeur commerciale et les cas d'utilisation pour l'extraction de données de GOV.UK.
Analyse du marché des marchés publics
Analysez plus de 600 000 contrats gouvernementaux pour identifier les tendances de dépenses, les demandes de services de niche et les cycles de financement dans les conseils locaux et les organismes nationaux.
Audit de conformité des entreprises (Due Diligence)
Extrayez les données de Companies House pour vérifier le statut des entreprises, l'historique des administrateurs et les personnes exerçant un contrôle significatif pour l'évaluation des risques et la conformité AML.
Génération de leads pour le B2G
Identifiez les entreprises qui ont récemment remporté des appels d'offres gouvernementaux pour proposer des services de sous-traitance ou des solutions compétitives.
Recherche économique et sociale
Accédez aux registres publics sur les prestations sociales, les statistiques de la criminalité et les tendances de l'emploi pour élaborer des modèles économiques complets ou des rapports d'impact social.
Données historiques de véhicules
Scrapez l'historique du MOT et du kilométrage pour créer des outils d'évaluation automobile ou vérifier l'état des véhicules pour les marchés de l'occasion.
Défis du Scraping
Défis techniques que vous pouvez rencontrer lors du scraping de GOV.UK.
Fragmentation des données
Les informations sont réparties sur divers sous-services comme Companies House et Find a Tender, chacun ayant des structures d'URL et des schémas HTML différents.
Rate Limiting et Anti-Bot
Gov.uk utilise Cloudflare et un rate limiting agressif sur certains points de terminaison de recherche, ce qui peut entraîner des blocages d'IP temporaires si la vitesse de scraping est trop élevée.
Mises à jour structurelles fréquentes
Le site est continuellement mis à jour par divers départements, ce qui signifie que les sélecteurs pour les valeurs de contrat ou les détails d'entreprise peuvent ne plus fonctionner et nécessiter une maintenance régulière.
Volume de données
Avec des centaines de milliers d'annonces actives et des millions d'archives historiques, la gestion de la profondeur de crawl et du stockage des données nécessite une infrastructure robuste.
Scrapez GOV.UK avec l'IA
Aucun code requis. Extrayez des données en minutes avec l'automatisation par IA.
Comment ça marche
Décrivez ce dont vous avez besoin
Dites à l'IA quelles données vous souhaitez extraire de GOV.UK. Tapez simplement en langage naturel — pas de code ni de sélecteurs.
L'IA extrait les données
Notre intelligence artificielle navigue sur GOV.UK, gère le contenu dynamique et extrait exactement ce que vous avez demandé.
Obtenez vos données
Recevez des données propres et structurées, prêtes à exporter en CSV, JSON ou à envoyer directement à vos applications.
Pourquoi utiliser l'IA pour le scraping
L'IA facilite le scraping de GOV.UK sans écrire de code. Notre plateforme alimentée par l'intelligence artificielle comprend quelles données vous voulez — décrivez-les en langage naturel et l'IA les extrait automatiquement.
How to scrape with AI:
- Décrivez ce dont vous avez besoin: Dites à l'IA quelles données vous souhaitez extraire de GOV.UK. Tapez simplement en langage naturel — pas de code ni de sélecteurs.
- L'IA extrait les données: Notre intelligence artificielle navigue sur GOV.UK, gère le contenu dynamique et extrait exactement ce que vous avez demandé.
- Obtenez vos données: Recevez des données propres et structurées, prêtes à exporter en CSV, JSON ou à envoyer directement à vos applications.
Why use AI for scraping:
- Gestion du contenu dynamique: Automatio navigue facilement à travers les filtres de recherche complexes et les tableaux interactifs riches en JavaScript sans écrire de code.
- Pagination automatique: Gérez de manière transparente les boutons 'Suivant' et la pagination numérotée sur des milliers de pages de résultats de recherche pour les avis de marché.
- Contournement des protections: Des fonctionnalités intégrées aident à gérer les en-têtes de requête et les empreintes numériques (fingerprints) pour naviguer plus efficacement sur les sites protégés par Cloudflare.
- Surveillance planifiée: Configurez des scrapers pour qu'ils s'exécutent quotidiennement et capturent les nouveaux avis d'appel d'offres ou les mises à jour de dépôts de sociétés dès leur publication.
- Exportation de données structurées: Transformez un HTML désordonné en formats JSON ou CSV propres, les rendant immédiatement prêts pour une intégration dans des outils de CRM ou de BI.
Scrapers Web No-Code pour GOV.UK
Alternatives pointer-cliquer au scraping alimenté par l'IA
Plusieurs outils no-code comme Browse.ai, Octoparse, Axiom et ParseHub peuvent vous aider à scraper GOV.UK sans écrire de code. Ces outils utilisent généralement des interfaces visuelles pour sélectionner les données, bien qu'ils puissent avoir des difficultés avec le contenu dynamique complexe ou les mesures anti-bot.
Workflow Typique avec les Outils No-Code
Défis Courants
Courbe d'apprentissage
Comprendre les sélecteurs et la logique d'extraction prend du temps
Les sélecteurs cassent
Les modifications du site web peuvent casser tout le workflow
Problèmes de contenu dynamique
Les sites riches en JavaScript nécessitent des solutions complexes
Limitations des CAPTCHAs
La plupart des outils nécessitent une intervention manuelle pour les CAPTCHAs
Blocage d'IP
Le scraping agressif peut entraîner le blocage de votre IP
Scrapers Web No-Code pour GOV.UK
Plusieurs outils no-code comme Browse.ai, Octoparse, Axiom et ParseHub peuvent vous aider à scraper GOV.UK sans écrire de code. Ces outils utilisent généralement des interfaces visuelles pour sélectionner les données, bien qu'ils puissent avoir des difficultés avec le contenu dynamique complexe ou les mesures anti-bot.
Workflow Typique avec les Outils No-Code
- Installer l'extension de navigateur ou s'inscrire sur la plateforme
- Naviguer vers le site web cible et ouvrir l'outil
- Sélectionner en point-and-click les éléments de données à extraire
- Configurer les sélecteurs CSS pour chaque champ de données
- Configurer les règles de pagination pour scraper plusieurs pages
- Gérer les CAPTCHAs (nécessite souvent une résolution manuelle)
- Configurer la planification pour les exécutions automatiques
- Exporter les données en CSV, JSON ou se connecter via API
Défis Courants
- Courbe d'apprentissage: Comprendre les sélecteurs et la logique d'extraction prend du temps
- Les sélecteurs cassent: Les modifications du site web peuvent casser tout le workflow
- Problèmes de contenu dynamique: Les sites riches en JavaScript nécessitent des solutions complexes
- Limitations des CAPTCHAs: La plupart des outils nécessitent une intervention manuelle pour les CAPTCHAs
- Blocage d'IP: Le scraping agressif peut entraîner le blocage de votre IP
Exemples de Code
import requests
from bs4 import BeautifulSoup
# CONSEIL PRO : Ajoutez .json aux URL GOV.UK pour obtenir des données brutes
url = 'https://www.gov.uk/search/news-and-communications'
headers = {'User-Agent': 'ResearchBot/1.0 (contact@example.com)'}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
for item in soup.select('.gem-c-document-list__item'):
title = item.select_one('.gem-c-document-list__item-title').text.strip()
link = item.select_one('a')['href']
print(f'Mise à jour : {title} | https://www.gov.uk{link}')
except Exception as e:
print(f'Erreur : {e}')Quand Utiliser
Idéal pour les pages HTML statiques avec peu de JavaScript. Parfait pour les blogs, sites d'actualités et pages e-commerce simples.
Avantages
- ●Exécution la plus rapide (sans surcharge navigateur)
- ●Consommation de ressources minimale
- ●Facile à paralléliser avec asyncio
- ●Excellent pour les APIs et pages statiques
Limitations
- ●Ne peut pas exécuter JavaScript
- ●Échoue sur les SPAs et contenu dynamique
- ●Peut avoir des difficultés avec les systèmes anti-bot complexes
Comment Scraper GOV.UK avec du Code
Python + Requests
import requests
from bs4 import BeautifulSoup
# CONSEIL PRO : Ajoutez .json aux URL GOV.UK pour obtenir des données brutes
url = 'https://www.gov.uk/search/news-and-communications'
headers = {'User-Agent': 'ResearchBot/1.0 (contact@example.com)'}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
for item in soup.select('.gem-c-document-list__item'):
title = item.select_one('.gem-c-document-list__item-title').text.strip()
link = item.select_one('a')['href']
print(f'Mise à jour : {title} | https://www.gov.uk{link}')
except Exception as e:
print(f'Erreur : {e}')Python + Playwright
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
try:
page.goto('https://www.gov.uk/search/all?keywords=data+protection')
page.wait_for_selector('.gem-c-document-list__item')
titles = page.locator('.gem-c-document-list__item-title').all_text_contents()
for t in titles:
print(f'Extrait : {t.strip()}')
finally:
browser.close()Python + Scrapy
import scrapy
class GovSpider(scrapy.Spider):
name = 'gov_spider'
start_urls = ['https://www.gov.uk/search/news-and-communications']
def parse(self, response):
for article in response.css('.gem-c-document-list__item'):
yield {
'title': article.css('.gem-c-document-list__item-title::text').get().strip(),
'link': response.urljoin(article.css('a::attr(href)').get())
}
next_page = response.css('a[rel="next"]::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
try {
await page.goto('https://www.gov.uk/search/news-and-communications', { waitUntil: 'networkidle2' });
const results = await page.evaluate(() =>
Array.from(document.querySelectorAll('.gem-c-document-list__item-title'))
.map(el => el.innerText.trim())
);
console.log(results);
} finally {
await browser.close();
}
})();Que Pouvez-Vous Faire Avec Les Données de GOV.UK
Explorez les applications pratiques et les insights des données de GOV.UK.
Système d'alerte réglementaire
Les équipes juridiques et de conformité peuvent surveiller des catégories de guides spécifiques pour détecter immédiatement les changements de loi.
Comment implémenter :
- 1Scraper quotidiennement la section 'Guidance and Regulation'.
- 2Extraire le texte des documents et les horodatages de dernière mise à jour.
- 3Comparer le contenu avec les versions précédentes pour mettre en évidence les différences.
- 4Envoyer des alertes automatisées aux parties prenantes internes concernées.
Utilisez Automatio pour extraire des données de GOV.UK et créer ces applications sans écrire de code.
Que Pouvez-Vous Faire Avec Les Données de GOV.UK
- Système d'alerte réglementaire
Les équipes juridiques et de conformité peuvent surveiller des catégories de guides spécifiques pour détecter immédiatement les changements de loi.
- Scraper quotidiennement la section 'Guidance and Regulation'.
- Extraire le texte des documents et les horodatages de dernière mise à jour.
- Comparer le contenu avec les versions précédentes pour mettre en évidence les différences.
- Envoyer des alertes automatisées aux parties prenantes internes concernées.
- Suivi des opportunités d'appels d'offres
Les équipes commerciales peuvent scraper les avis de marchés publics pour trouver de nouvelles opportunités de contrats gouvernementaux.
- Cibler la catégorie de recherche 'Procurement' sur GOV.UK.
- Scraper les dates d'échéance, les e-mails de contact et les valeurs des contrats.
- Filtrer les résultats par mots-clés sectoriels pertinents pour votre entreprise.
- Importer les prospects directement dans un CRM pour le suivi.
- Analyse des tendances économiques
Les économistes peuvent agréger les publications statistiques pour des études longitudinales sur les performances du Royaume-Uni.
- Identifier les URL des séries de données statistiques.
- Scraper les liens directs vers les fichiers CSV ou Excel.
- Télécharger et nettoyer les jeux de données à l'aide de scripts automatisés.
- Fusionner les données dans une base de données centralisée pour la visualisation.
- Archives des politiques publiques
Les journalistes et les chercheurs peuvent créer une archive interrogeable des annonces officielles du gouvernement.
- Scraper la section 'News and Communications' en continu.
- Extraire les titres, le corps du texte et les tags ministériels.
- Indexer les données dans une plateforme de recherche comme Elasticsearch.
- Analyser le sentiment et la fréquence de mots-clés politiques spécifiques.
- Bots d'assistance automatisés
Les organisations à but non lucratif peuvent utiliser les guides officiels pour alimenter des chatbots qui aident les citoyens à trouver des informations sur les prestations sociales.
- Scraper les pages de guides sur les prestations et le logement.
- Mapper le texte extrait vers une base de données vectorielle pour le RAG (Retrieval-Augmented Generation).
- Configurer un déclencheur pour actualiser la base de données lorsque le contenu de GOV.UK change.
- Fournir des réponses précises et en temps réel aux requêtes des utilisateurs.
- Moteur de découverte de subventions
Les institutions éducatives peuvent trouver des opportunités de subventions et de financement pour des projets de recherche.
- Scraper la catégorie de financement 'Education, Training and Skills'.
- Extraire les critères d'éligibilité et les dates limites de candidature.
- Catégoriser les subventions par ministère et par montant de financement.
- Automatiser des résumés hebdomadaires par e-mail pour les membres du corps enseignant.
Optimisez votre flux de travail avec l'Automatisation IA
Automatio combine la puissance des agents IA, de l'automatisation web et des integrations intelligentes pour vous aider a accomplir plus en moins de temps.
Conseils Pro pour Scraper GOV.UK
Conseils d'experts pour extraire avec succès les données de GOV.UK.
L'astuce de l'extension .json
De nombreuses pages de Gov.uk vous permettent d'ajouter .json à l'URL pour recevoir directement des données structurées, ce qui est plus rapide et plus fiable que le scraping HTML.
Régulez vos requêtes
Évitez les vitesses de scraping agressives ; implémentez un délai de 2 à 5 secondes entre les requêtes pour éviter de déclencher les rate limits et les blocages d'IP.
Utilisez d'abord les API officielles
Exploitez les API spécifiques de Companies House ou de Find a Tender, car elles sont explicitement conçues pour les développeurs et offrent une bien meilleure stabilité.
Gérez les erreurs 429 avec élégance
Si vous recevez une erreur 'Too Many Requests', mettez votre scraper en pause pendant plusieurs minutes et vérifiez votre cadence de crawl avant de reprendre.
Effectuez une rotation des User-Agents
Utilisez toujours des en-têtes User-Agent de navigateurs modernes et valides pour éviter d'être immédiatement identifié comme un simple script par les couches de sécurité.
Témoignages
Ce Que Disent Nos Utilisateurs
Rejoignez des milliers d'utilisateurs satisfaits qui ont transforme leur flux de travail
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Associés Web Scraping
Questions Fréquentes sur GOV.UK
Trouvez des réponses aux questions courantes sur GOV.UK