Comment scraper USPTO.gov | Scraper Web pour Brevets et Marques USPTO
Découvrez comment scraper USPTO.gov pour obtenir des données sur les brevets et les marques. Extrayez numéros de brevets, inventeurs et dates de dépôt pour...
Protection Anti-Bot Détectée
- Cloudflare
- WAF et gestion de bots de niveau entreprise. Utilise des défis JavaScript, des CAPTCHAs et l'analyse comportementale. Nécessite l'automatisation du navigateur avec des paramètres furtifs.
- Limitation de débit
- Limite les requêtes par IP/session dans le temps. Peut être contourné avec des proxys rotatifs, des délais de requête et du scraping distribué.
- Blocage IP
- Bloque les IP de centres de données connues et les adresses signalées. Nécessite des proxys résidentiels ou mobiles pour contourner efficacement.
- Session-based URLs
- Google reCAPTCHA
- Système CAPTCHA de Google. v2 nécessite une interaction utilisateur, v3 fonctionne silencieusement avec un score de risque. Peut être résolu avec des services CAPTCHA.
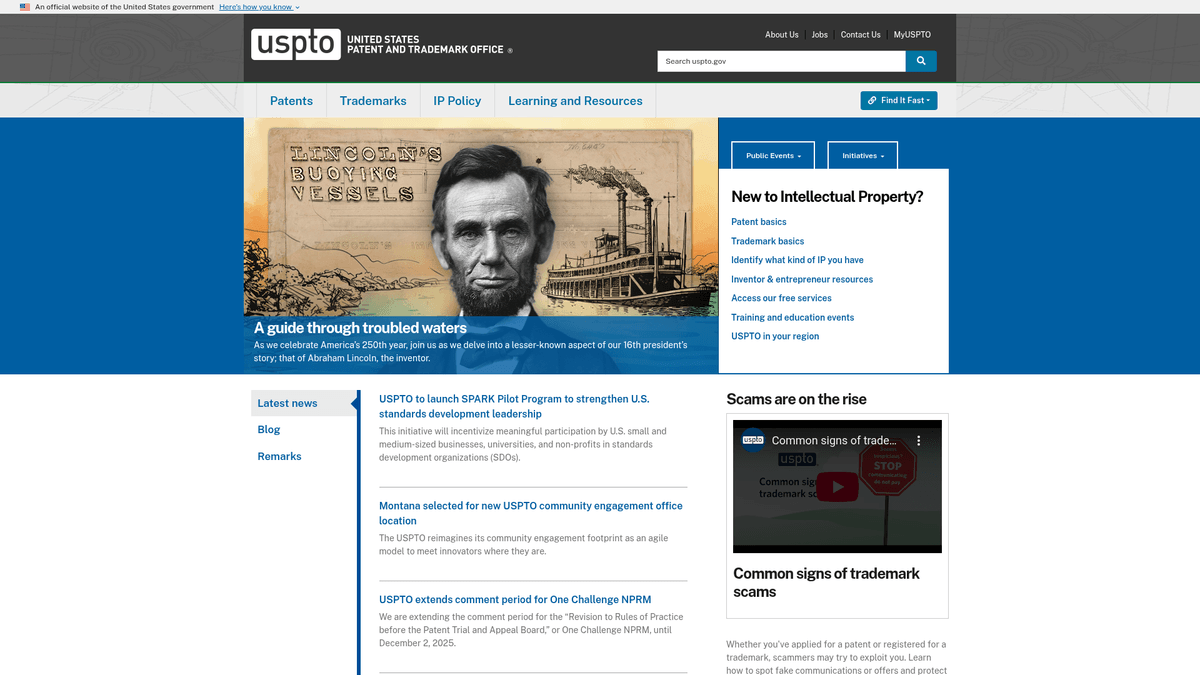
À Propos de USPTO (United States Patent and Trademark Office)
Découvrez ce que USPTO (United States Patent and Trademark Office) offre et quelles données précieuses peuvent être extraites.
L'United States Patent and Trademark Office (USPTO) est l'agence fédérale responsable de l'octroi des brevets américains et de l'enregistrement des marques. Elle gère une base de données publique massive de documents de propriété intellectuelle (PI) documentant l'innovation et la propriété de marques depuis 1790. Le site web propose des portails de recherche complexes tels que le TSDR (Trademark Status & Document Retrieval) et l'outil Patent Public Search.
Les données de l'USPTO constituent la référence absolue pour la recherche en propriété intellectuelle. Elles comprennent des détails granulaires sur les inventions, les revendications techniques, les cessions juridiques et les identifiants de marques. Pour les entreprises et les professionnels du droit, ces données sont cruciales pour vérifier la validité de la PI, effectuer des audits préalables lors d'acquisitions et identifier les tendances technologiques émergentes avant qu'elles ne s'imposent sur le marché général.
Scraper l'USPTO est extrêmement précieux pour les entreprises de legal tech, les départements R&D et les analystes de marché. Cela permet d'automatiser la veille concurrentielle, de suivre le cycle de vie des demandes de marques et de construire des jeux de données complets pour l'analyse du paysage des brevets.
Pourquoi Scraper USPTO (United States Patent and Trademark Office)?
Découvrez la valeur commerciale et les cas d'utilisation pour l'extraction de données de USPTO (United States Patent and Trademark Office).
Analyse du paysage concurrentiel
Suivez systématiquement les dépôts de brevets de vos concurrents pour identifier leurs axes de R&D et prédire les cycles de développement de futurs produits avant leur mise sur le marché.
Surveillance des contrefaçons de marques
Automatisez la détection des nouvelles demandes de marques qui pourraient entrer en conflit avec votre identité de marque existante pour garantir une opposition légale en temps opportun.
Génération de leads pour services juridiques
Identifiez les entreprises déposant récemment des dossiers « pro se » (sans avocat) pour proposer des services spécialisés de représentation juridique ou de conseil en propriété intellectuelle.
Évaluation de brevet et due diligence
Extrayez l'historique complet des cessions de brevets et des paiements de frais de maintenance pour évaluer la force juridique actuelle et la valeur marchande des portefeuilles de PI.
Identification des tendances de R&D
Analysez les classifications techniques (CPC/IPC) à grande échelle pour découvrir les secteurs technologiques émergents qui connaissent une croissance rapide du volume de brevets.
Stratégie d'entrée sur le marché
Rassemblez des données sur les brevets existants dans une niche spécifique pour effectuer une analyse de liberté d'exploitation (FTO), garantissant que votre expansion ne viole pas les protections existantes.
Défis du Scraping
Défis techniques que vous pouvez rencontrer lors du scraping de USPTO (United States Patent and Trademark Office).
Identifiants de session volatiles
Les systèmes de recherche de l'USPTO comme TSDR et TESS utilisent des tokens spécifiques à la session qui expirent rapidement, provoquant l'échec des scrapers s'ils ne maintiennent pas un état de navigateur cohérent.
Interface utilisateur dynamique et SPAs
Les portails modernes comme le Patent Public Search (PPUBS) s'appuient fortement sur les WebSockets et le JavaScript, ce qui signifie que les requêtes HTTP traditionnelles ne retourneront aucune donnée utile.
WAF agressif et Rate Limiting
Le site utilise des protections WAF strictes et des limites de débit qui peuvent entraîner des bannissements d'IP immédiats si les requêtes de recherche sont soumises trop rapidement ou depuis des data centers automatisés.
Formats de données incohérents
Les données résident souvent dans des tableaux HTML imbriqués ou des blocs de texte non structurés, nécessitant une logique d'analyse complexe pour extraire des jeux de données propres et structurés.
Fenêtres de maintenance des systèmes hérités
Les bases de données pour les marques et les brevets sont fréquemment mises hors ligne pour une maintenance programmée le week-end, ce qui peut interrompre les programmes de scraping automatisés.
Scrapez USPTO (United States Patent and Trademark Office) avec l'IA
Aucun code requis. Extrayez des données en minutes avec l'automatisation par IA.
Comment ça marche
Décrivez ce dont vous avez besoin
Dites à l'IA quelles données vous souhaitez extraire de USPTO (United States Patent and Trademark Office). Tapez simplement en langage naturel — pas de code ni de sélecteurs.
L'IA extrait les données
Notre intelligence artificielle navigue sur USPTO (United States Patent and Trademark Office), gère le contenu dynamique et extrait exactement ce que vous avez demandé.
Obtenez vos données
Recevez des données propres et structurées, prêtes à exporter en CSV, JSON ou à envoyer directement à vos applications.
Pourquoi utiliser l'IA pour le scraping
L'IA facilite le scraping de USPTO (United States Patent and Trademark Office) sans écrire de code. Notre plateforme alimentée par l'intelligence artificielle comprend quelles données vous voulez — décrivez-les en langage naturel et l'IA les extrait automatiquement.
How to scrape with AI:
- Décrivez ce dont vous avez besoin: Dites à l'IA quelles données vous souhaitez extraire de USPTO (United States Patent and Trademark Office). Tapez simplement en langage naturel — pas de code ni de sélecteurs.
- L'IA extrait les données: Notre intelligence artificielle navigue sur USPTO (United States Patent and Trademark Office), gère le contenu dynamique et extrait exactement ce que vous avez demandé.
- Obtenez vos données: Recevez des données propres et structurées, prêtes à exporter en CSV, JSON ou à envoyer directement à vos applications.
Why use AI for scraping:
- Gestion de session persistante: Automatio gère automatiquement la session de navigation sous-jacente, contournant efficacement les erreurs de « Session expirée » qui affectent les scripts de scraping traditionnels.
- Extraction de données visuelle: L'interface point-and-click vous permet de sélectionner visuellement des revendications de brevets complexes et des statuts de marques sans avoir à naviguer dans des structures DOM difficiles.
- Planification automatisée des tâches: Configurez votre scraper pour s'exécuter spécifiquement pendant les heures de bureau ou immédiatement après les mises à jour hebdomadaires pour vous assurer de toujours travailler avec des données de PI actuelles.
- Récupération fluide d'images et de documents: Automatio peut facilement détecter et télécharger les logos de marques et les dessins de brevets dans le cadre du flux de scraping, en les enregistrant directement sur votre stockage.
- Logique No-Code pour les tableaux gouvernementaux: Convertissez des tableaux de données gouvernementaux désordonnés en formats structurés CSV ou JSON sans écrire une seule ligne de regex ou de logique d'analyse.
Scrapers Web No-Code pour USPTO (United States Patent and Trademark Office)
Alternatives pointer-cliquer au scraping alimenté par l'IA
Plusieurs outils no-code comme Browse.ai, Octoparse, Axiom et ParseHub peuvent vous aider à scraper USPTO (United States Patent and Trademark Office) sans écrire de code. Ces outils utilisent généralement des interfaces visuelles pour sélectionner les données, bien qu'ils puissent avoir des difficultés avec le contenu dynamique complexe ou les mesures anti-bot.
Workflow Typique avec les Outils No-Code
Défis Courants
Courbe d'apprentissage
Comprendre les sélecteurs et la logique d'extraction prend du temps
Les sélecteurs cassent
Les modifications du site web peuvent casser tout le workflow
Problèmes de contenu dynamique
Les sites riches en JavaScript nécessitent des solutions complexes
Limitations des CAPTCHAs
La plupart des outils nécessitent une intervention manuelle pour les CAPTCHAs
Blocage d'IP
Le scraping agressif peut entraîner le blocage de votre IP
Scrapers Web No-Code pour USPTO (United States Patent and Trademark Office)
Plusieurs outils no-code comme Browse.ai, Octoparse, Axiom et ParseHub peuvent vous aider à scraper USPTO (United States Patent and Trademark Office) sans écrire de code. Ces outils utilisent généralement des interfaces visuelles pour sélectionner les données, bien qu'ils puissent avoir des difficultés avec le contenu dynamique complexe ou les mesures anti-bot.
Workflow Typique avec les Outils No-Code
- Installer l'extension de navigateur ou s'inscrire sur la plateforme
- Naviguer vers le site web cible et ouvrir l'outil
- Sélectionner en point-and-click les éléments de données à extraire
- Configurer les sélecteurs CSS pour chaque champ de données
- Configurer les règles de pagination pour scraper plusieurs pages
- Gérer les CAPTCHAs (nécessite souvent une résolution manuelle)
- Configurer la planification pour les exécutions automatiques
- Exporter les données en CSV, JSON ou se connecter via API
Défis Courants
- Courbe d'apprentissage: Comprendre les sélecteurs et la logique d'extraction prend du temps
- Les sélecteurs cassent: Les modifications du site web peuvent casser tout le workflow
- Problèmes de contenu dynamique: Les sites riches en JavaScript nécessitent des solutions complexes
- Limitations des CAPTCHAs: La plupart des outils nécessitent une intervention manuelle pour les CAPTCHAs
- Blocage d'IP: Le scraping agressif peut entraîner le blocage de votre IP
Exemples de Code
import requests
from bs4 import BeautifulSoup
# Note : Les données bulk sont plus simples pour les volumes élevés
url = 'https://bulkdata.uspto.gov/'
headers = {'User-Agent': 'Mozilla/5.0'}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Recherche des liens vers les fichiers zip hebdomadaires de brevets
links = [a['href'] for a in soup.find_all('a', href=True) if '.zip' in a['href']]
print(f'Trouvé {len(links)} jeux de données disponibles au téléchargement')
except Exception as e:
print(f'Erreur : {e}')Quand Utiliser
Idéal pour les pages HTML statiques avec peu de JavaScript. Parfait pour les blogs, sites d'actualités et pages e-commerce simples.
Avantages
- ●Exécution la plus rapide (sans surcharge navigateur)
- ●Consommation de ressources minimale
- ●Facile à paralléliser avec asyncio
- ●Excellent pour les APIs et pages statiques
Limitations
- ●Ne peut pas exécuter JavaScript
- ●Échoue sur les SPAs et contenu dynamique
- ●Peut avoir des difficultés avec les systèmes anti-bot complexes
Comment Scraper USPTO (United States Patent and Trademark Office) avec du Code
Python + Requests
import requests
from bs4 import BeautifulSoup
# Note : Les données bulk sont plus simples pour les volumes élevés
url = 'https://bulkdata.uspto.gov/'
headers = {'User-Agent': 'Mozilla/5.0'}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Recherche des liens vers les fichiers zip hebdomadaires de brevets
links = [a['href'] for a in soup.find_all('a', href=True) if '.zip' in a['href']]
print(f'Trouvé {len(links)} jeux de données disponibles au téléchargement')
except Exception as e:
print(f'Erreur : {e}')Python + Playwright
from playwright.sync_api import sync_playwright
def scrape_uspto_trademark():
with sync_playwright() as p:
# L'USPTO nécessite un fingerprint de navigateur réel pour éviter Cloudflare
browser = p.chromium.launch(headless=True)
page = browser.new_page()
# Navigation vers la page de statut TSDR
page.goto('https://tsdr.uspto.gov/')
# Saisir un numéro de série (Exemple : 98021018)
page.fill('#caseNumber', '98021018')
page.click('#statusSearch')
# Attendre que la section de statut soit rendue via JS
page.wait_for_selector('.status-info')
# Extraire les données de la page
mark_name = page.inner_text('.mark-name')
print(f'Nom de la marque : {mark_name}')
browser.close()
scrape_uspto_trademark()Python + Scrapy
import scrapy
class UsptoSpider(scrapy.Spider):
name = 'uspto_spider'
# Ciblage du répertoire Patent Grant Red Book
start_urls = ['https://bulkdata.uspto.gov/data/patent/grant/redbook/2024/']
def parse(self, response):
# Scraper tous les liens des fichiers zip pour l'année 2024
for file_link in response.css('a::attr(href)').getall():
if file_link.endswith('.zip'):
yield {
'file_url': response.urljoin(file_link),
'year': 2024
}
# La logique de navigation dans les répertoires peut être ajoutée iciNode.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
// Accès à la page d'accueil de Patent Public Search
await page.goto('https://ppubs.uspto.gov/pubwebapp/static/pages/landing.html');
// Attendre que le bouton 'Basic Search' apparaisse
await page.waitForSelector('#basic-search-button');
await page.click('#basic-search-button');
// Logique supplémentaire pour saisir des requêtes et attendre les tableaux dynamiques
await page.waitForSelector('.result-item');
const results = await page.evaluate(() => {
return Array.from(document.querySelectorAll('.patent-title')).map(el => el.innerText);
});
console.log('Titres scrapés :', results);
await browser.close();
})();Que Pouvez-Vous Faire Avec Les Données de USPTO (United States Patent and Trademark Office)
Explorez les applications pratiques et les insights des données de USPTO (United States Patent and Trademark Office).
Surveillance concurrentielle des marques
Les détaillants et les propriétaires de marques peuvent surveiller les nouveaux dépôts de marques pour se protéger contre la contrefaçon et l'entrée sur le marché de concurrents.
Comment implémenter :
- 1Scraper les dépôts hebdomadaires de marques pour des mots-clés spécifiques liés à votre marque.
- 2Comparer les nouveaux dépôts avec les marques et dessins existants.
- 3Alerter les équipes juridiques lorsque des marques similaires sont déposées dans les classes IC pertinentes.
Utilisez Automatio pour extraire des données de USPTO (United States Patent and Trademark Office) et créer ces applications sans écrire de code.
Que Pouvez-Vous Faire Avec Les Données de USPTO (United States Patent and Trademark Office)
- Surveillance concurrentielle des marques
Les détaillants et les propriétaires de marques peuvent surveiller les nouveaux dépôts de marques pour se protéger contre la contrefaçon et l'entrée sur le marché de concurrents.
- Scraper les dépôts hebdomadaires de marques pour des mots-clés spécifiques liés à votre marque.
- Comparer les nouveaux dépôts avec les marques et dessins existants.
- Alerter les équipes juridiques lorsque des marques similaires sont déposées dans les classes IC pertinentes.
- Cartographie des tendances de l'innovation
Les laboratoires de R&D peuvent analyser les octrois de brevets pour voir quelles technologies reçoivent des investissements massifs de la part des multinationales.
- Scraper les résumés et les catégories de brevets sur une période glissante de 5 ans.
- Utiliser le NLP pour identifier les mots-clés techniques et les classifications CPC en vogue.
- Visualiser la croissance de secteurs technologiques spécifiques comme l'IA, la biotech ou l'énergie verte.
- Audit préalable (Due Diligence) en Legal Tech
Les cabinets d'avocats peuvent automatiser la collecte de l'ensemble du portefeuille de PI d'une entité pour les activités de fusion-acquisition et les évaluations.
- Saisir une liste de noms d'entreprises ou d'identifiants de cessionnaires dans le scraper.
- Extraire tous les enregistrements actifs de brevets et de marques pour ces entités, y compris les dates d'expiration.
- Générer un rapport sur la force, la diversité et les échéances de renouvellement des actifs.
- Génération de leads pour les services de PI
Les avocats peuvent identifier les nouveaux déposants qui pourraient avoir besoin de services spécialisés en matière de brevets ou de marques.
- Filtrer les nouvelles demandes de marques sans avocat attitré.
- Extraire les coordonnées des correspondants et les détails du propriétaire.
- Effectuer une prospection ciblée pour des services de représentation juridique ou de gestion des renouvellements.
Optimisez votre flux de travail avec l'Automatisation IA
Automatio combine la puissance des agents IA, de l'automatisation web et des integrations intelligentes pour vous aider a accomplir plus en moins de temps.
Conseils Pro pour Scraper USPTO (United States Patent and Trademark Office)
Conseils d'experts pour extraire avec succès les données de USPTO (United States Patent and Trademark Office).
Tirez parti du Bulk Data System
Pour les besoins à haut volume, utilisez bulkdata.uspto.gov pour télécharger des fichiers XML plutôt que de scraper l'interface de recherche, car c'est beaucoup plus rapide et moins restrictif.
Utilisez des proxies résidentiels
Les portails de recherche de l'USPTO sont très sensibles aux adresses IP de data centers ; l'utilisation de proxies résidentiels vous aidera à simuler un comportement humain et à éviter les blocages liés au rate-limiting.
Privilégiez l'analyse XML à l'analyse HTML
Dès que possible, ciblez les téléchargements XML ou les points de terminaison API car la structure HTML des résultats de recherche est sujette à des mises à jour et des changements de format fréquents.
Synchronisez-vous avec les mises à jour du mardi
L'USPTO publie généralement les nouveaux brevets accordés et les enregistrements de marques tous les mardis ; planifiez vos scrapers pour le mercredi matin afin de capturer les dernières données.
Simulez une interaction utilisateur réelle
Incluez des délais aléatoires entre les requêtes de recherche et des simulations de mouvements de souris pour rester sous le radar des systèmes de détection anti-bot du site.
Extrayez les revendications de brevet séparément
Comme les sections de revendications sont souvent très longues et contiennent un formatage technique, extrayez-les dans un champ de texte distinct pour préserver la structure hiérarchique.
Témoignages
Ce Que Disent Nos Utilisateurs
Rejoignez des milliers d'utilisateurs satisfaits qui ont transforme leur flux de travail
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Associés Web Scraping
Questions Fréquentes sur USPTO (United States Patent and Trademark Office)
Trouvez des réponses aux questions courantes sur USPTO (United States Patent and Trademark Office)