
Gemini 3.1 Pro
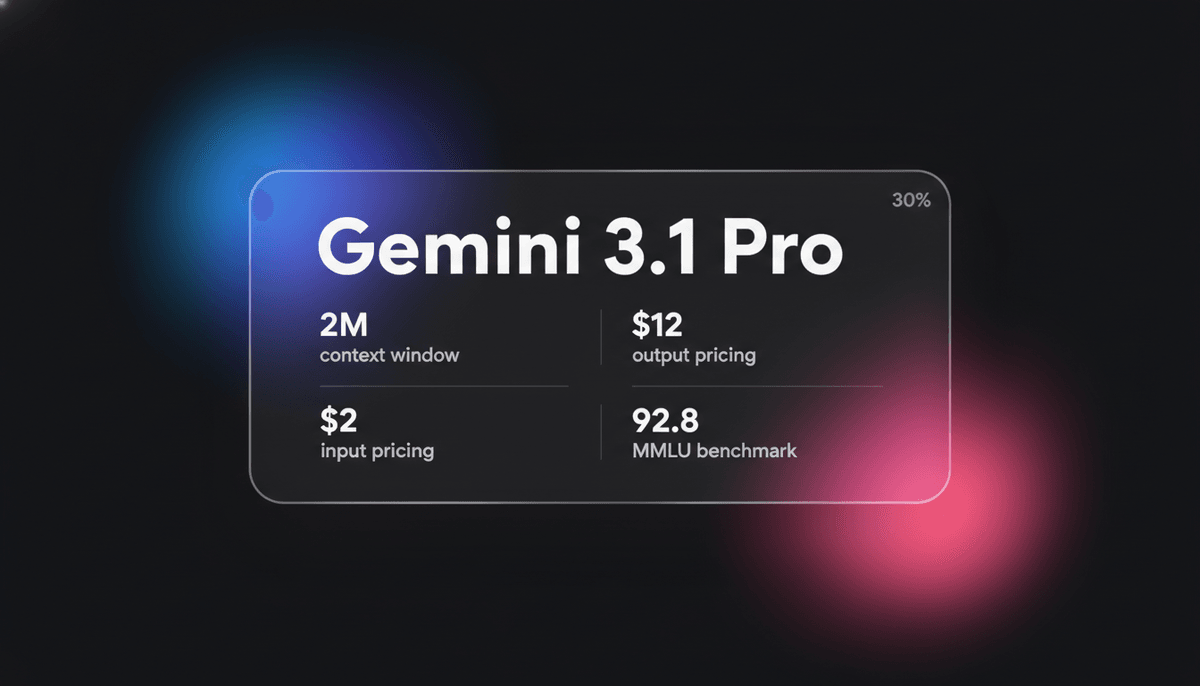
A Gemini 3.1 Pro a Google elit multimodal modelje, amely DeepThink reasoning motorral, 1M+ context window-val és iparágvezető ARC-AGI logikai pontszámokkal...
A Gemini 3.1 Pro reszletei
Ismerd meg a Gemini 3.1 Pro kepessegeit, funkcioit es hogy hogyan segithet jobb eredmenyeket elerni.
A Gemini 3.1 Pro a Sparse Mixture-of-Experts (MoE) keretrendszer érett megvalósítását képviseli, natívan párosítva egy fejlett multimodal feldolgozó motorral. Az architektúra kiemelkedő jellemzője a DeepThink System 2 réteg demokratizálása, amely lehetővé teszi a model számára, hogy belsőleg mérlegeljen, mielőtt elkötelezné magát egy kimeneti token mellett. Ez a model egy egyedülálló háromszintű gondolkodási rendszert vezet be (Alacsony, Közepes, Magas), lehetővé téve a fejlesztők számára, hogy kifejezetten kontrollálják a latency, a költség és a reasoning mélysége közötti kompromisszumot.
A hatalmas, 1 milliós tokenes context window-val a Gemini 3.1 Pro magasan optimalizált a pénzügyi, adatelemzési és teljes adattárat érintő kódmigrációs komplex munkafolyamatokhoz. Emergens képességet mutat az új logikai minták megoldására, példátlan 77,1%-os eredményt érve el az ARC-AGI-2 benchmarkon. Ez teszi a fejlesztők kedvelt választásává, akiknek egyaránt szükségük van alacsony latencyjű multimodal interakciókra és magas szintű kognitív teljesítményre az autonóm agentic feladatokhoz.
Hasznalati esetek a Gemini 3.1 Pro szamara
Fedezd fel a kulonbozo modokat, ahogyan a Gemini 3.1 Pro-t hasznalhatod remek eredmenyek eleresehez.
Teljes adattár kódanalízise
Az 1M context window kihasználása teljes szoftveres adattárak betöltésére refaktorálás és függőségfeltérképezés céljából.
Autonóm Agent bizottságok
Többlépcsős agentic munkafolyamatok vezérlése, ahol belső al-agentek vitatkoznak és ellenőrzik a megoldásokat a végrehajtás előtt.
Tudományos kutatások szintézise
Többezer kutatási cikk és komplex adathalmaz elemzése strukturált információk és tényszerű meglátások kinyerésére.
Multimodal tartalomkészítés
Szöveg, képek és hang egyidejű feldolgozása komplex oktatási anyagok és interaktív média generálására.
Terminál-alapú automatizálás
Komplex bash parancsok végrehajtása és fájlrendszerek manipulálása nagy pontossággal, fejlett reasoning módokon keresztül.
Vállalati adat auditálás
Strukturálatlan pénzügyi adatok és jogi dokumentumok elemzése a megfelelőségi hiányosságok azonosítására, szinte tökéletes tényszerű felidézéssel.
Erossegek
Korlatozasok
API gyorsinditas
google/gemini-3.1-pro-preview
import { GoogleGenAI } from "@google/genai";
const genAI = new GoogleGenAI(process.env.GOOGLE_API_KEY);
const model = genAI.getGenerativeModel({
model: "gemini-3.1-pro-preview",
thinkingConfig: { tier: "high" }
});
const prompt = "Analyze this entire codebase for security vulnerabilities.";
const result = await model.generateContent(prompt);
console.log(result.response.text());Telepitsd az SDK-t es kezdj API hivasokat vegezni perceken belul.
Mit mondanak az emberek a Gemini 3.1 Pro-rol
Nezd meg, mit gondol a kozosseg a Gemini 3.1 Pro-rol
“A Gemini 3.1 Pro 77,1%-os pontszáma a leginkább bomlasztó piaci váltást jelenti; több mint megduplázza a korábbi csúcsot az ARC-AGI-n.”
“A kódolási benchmarkok nem hazudnak. Ez a model talált egy hibát a repómban, amit a 3.5 és a GPT-4o teljesen kihagyott.”
“A gemini 3.1 körüli felhajtás igazán érdekes. Letarolta a benchmarkokat, de a valódi felhasználók azt mondják, a hangnem és a vibe inkonzisztens.”
“A DeepThink engine jelentős késéseket okozhat, néha több mint 90 másodpercet, amikor mély logikát igénylő feladatokat dolgoz fel.”
“A context caching a nyerő funkció itt. Egy teljes dokumentációs botot futtatok fillérekért a GPT-4o-hoz képest.”
“A Gemini egyáltalán nem beszélt Pythonról egy komplex tervezési feladatban... néhány logika egyszerűen hiányzott a végső tervéből.”
Videok a Gemini 3.1 Pro-rol
Nezz oktatoanyagokat, ertekeléseket es beszelgetéseket a Gemini 3.1 Pro-rol
“A Gemini 3.1 Pro generálja a legrészletesebb változatot ebből a pagodából eddig”
“A Gemininek van messze a legszélesebb, egymillió tokenes ablaka”
“A hangfeldolgozás multimodal hűsége észrevehetően jobb, mint a 3.0-nál”
“A token throughput stabil marad, még akkor is, ha a context window megtelik”
“A hosszú távú felidézés alapvetően tökéletes az egymillió tokenen keresztül”
“Azokon a rejtvényeken, amelyeknek nem szabadna a tréningadatokban lenniük, a Gemini 3 sorozat felülmúlja az összes többi modelt”
“A 3.1 Pro valóban csökkenthetné egy fine-tuning szkript futási idejét 300 másodpercről 47 másodpercre”
“A DeepThink logikai lépései tisztán láthatóak a nyomkövetésben, valódi megfontolást mutatva”
“Elérjük a benchmark telítettséget, ahol a fejlődés szempontjából csak az ARC-AGI számít igazán”
“Az AGI pálya gyorsul ezeken az absztrakt reasoning ugrásokon alapulva”
“Szerintem a 3.1 valóban egy szintlépésnek érződik, még ha nagyon kicsi is”
“Úgy tűnik, hogy felülmúlja a Gemini 3.0 Pro-t, amikor pontosan ugyanazokat a promptokat teszteljük egymás mellett”
“A kódolási pontosság komplex Python refaktorálásnál a legmagasabb, amit láttam”
“Az API megbízhatósága jelentősen javult az utolsó teszthónap alatt”
“A valós teljesítmény végre megfelel a benchmark pontszámok körüli hírverésnek”
Turbozd fel a munkafolyamatodat AI automatizalasal
Az Automatio egyesiti az AI ugynokk, a web automatizalas es az okos integraciok erejet, hogy segitsen tobbet elerni kevesebb ido alatt.
Profi tippek a Gemini 3.1 Pro szamara
Szakertoi tippek, hogy a legtobbet hozd ki a Gemini 3.1 Pro-bol es jobb eredmenyeket erj el.
Reasoning szint kiválasztása
Használd a High thinking módot komplex matekhoz vagy logikához, de válts Low-ra a szabványos formázáshoz, hogy compute-ot takaríts meg.
Context Caching
Implementálj context cachinget a statikus dokumentációhoz, hogy akár 90%-kal csökkentsd a bemeneti árakat egymillió tokenenként.
Strukturált Artifact-ok
Használd ki a model képességét strukturált feladatlisták generálására az emberi felügyelet megkönnyítésére agentic futtatások során.
Multimodal Prompting
Kombináld a videó és hang bemeneteket, hogy a model teljes képet kapjon a valós forgatókönyvekről, ahelyett, hogy csak szöveges leírásokat adnál.
Velemenyek
Mit mondanak a felhasznaloink
Csatlakozz tobb ezer elegedett felhasznalohoz, akik atalakitottak a munkafolyamatukat
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Kapcsolodo AI Models
Claude Opus 4.7
Anthropic
Claude Opus 4.7 is Anthropic's flagship model with a 1-million-token context, adaptive reasoning, and 3.3x vision resolution for enterprise-scale agents.
Gemini 3.1 Flash Live Preview
Gemini 3.1 Flash Live Preview is Google's ultra-low-latency, audio-to-audio model featuring a 131K context window, high-fidelity multimodal reasoning, and...
GPT-5.5
OpenAI
GPT-5.5 is OpenAI's flagship frontier model with a 1M context window and five reasoning effort levels, optimized for autonomous agentic workflows and coding.
Grok-3
xAI
Grok-3 is xAI's flagship reasoning model, featuring deep logic deduction, a 128k context window, and real-time integration with X for live research and coding.
Kimi K3
Moonshot
Kimi K3 is Moonshot AI's 2.8T MoE model with a 1M token context window, native multimodal vision, and frontier-tier coding performance for complex agents.
GPT-5.2 Pro
OpenAI
GPT-5.2 Pro is OpenAI's 2025 flagship reasoning model featuring Extended Thinking for SOTA performance in mathematics, coding, and expert knowledge work.
Qwen 3.7 Max
alibaba
Qwen 3.7 Max is Alibaba’s flagship AI model for deep reasoning and autonomous agent tasks, featuring a 256k context window and top-tier coding performance.
Gemini 3 Pro
Google's Gemini 3 Pro is a multimodal powerhouse featuring a 1M token context window, native video processing, and industry-leading reasoning performance.
Gyakran ismetelt kerdesek a Gemini 3.1 Pro-rol
Talalj valaszokat a Gemini 3.1 Pro-val kapcsolatos gyakori kerdesekre