
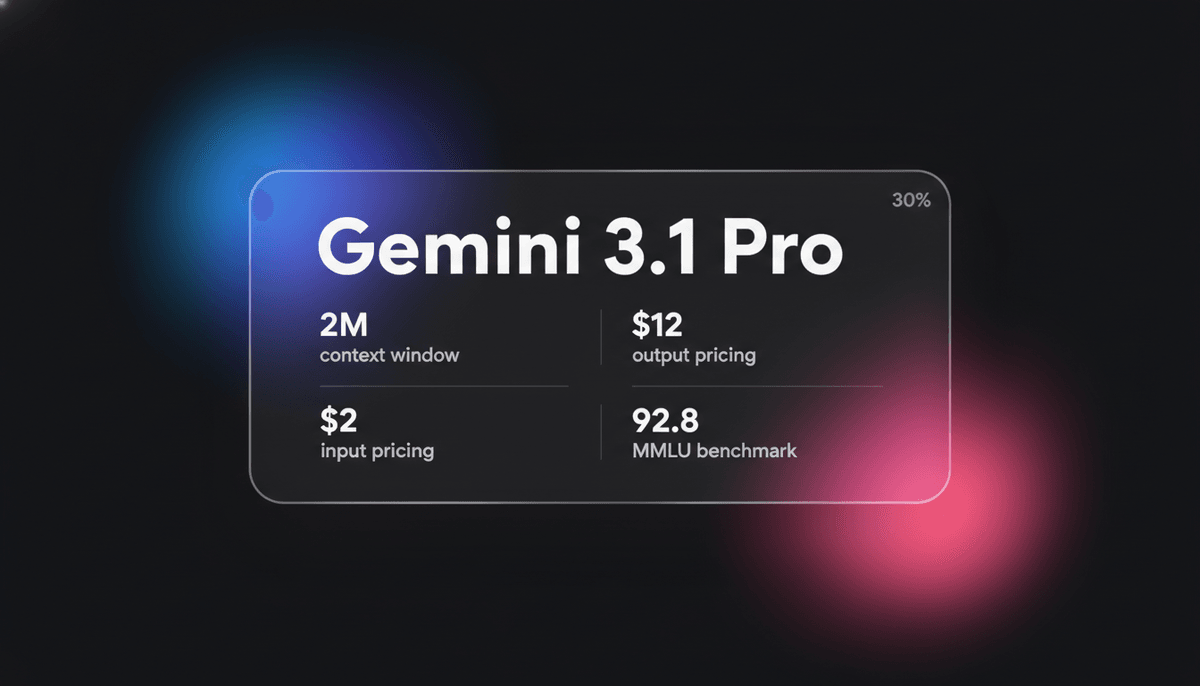
Gemini 3.1 Pro
Gemini 3.1 Pro adalah model multimodal elit Google yang menampilkan mesin reasoning DeepThink, context window 1M+, dan skor logika ARC-AGI terdepan di industri.
Tentang Gemini 3.1 Pro
Pelajari tentang kemampuan, fitur, dan cara menggunakan Gemini 3.1 Pro.
Gemini 3.1 Pro mewakili eksekusi matang dari kerangka kerja Sparse Mixture-of-Experts (MoE), yang dipadukan secara native dengan mesin pemrosesan multimodal tingkat lanjut. Fitur unggulan arsitekturnya adalah demokratisasi lapisan DeepThink System 2, yang memungkinkan model untuk mempertimbangkan secara internal sebelum memutuskan token output. Model ini memperkenalkan sistem thinking tiga tingkat yang unik, Low, Medium, dan High, yang memungkinkan pengembang untuk mengontrol secara eksplisit trade-off antara latency, biaya, dan kedalaman reasoning.
Dengan 1-million-token context window yang masif, Gemini 3.1 Pro dioptimalkan untuk alur kerja kompleks dalam keuangan, analisis data, dan migrasi kode seluruh repositori. Model ini menunjukkan kemampuan yang muncul untuk memecahkan pola logika baru, dengan skor 77,1% yang belum pernah terjadi sebelumnya pada benchmark ARC-AGI-2. Hal ini menjadikannya pilihan utama bagi pengembang yang membutuhkan interaksi multimodal dengan latency rendah sekaligus performa kognitif tingkat tinggi untuk tugas-tugas agentic otonom.
Kasus Penggunaan untuk Gemini 3.1 Pro
Temukan berbagai cara menggunakan Gemini 3.1 Pro untuk hasil yang luar biasa.
Analisis Kode Seluruh Repositori
Memanfaatkan 1M context window untuk memasukkan seluruh repositori perangkat lunak guna pemfaktoran ulang dan pemetaan dependensi.
Komite Agent Otonom
Mendorong alur kerja agentic multi-langkah di mana sub-agent internal berdebat dan memverifikasi solusi sebelum eksekusi.
Sintesis Riset Ilmiah
Menganalisis ribuan makalah penelitian dan dataset kompleks untuk mengekstrak kecerdasan terstruktur dan wawasan faktual.
Pembuatan Konten Multimodal
Memproses teks, gambar, dan audio secara bersamaan untuk menghasilkan materi instruksional yang kompleks dan media interaktif.
Otomasi Berbasis Terminal
Mengeksekusi perintah bash yang kompleks dan memanipulasi sistem file dengan presisi tinggi melalui mode reasoning tingkat lanjut.
Audit Data Perusahaan
Mengurai data keuangan tidak terstruktur dan dokumen hukum untuk mengidentifikasi celah kepatuhan dengan recall faktual yang hampir sempurna.
Kelebihan
Keterbatasan
Mulai Cepat API
google/gemini-3.1-pro-preview
import { GoogleGenAI } from "@google/genai";
const genAI = new GoogleGenAI(process.env.GOOGLE_API_KEY);
const model = genAI.getGenerativeModel({
model: "gemini-3.1-pro-preview",
thinkingConfig: { tier: "high" }
});
const prompt = "Analisis seluruh codebase ini untuk mencari celah keamanan.";
const result = await model.generateContent(prompt);
console.log(result.response.text());Instal SDK dan mulai melakukan panggilan API dalam hitungan menit.
Apa Kata Orang Tentang Gemini 3.1 Pro
Lihat apa yang dipikirkan komunitas tentang Gemini 3.1 Pro
“Skor 77,1% Gemini 3.1 Pro mewakili pergeseran pasar yang paling disruptif; skor ini lebih dari dua kali lipat rekor tertinggi sebelumnya di ARC-AGI.”
“Benchmark coding tidak berbohong. Model ini menemukan bug di repo saya yang benar-benar terlewatkan oleh 3.5 dan GPT-4o.”
“Keriuhan gemini 3.1 sangat menarik. Model ini menghancurkan benchmark, tetapi pengguna sebenarnya mengatakan nada dan getarannya tidak konsisten.”
“Mesin DeepThink dapat menyebabkan penundaan yang signifikan, terkadang lebih dari 90 detik, saat memproses tugas yang memerlukan logika mendalam.”
“Context caching adalah fitur unggulan di sini. Saya menjalankan seluruh bot dokumentasi dengan biaya sangat murah dibandingkan GPT-4o.”
“Gemini gagal membahas Python sama sekali dalam tugas perencanaan yang kompleks... beberapa logika tidak ada dalam rencana akhirnya.”
Video Tentang Gemini 3.1 Pro
Tonton tutorial, ulasan, dan diskusi tentang Gemini 3.1 Pro
“Gemini 3.1 Pro menghasilkan versi pagoda yang paling detail sejauh ini”
“Gemini memiliki context window terluas yaitu satu juta token”
“Fidelitas multimodal dalam pemrosesan audio terasa jauh lebih baik daripada 3.0”
“Throughput token tetap stabil bahkan saat context window terisi penuh”
“Recall jangka panjang benar-benar sempurna di seluruh satu juta token”
“Pada teka-teki yang seharusnya tidak ada dalam data pelatihannya, seri Gemini 3 mengungguli semua model lain”
“3.1 Pro memang dapat mengurangi runtime skrip fine-tuning dari 300 detik menjadi 47 detik”
“Langkah logika DeepThink terlihat jelas dalam penelusuran, menunjukkan pertimbangan yang nyata”
“Kita mencapai kejenuhan benchmark di mana hanya ARC-AGI yang benar-benar penting untuk kemajuan”
“Lintasan AGI semakin cepat berdasarkan lompatan reasoning abstrak ini”
“Menurut saya, 3.1 benar-benar terasa seperti peningkatan, meskipun hanya sedikit”
“Model ini tampaknya mengungguli Gemini 3.0 Pro saat kami menguji prompt yang sama persis secara berdampingan”
“Akurasi coding pada pemfaktoran ulang Python yang kompleks adalah yang tertinggi yang pernah saya lihat”
“Keandalan API telah meningkat secara signifikan selama bulan terakhir pengujian”
“Performa dunia nyata akhirnya menyamai hype skor benchmark”
Tingkatkan alur kerja Anda dengan Otomatisasi AI
Automatio menggabungkan kekuatan agen AI, otomatisasi web, dan integrasi cerdas untuk membantu Anda mencapai lebih banyak dalam waktu lebih singkat.
Tips Pro untuk Gemini 3.1 Pro
Tips ahli untuk memaksimalkan Gemini 3.1 Pro.
Pemilihan Tingkat Reasoning
Gunakan mode High thinking untuk logika atau matematika yang kompleks, namun beralihlah ke Low untuk pemformatan standar guna menghemat komputasi.
Context Caching
Implementasikan context caching untuk dokumentasi statis guna mengurangi harga input hingga 90% per juta tokens.
Artefak Terstruktur
Manfaatkan kemampuan model dalam menghasilkan daftar tugas terstruktur untuk mempermudah pengawasan manusia selama menjalankan agentic.
Multimodal Prompting
Kombinasikan input video dan audio untuk memberikan konteks dunia nyata yang utuh kepada model, alih-alih hanya deskripsi teks saja.
Testimoni
Apa Kata Pengguna Kami
Bergabunglah dengan ribuan pengguna puas yang telah mengubah alur kerja mereka
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Terkait AI Models
Claude Opus 4.7
Anthropic
Claude Opus 4.7 is Anthropic's flagship model with a 1-million-token context, adaptive reasoning, and 3.3x vision resolution for enterprise-scale agents.
Gemini 3.1 Flash Live Preview
Gemini 3.1 Flash Live Preview is Google's ultra-low-latency, audio-to-audio model featuring a 131K context window, high-fidelity multimodal reasoning, and...
GPT-5.5
OpenAI
GPT-5.5 is OpenAI's flagship frontier model with a 1M context window and five reasoning effort levels, optimized for autonomous agentic workflows and coding.
Grok-3
xAI
Grok-3 is xAI's flagship reasoning model, featuring deep logic deduction, a 128k context window, and real-time integration with X for live research and coding.
Kimi K3
Moonshot
Kimi K3 is Moonshot AI's 2.8T MoE model with a 1M token context window, native multimodal vision, and frontier-tier coding performance for complex agents.
GPT-5.2 Pro
OpenAI
GPT-5.2 Pro is OpenAI's 2025 flagship reasoning model featuring Extended Thinking for SOTA performance in mathematics, coding, and expert knowledge work.
Qwen 3.7 Max
alibaba
Qwen 3.7 Max is Alibaba’s flagship AI model for deep reasoning and autonomous agent tasks, featuring a 256k context window and top-tier coding performance.
Gemini 3 Pro
Google's Gemini 3 Pro is a multimodal powerhouse featuring a 1M token context window, native video processing, and industry-leading reasoning performance.
Pertanyaan yang Sering Diajukan tentang Gemini 3.1 Pro
Temukan jawaban untuk pertanyaan umum tentang Gemini 3.1 Pro