
Gemini 3.1 Pro
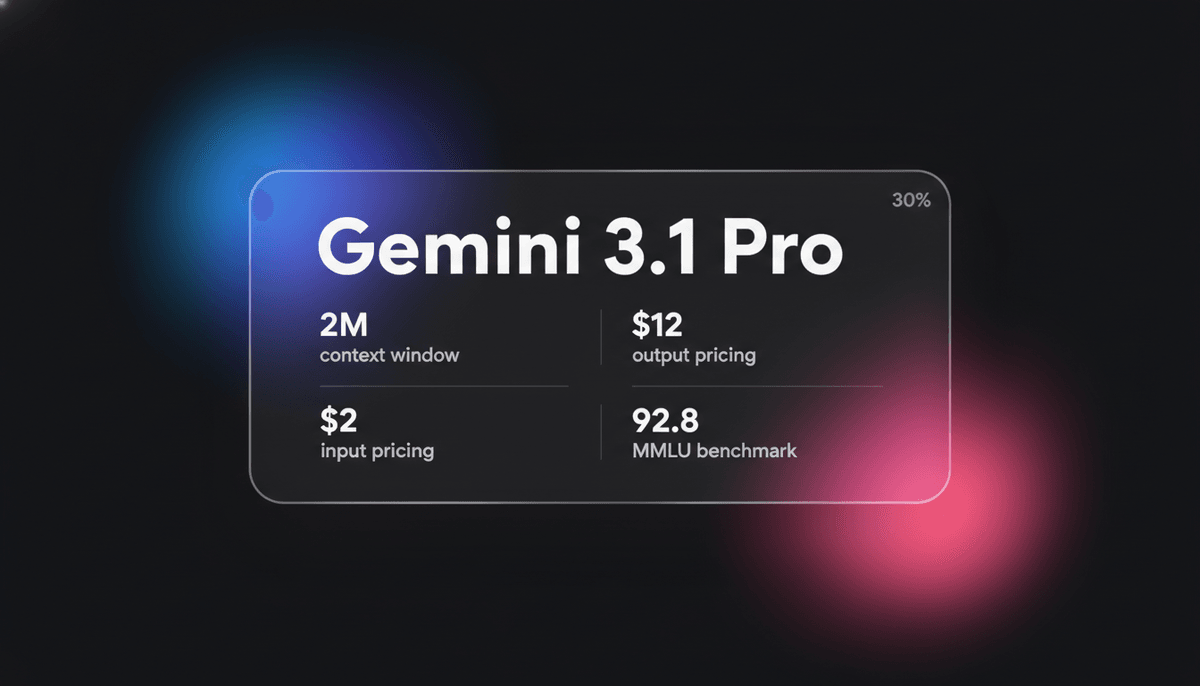
Gemini 3.1 Pro is Google's elite multimodale model met de DeepThink reasoning-engine, een 1M+ context window en toonaangevende ARC-AGI logische scores.
Over Gemini 3.1 Pro
Leer over de mogelijkheden van Gemini 3.1 Pro, functies en hoe het je kan helpen betere resultaten te behalen.
Gemini 3.1 Pro vertegenwoordigt een volwassen uitvoering van het Sparse Mixture-of-Experts (MoE) framework, native gekoppeld aan een geavanceerde multimodale verwerkings-engine. Het opvallendste kenmerk van de architectuur is de democratisering van de DeepThink System 2 layer, waardoor het model intern kan beraadslagen voordat het zich vastlegt op een output-token. Dit model introduceert een uniek drie-laags denksysteem (Laag, Medium en Hoog), waarmee ontwikkelaars expliciet de afweging tussen latency, kosten en reasoning-diepte kunnen beheersen.
Met een massaal 1-miljoen-token context window is Gemini 3.1 Pro sterk geoptimaliseerd voor complexe workflows in finance, data-analyse en code-migraties van volledige repositories. Het vertoont een opkomend vermogen om nieuwe logische patronen op te lossen, met een ongekende score van 77,1% op de ARC-AGI-2 benchmark. Dit maakt het een geprefereerde keuze voor ontwikkelaars die zowel multimodale interacties met lage latency als cognitieve prestaties op hoog niveau nodig hebben voor autonome agentic taken.
Gebruikscases voor Gemini 3.1 Pro
Ontdek de verschillende manieren waarop je Gemini 3.1 Pro kunt gebruiken voor geweldige resultaten.
Code-analyse van volledige repositories
Het 1M context window benutten om volledige software-repositories in te lezen voor refactoring en mapping van afhankelijkheden.
Autonome Agent-teams
Het aansturen van agentic workflows met meerdere stappen waarbij interne sub-agents debatteren en oplossingen verifiëren voor uitvoering.
Synthese van wetenschappelijk onderzoek
Het analyseren van duizenden onderzoeksdocumenten en complexe datasets om gestructureerde intelligentie en feitelijke inzichten te extraheren.
Multimodal Content Creatie
Tegelijkertijd tekst, afbeeldingen en audio verwerken om complexe instructiematerialen en interactieve media te genereren.
Terminal-gebaseerde automatisering
Complexe bash-commando's uitvoeren en bestandssystemen manipuleren met hoge precisie via geavanceerde reasoning-modi.
Audit van bedrijfsdata
Ongestructureerde financiële data en juridische documenten parsen om hiaten in compliance te identificeren met een bijna perfecte feitelijke recall.
Sterke punten
Beperkingen
API snelstart
google/gemini-3.1-pro-preview
import { GoogleGenAI } from "@google/genai";
const genAI = new GoogleGenAI(process.env.GOOGLE_API_KEY);
const model = genAI.getGenerativeModel({
model: "gemini-3.1-pro-preview",
thinkingConfig: { tier: "high" }
});
const prompt = "Analyze this entire codebase for security vulnerabilities.";
const result = await model.generateContent(prompt);
console.log(result.response.text());Installeer de SDK en begin binnen enkele minuten met API-calls.
Wat mensen zeggen over Gemini 3.1 Pro
Bekijk wat de community denkt over Gemini 3.1 Pro
“De score van 77,1% van Gemini 3.1 Pro vertegenwoordigt de meest ontwrichtende marktverschuiving; het verdubbelt meer dan het vorige hoogtepunt op ARC-AGI.”
“De codeer-benchmarks liegen niet. Dit model vond een bug in mijn repo die 3.5 en GPT-4o volledig misten.”
“De Gemini 3.1-heisa is erg interessant. Het verpletterde benchmarks, maar echte gebruikers zeggen dat de toon en de vibe inconsistent zijn.”
“De DeepThink-engine kan leiden tot aanzienlijke vertragingen, soms meer dan 90 seconden, bij het verwerken van taken die diepe logica vereisen.”
“Context caching is hier de killer feature. Ik draai een volledige documentatie-bot voor een fractie van de kosten vergeleken met GPT-4o.”
“Gemini faalde om Python überhaupt te bespreken bij een complexe plantaak... sommige logica was gewoon niet aanwezig in het uiteindelijke plan.”
Video's over Gemini 3.1 Pro
Bekijk tutorials, reviews en discussies over Gemini 3.1 Pro
“Gemini 3.1 Pro genereert tot nu toe de meest gedetailleerde versie van deze pagode”
“Gemini heeft veruit het breedste venster van een miljoen tokens”
“De multimodale getrouwheid bij audioverwerking is merkbaar beter dan in 3.0”
“De token throughput blijft stabiel, zelfs als het context window vol raakt”
“De langetermijn-recall is in principe perfect over de gehele miljoen tokens”
“Bij puzzels die niet in de trainingsdata zouden moeten staan, presteert de Gemini 3-serie beter dan alle andere modellen”
“3.1 Pro kan de runtime van een fine-tuning script inderdaad terugbrengen van 300 seconden naar 47 seconden”
“DeepThink-logische stappen zijn duidelijk zichtbaar in de trace, wat laat zien dat er echt wordt nagedacht”
“We bereiken benchmark-verzadiging waarbij alleen ARC-AGI er echt toe doet voor vooruitgang”
“Het AGI-traject versnelt op basis van deze sprongen in abstracte reasoning”
“Ik vind dat 3.1 oprecht voelt als een vooruitgang, zelfs als het maar heel klein is”
“Het lijkt inderdaad beter te presteren dan Gemini 3.0 Pro wanneer we exact dezelfde prompts naast elkaar testen”
“De codeer-nauwkeurigheid bij complexe Python-refactors is de hoogste die ik heb gezien”
“De API-betrouwbaarheid is aanzienlijk verbeterd in de afgelopen testmaand”
“De real-world prestaties komen eindelijk overeen met de hype van de benchmark-scores”
Supercharge je workflow met AI-automatisering
Automatio combineert de kracht van AI-agents, webautomatisering en slimme integraties om je te helpen meer te bereiken in minder tijd.
Pro-tips voor Gemini 3.1 Pro
Experttips om je te helpen het maximale uit Gemini 3.1 Pro te halen en betere resultaten te behalen.
Selectie van Reasoning-niveau
Gebruik de 'Hoog' denkmodus voor complexe wiskunde of logica, maar schakel over naar 'Laag' voor standaard opmaak om compute te besparen.
Context Caching
Implementeer context caching voor statische documentatie om de input-prijzen met maximaal 90% per miljoen tokens te verlagen.
Gestructureerde Artifacts
Benut het vermogen van het model om gestructureerde takenlijsten te genereren voor eenvoudiger toezicht door mensen tijdens agentic runs.
Multimodal Prompting
Combineer video- en audio-inputs om het model volledige context van real-world scenario's te geven in plaats van alleen tekstuele beschrijvingen.
Testimonials
Wat onze gebruikers zeggen
Sluit je aan bij duizenden tevreden gebruikers die hun workflow hebben getransformeerd
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Gerelateerd AI Models
Claude Opus 4.7
Anthropic
Claude Opus 4.7 is Anthropic's flagship model with a 1-million-token context, adaptive reasoning, and 3.3x vision resolution for enterprise-scale agents.
Gemini 3.1 Flash Live Preview
Gemini 3.1 Flash Live Preview is Google's ultra-low-latency, audio-to-audio model featuring a 131K context window, high-fidelity multimodal reasoning, and...
GPT-5.5
OpenAI
GPT-5.5 is OpenAI's flagship frontier model with a 1M context window and five reasoning effort levels, optimized for autonomous agentic workflows and coding.
Grok-3
xAI
Grok-3 is xAI's flagship reasoning model, featuring deep logic deduction, a 128k context window, and real-time integration with X for live research and coding.
Kimi K3
Moonshot
Kimi K3 is Moonshot AI's 2.8T MoE model with a 1M token context window, native multimodal vision, and frontier-tier coding performance for complex agents.
GPT-5.2 Pro
OpenAI
GPT-5.2 Pro is OpenAI's 2025 flagship reasoning model featuring Extended Thinking for SOTA performance in mathematics, coding, and expert knowledge work.
Qwen 3.7 Max
alibaba
Qwen 3.7 Max is Alibaba’s flagship AI model for deep reasoning and autonomous agent tasks, featuring a 256k context window and top-tier coding performance.
Gemini 3 Pro
Google's Gemini 3 Pro is a multimodal powerhouse featuring a 1M token context window, native video processing, and industry-leading reasoning performance.
Veelgestelde vragen over Gemini 3.1 Pro
Vind antwoorden op veelvoorkomende vragen over Gemini 3.1 Pro