Jak scrapować GOV.UK | Przewodnik po ekstrakcji danych z brytyjskich stron rządowych
Kompleksowy przewodnik po scrapowaniu GOV.UK pod kątem wytycznych rządowych, aktualizacji polityki i oficjalnych statystyk. Dowiedz się, jak wyodrębniać dane z...
Wykryto ochronę przed botami
- Ograniczanie szybkości
- Ogranicza liczbę żądań na IP/sesję w czasie. Można obejść za pomocą rotacyjnych proxy, opóźnień żądań i rozproszonego scrapingu.
- User-Agent Filtering
- Blokowanie IP
- Blokuje znane IP centrów danych i oznaczone adresy. Wymaga rezydencjalnych lub mobilnych proxy do skutecznego obejścia.
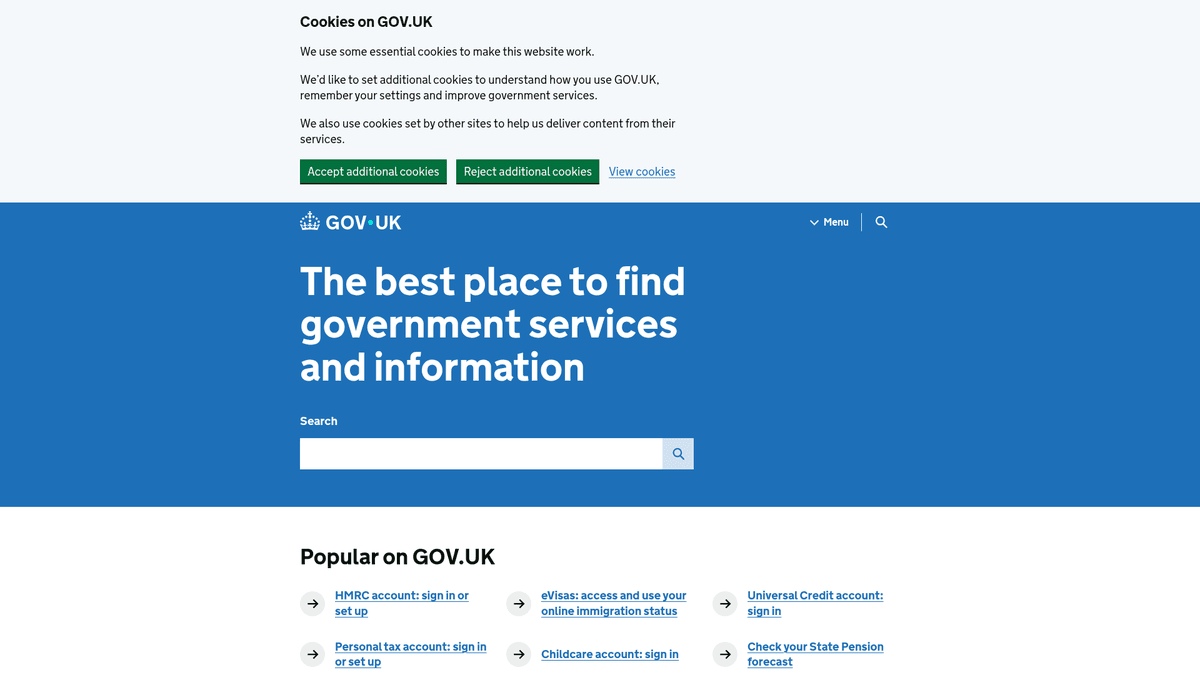
O GOV.UK
Odkryj, co oferuje GOV.UK i jakie cenne dane można wyodrębnić.
GOV.UK to centralny portal cyfrowy rządu Wielkiej Brytanii, zapewniający pojedynczy punkt dostępu do usług i informacji ze wszystkich departamentów i agencji. Stworzony przez Government Digital Service (GDS), zastąpił setki indywidualnych stron agencji jednolitym, przyjaznym dla użytkownika interfejsem zaprojektowanym z myślą o przejrzystości i wydajności.
Platforma zawiera ogromne repozytorium danych, w tym wytyczne legislacyjne, oficjalne statystyki, białe księgi polityki publicznej oraz ogłoszenia o zamówieniach. Ponieważ brytyjski rząd stosuje politykę 'domyślnie otwartych danych', większość informacji na GOV.UK jest publikowana na licencji Open Government Licence, co czyni portal prawdziwą skarbnicą wiedzy dla badaczy, firm prawniczych i przedsiębiorstw.
Scrapowanie GOV.UK jest niezwykle wartościowe dla monitorowania zmian w regulacjach, śledzenia wskaźników ekonomicznych i zbierania informacji o konkurencji z ogłoszeń o przetargach publicznych. Organizacje wykorzystują te dane do automatyzacji procesów compliance i wyprzedzania wydarzeń politycznych wpływających na ich branże.
Dlaczego Scrapować GOV.UK?
Odkryj wartość biznesową i przypadki użycia ekstrakcji danych z GOV.UK.
Monitorowanie aktualizacji w zakresie zgodności regulacyjnej
Śledzenie zmian w polityce w czasie rzeczywistym
Agregowanie danych ekonomicznych i statystycznych
Odkrywanie przetargów publicznych i możliwości kontraktowych
Archiwizowanie dokumentów prawnych i historycznych
Prowadzenie akademickich badań społeczno-ekonomicznych
Wyzwania Scrapowania
Wyzwania techniczne, które możesz napotkać podczas scrapowania GOV.UK.
Głęboko zagnieżdżona, hierarchiczna struktura stron
Duża liczba dokumentów i załączników PDF
Rygorystyczny rate limit wynoszący 3 000 żądań na 5 minut
Niewielkie różnice w układzie stron między różnymi departamentami
Scrapuj GOV.UK z AI
Bez kodowania. Wyodrębnij dane w kilka minut dzięki automatyzacji opartej na AI.
Jak to działa
Opisz, czego potrzebujesz
Powiedz AI, jakie dane chcesz wyodrębnić z GOV.UK. Po prostu wpisz to w języku naturalnym — bez kodu czy selektorów.
AI wyodrębnia dane
Nasza sztuczna inteligencja nawiguje po GOV.UK, obsługuje dynamiczną treść i wyodrębnia dokładnie to, o co prosiłeś.
Otrzymaj swoje dane
Otrzymaj czyste, ustrukturyzowane dane gotowe do eksportu jako CSV, JSON lub do bezpośredniego przesłania do twoich aplikacji.
Dlaczego warto używać AI do scrapowania
AI ułatwia scrapowanie GOV.UK bez pisania kodu. Nasza platforma oparta na sztucznej inteligencji rozumie, jakich danych potrzebujesz — po prostu opisz je w języku naturalnym, a AI wyodrębni je automatycznie.
How to scrape with AI:
- Opisz, czego potrzebujesz: Powiedz AI, jakie dane chcesz wyodrębnić z GOV.UK. Po prostu wpisz to w języku naturalnym — bez kodu czy selektorów.
- AI wyodrębnia dane: Nasza sztuczna inteligencja nawiguje po GOV.UK, obsługuje dynamiczną treść i wyodrębnia dokładnie to, o co prosiłeś.
- Otrzymaj swoje dane: Otrzymaj czyste, ustrukturyzowane dane gotowe do eksportu jako CSV, JSON lub do bezpośredniego przesłania do twoich aplikacji.
Why use AI for scraping:
- Konfiguracja no-code dla złożonej nawigacji
- Zaplanowane uruchomienia do monitorowania zmian w polityce
- Bezpośredni eksport do Google Sheets lub CSV
- Automatyczna ekstrakcja ukrytych linków do dokumentów
Scrapery No-Code dla GOV.UK
Alternatywy point-and-click dla scrapingu opartego na AI
Różne narzędzia no-code jak Browse.ai, Octoparse, Axiom i ParseHub mogą pomóc w scrapowaniu GOV.UK bez pisania kodu. Te narzędzia używają wizualnych interfejsów do wyboru danych, choć mogą mieć problemy ze złożoną dynamiczną zawartością lub zabezpieczeniami anti-bot.
Typowy Workflow z Narzędziami No-Code
Częste Wyzwania
Krzywa uczenia
Zrozumienie selektorów i logiki ekstrakcji wymaga czasu
Selektory się psują
Zmiany na stronie mogą zepsuć cały przepływ pracy
Problemy z dynamiczną treścią
Strony bogate w JavaScript wymagają złożonych obejść
Ograniczenia CAPTCHA
Większość narzędzi wymaga ręcznej interwencji przy CAPTCHA
Blokowanie IP
Agresywne scrapowanie może prowadzić do zablokowania IP
Scrapery No-Code dla GOV.UK
Różne narzędzia no-code jak Browse.ai, Octoparse, Axiom i ParseHub mogą pomóc w scrapowaniu GOV.UK bez pisania kodu. Te narzędzia używają wizualnych interfejsów do wyboru danych, choć mogą mieć problemy ze złożoną dynamiczną zawartością lub zabezpieczeniami anti-bot.
Typowy Workflow z Narzędziami No-Code
- Zainstaluj rozszerzenie przeglądarki lub zarejestruj się na platformie
- Przejdź do docelowej strony i otwórz narzędzie
- Wybierz elementy danych do wyodrębnienia metodą point-and-click
- Skonfiguruj selektory CSS dla każdego pola danych
- Ustaw reguły paginacji do scrapowania wielu stron
- Obsłuż CAPTCHA (często wymaga ręcznego rozwiązywania)
- Skonfiguruj harmonogram automatycznych uruchomień
- Eksportuj dane do CSV, JSON lub połącz przez API
Częste Wyzwania
- Krzywa uczenia: Zrozumienie selektorów i logiki ekstrakcji wymaga czasu
- Selektory się psują: Zmiany na stronie mogą zepsuć cały przepływ pracy
- Problemy z dynamiczną treścią: Strony bogate w JavaScript wymagają złożonych obejść
- Ograniczenia CAPTCHA: Większość narzędzi wymaga ręcznej interwencji przy CAPTCHA
- Blokowanie IP: Agresywne scrapowanie może prowadzić do zablokowania IP
Przykłady kodu
import requests
from bs4 import BeautifulSoup
# WSKAZÓWKA: Dodaj .json do wielu adresów URL GOV.UK, aby pobrać surowe dane
url = 'https://www.gov.uk/search/news-and-communications'
headers = {'User-Agent': 'ResearchBot/1.0 (contact@example.com)'}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
for item in soup.select('.gem-c-document-list__item'):
title = item.select_one('.gem-c-document-list__item-title').text.strip()
link = item.select_one('a')['href']
print(f'Aktualizacja: {title} | https://www.gov.uk{link}')
except Exception as e:
print(f'Błąd: {e}')Kiedy Używać
Najlepsze dla statycznych stron HTML z minimalnym JavaScript. Idealne dla blogów, serwisów informacyjnych i prostych stron produktowych e-commerce.
Zalety
- ●Najszybsze wykonanie (bez narzutu przeglądarki)
- ●Najniższe zużycie zasobów
- ●Łatwe do zrównoleglenia z asyncio
- ●Świetne dla API i stron statycznych
Ograniczenia
- ●Nie może wykonywać JavaScript
- ●Zawodzi na SPA i dynamicznej zawartości
- ●Może mieć problemy ze złożonymi systemami anti-bot
Jak scrapować GOV.UK za pomocą kodu
Python + Requests
import requests
from bs4 import BeautifulSoup
# WSKAZÓWKA: Dodaj .json do wielu adresów URL GOV.UK, aby pobrać surowe dane
url = 'https://www.gov.uk/search/news-and-communications'
headers = {'User-Agent': 'ResearchBot/1.0 (contact@example.com)'}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
for item in soup.select('.gem-c-document-list__item'):
title = item.select_one('.gem-c-document-list__item-title').text.strip()
link = item.select_one('a')['href']
print(f'Aktualizacja: {title} | https://www.gov.uk{link}')
except Exception as e:
print(f'Błąd: {e}')Python + Playwright
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
try:
page.goto('https://www.gov.uk/search/all?keywords=data+protection')
page.wait_for_selector('.gem-c-document-list__item')
titles = page.locator('.gem-c-document-list__item-title').all_text_contents()
for t in titles:
print(f'Wyodrębniono: {t.strip()}')
finally:
browser.close()Python + Scrapy
import scrapy
class GovSpider(scrapy.Spider):
name = 'gov_spider'
start_urls = ['https://www.gov.uk/search/news-and-communications']
def parse(self, response):
for article in response.css('.gem-c-document-list__item'):
yield {
'title': article.css('.gem-c-document-list__item-title::text').get().strip(),
'link': response.urljoin(article.css('a::attr(href)').get())
}
next_page = response.css('a[rel="next"]::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
try {
await page.goto('https://www.gov.uk/search/news-and-communications', { waitUntil: 'networkidle2' });
const results = await page.evaluate(() =>
Array.from(document.querySelectorAll('.gem-c-document-list__item-title'))
.map(el => el.innerText.trim())
);
console.log(results);
} finally {
await browser.close();
}
})();Co Możesz Zrobić Z Danymi GOV.UK
Poznaj praktyczne zastosowania i wnioski z danych GOV.UK.
System alertów regulacyjnych
Zespoły prawne i ds. zgodności mogą monitorować specyficzne kategorie wytycznych, aby natychmiast wykrywać zmiany w prawie.
Jak wdrożyć:
- 1Codziennie scrapuj sekcję 'Guidance and Regulation'.
- 2Wyodrębnij tekst dokumentów i znaczniki czasu ostatniej aktualizacji.
- 3Porównaj treść z poprzednimi wersjami, aby wyróżnić różnice (diffs).
- 4Wysyłaj automatyczne alerty do odpowiednich interesariuszy wewnętrznych.
Użyj Automatio do wyodrębnienia danych z GOV.UK i budowania tych aplikacji bez pisania kodu.
Co Możesz Zrobić Z Danymi GOV.UK
- System alertów regulacyjnych
Zespoły prawne i ds. zgodności mogą monitorować specyficzne kategorie wytycznych, aby natychmiast wykrywać zmiany w prawie.
- Codziennie scrapuj sekcję 'Guidance and Regulation'.
- Wyodrębnij tekst dokumentów i znaczniki czasu ostatniej aktualizacji.
- Porównaj treść z poprzednimi wersjami, aby wyróżnić różnice (diffs).
- Wysyłaj automatyczne alerty do odpowiednich interesariuszy wewnętrznych.
- Monitor ofert przetargowych
Zespoły sprzedaży mogą scrapować ogłoszenia o zamówieniach, aby znajdować nowe możliwości kontraktowe w sektorze rządowym.
- Obierz za cel kategorię wyszukiwania 'Procurement' na GOV.UK.
- Scrapuj daty zakończenia, adresy e-mail do kontaktu i wartości kontraktów.
- Filtruj wyniki według słów kluczowych istotnych dla Twojej branży.
- Importuj leady bezpośrednio do systemu CRM w celu dalszego kontaktu.
- Analiza trendów ekonomicznych
Ekonomiści mogą agregować publikacje statystyczne do badań długofalowych nad kondycją Wielkiej Brytanii.
- Zidentyfikuj adresy URL serii danych statystycznych.
- Scrapuj bezpośrednie linki do plików CSV lub Excel.
- Pobieraj i czyść zestawy danych za pomocą automatycznych skryptów.
- Scalaj dane w scentralizowanej bazie danych w celu wizualizacji.
- Archiwum polityki publicznej
Dziennikarze i badacze mogą stworzyć przeszukiwalne archiwum oficjalnych komunikatów rządowych.
- Stale scrapuj sekcję 'News and Communications'.
- Wyodrębnij nagłówki, treść artykułów i tagi departamentów.
- Indeksuj dane w platformie wyszukiwawczej, takiej jak Elasticsearch.
- Analizuj sentyment i częstotliwość występowania konkretnych słów kluczowych dotyczących polityki.
- Zautomatyzowane boty doradcze
Organizacje non-profit mogą wykorzystywać oficjalne wytyczne do zasilania chatbotów pomagających obywatelom w uzyskaniu informacji o świadczeniach.
- Scrapuj strony z wytycznymi dotyczącymi zasiłków i mieszkalnictwa.
- Zmapuj wyodrębniony tekst do bazy wektorowej dla RAG (Retrieval-Augmented Generation).
- Ustaw wyzwalacz, aby odświeżać bazę danych po zmianie treści na GOV.UK.
- Udzielaj użytkownikom dokładnych odpowiedzi w czasie rzeczywistym.
- Wyszukiwarka grantów
Instytucje edukacyjne mogą znajdować możliwości uzyskania grantów i finansowania projektów badawczych.
- Scrapuj kategorię finansowania 'Education, Training and Skills'.
- Wyodrębnij kryteria kwalifikowalności i terminy składania wniosków.
- Kategoryzuj dotacje według departamentów i kwot finansowania.
- Automatyzuj cotygodniowe podsumowania e-mailowe dla pracowników naukowych.
Przyspiesz swoj workflow z automatyzacja AI
Automatio laczy moc agentow AI, automatyzacji web i inteligentnych integracji, aby pomoc Ci osiagnac wiecej w krotszym czasie.
Profesjonalne Porady dla Scrapowania GOV.UK
Porady ekspertów dotyczące skutecznej ekstrakcji danych z GOV.UK.
Dodaj rozszerzenie '.json' do niemal każdego adresu URL GOV.UK, aby uzyskać powiązane metadane bez konieczności parsowania HTML.
Identyfikuj elementy za pomocą klas CSS zaczynających się od 'gem-c-', ponieważ są one częścią standardowego systemu GDS Design System.
Ustaw opisowy ciąg User-Agent zawierający Twój adres e-mail, aby GDS mógł się z Tobą skontaktować, jeśli Twój bot będzie powodował problemy.
Trzymaj się poniżej limitu rate limit wynoszącego 3 000 żądań na 5 minut, aby uniknąć tymczasowych blokad IP.
Skup się na stronach 'Search' przy wyszukiwaniu na dużą skalę, ponieważ oferują one przejrzyste, stronicowane listy dokumentów.
Sprawdzaj znacznik czasu 'Last Updated', aby uniknąć ponownego scrapowania niezmienionej zawartości.
Opinie
Co mowia nasi uzytkownicy
Dolacz do tysiecy zadowolonych uzytkownikow, ktorzy przeksztalcili swoj workflow
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Powiazane Web Scraping
Często Zadawane Pytania o GOV.UK
Znajdź odpowiedzi na częste pytania o GOV.UK