Jak scrapować USPTO.gov | Scraper patentów i znaków towarowych USPTO
Dowiedz się, jak scrapować USPTO.gov w celu pozyskania danych o patentach i znakach towarowych. Ekstrahuj numery patentów, wynalazców i daty zgłoszeń dla celów...
Wykryto ochronę przed botami
- Cloudflare
- Korporacyjny WAF i zarządzanie botami. Używa wyzwań JavaScript, CAPTCHA i analizy behawioralnej. Wymaga automatyzacji przeglądarki z ustawieniami stealth.
- Ograniczanie szybkości
- Ogranicza liczbę żądań na IP/sesję w czasie. Można obejść za pomocą rotacyjnych proxy, opóźnień żądań i rozproszonego scrapingu.
- Blokowanie IP
- Blokuje znane IP centrów danych i oznaczone adresy. Wymaga rezydencjalnych lub mobilnych proxy do skutecznego obejścia.
- Session-based URLs
- Google reCAPTCHA
- System CAPTCHA Google. v2 wymaga interakcji użytkownika, v3 działa cicho z oceną ryzyka. Można rozwiązać za pomocą usług CAPTCHA.
O USPTO (United States Patent and Trademark Office)
Odkryj, co oferuje USPTO (United States Patent and Trademark Office) i jakie cenne dane można wyodrębnić.
United States Patent and Trademark Office (USPTO) to agencja federalna odpowiedzialna za przyznawanie patentów w USA i rejestrację znaków towarowych. Utrzymuje ona ogromną publiczną bazę danych rekordów własności intelektualnej (IP), dokumentującą innowacje i własność marek od 1790 roku. Witryna zawiera złożone portale wyszukiwania, takie jak TSDR (Trademark Status & Document Retrieval) oraz narzędzie Patent Public Search.
Dane z USPTO stanowią złoty standard w badaniach nad własnością intelektualną. Zawierają one szczegółowe informacje na temat wynalazków, technicznych zastrzeżeń (claims), cesji prawnych i identyfikatorów marek. Dla firm i prawników dane te mają kluczowe znaczenie dla weryfikacji ważności IP, przeprowadzania due diligence podczas przejęć oraz identyfikowania pojawiających się trendów technologicznych, zanim trafią one na rynek masowy.
Scraping USPTO jest niezwykle cenny dla firm z sektora legal tech, działów R&D oraz analityków rynkowych. Pozwala na automatyzację monitorowania konkurencji, śledzenie cyklu życia wniosków o znaki towarowe i budowanie kompleksowych zbiorów danych do analizy krajobrazu patentowego.
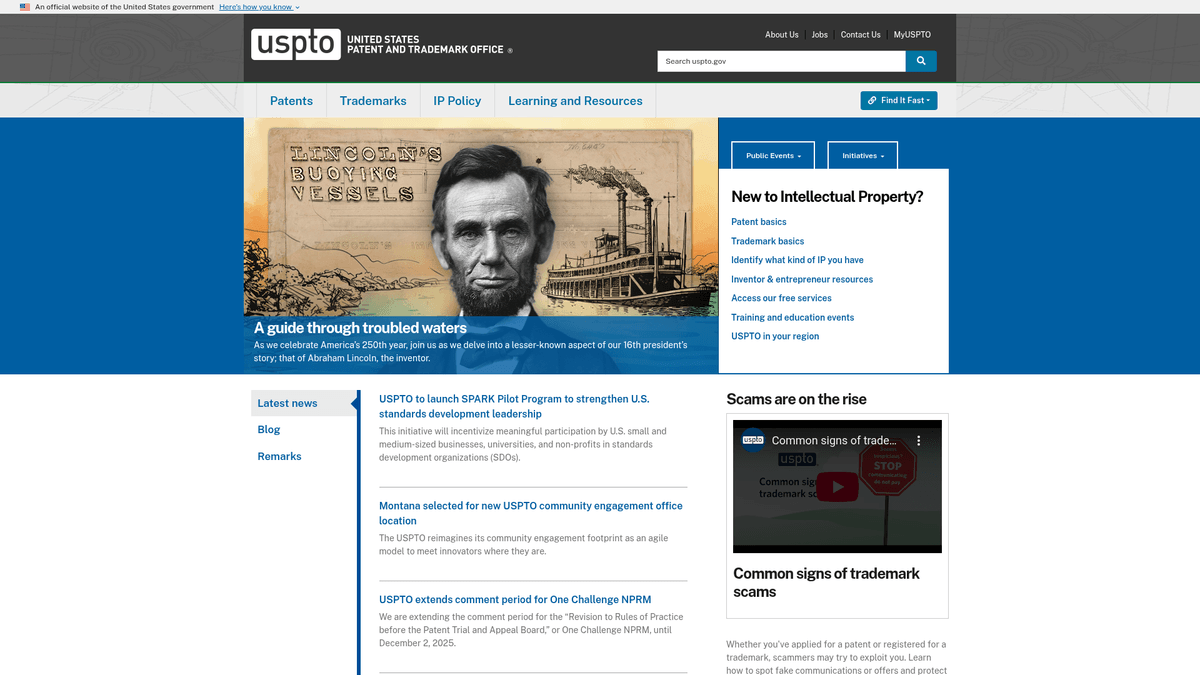
Dlaczego Scrapować USPTO (United States Patent and Trademark Office)?
Odkryj wartość biznesową i przypadki użycia ekstrakcji danych z USPTO (United States Patent and Trademark Office).
Monitorowanie zgłoszeń patentowych konkurencji dla strategii R&D
Śledzenie nowych wniosków o znaki towarowe w celu ochrony marki
Przeprowadzanie badań czystości patentowej (freedom-to-operate - FTO)
Analiza krajobrazu patentowego w celu identyfikacji luk rynkowych
Gromadzenie danych do due diligence prawnego i wyceny
Budowanie akademickich zbiorów danych dla badań nad innowacyjnością
Wyzwania Scrapowania
Wyzwania techniczne, które możesz napotkać podczas scrapowania USPTO (United States Patent and Trademark Office).
Wysoce dynamiczne interfejsy wyszukiwania wymagające wykonywania kodu JS
Agresywne rate limiting dla zapytań wyszukiwania
Adresy URL specyficzne dla sesji, które szybko wygasają
Złożone, głęboko zagnieżdżone tabele HTML
Częste aktualizacje struktury w starszych systemach rządowych
Scrapuj USPTO (United States Patent and Trademark Office) z AI
Bez kodowania. Wyodrębnij dane w kilka minut dzięki automatyzacji opartej na AI.
Jak to działa
Opisz, czego potrzebujesz
Powiedz AI, jakie dane chcesz wyodrębnić z USPTO (United States Patent and Trademark Office). Po prostu wpisz to w języku naturalnym — bez kodu czy selektorów.
AI wyodrębnia dane
Nasza sztuczna inteligencja nawiguje po USPTO (United States Patent and Trademark Office), obsługuje dynamiczną treść i wyodrębnia dokładnie to, o co prosiłeś.
Otrzymaj swoje dane
Otrzymaj czyste, ustrukturyzowane dane gotowe do eksportu jako CSV, JSON lub do bezpośredniego przesłania do twoich aplikacji.
Dlaczego warto używać AI do scrapowania
AI ułatwia scrapowanie USPTO (United States Patent and Trademark Office) bez pisania kodu. Nasza platforma oparta na sztucznej inteligencji rozumie, jakich danych potrzebujesz — po prostu opisz je w języku naturalnym, a AI wyodrębni je automatycznie.
How to scrape with AI:
- Opisz, czego potrzebujesz: Powiedz AI, jakie dane chcesz wyodrębnić z USPTO (United States Patent and Trademark Office). Po prostu wpisz to w języku naturalnym — bez kodu czy selektorów.
- AI wyodrębnia dane: Nasza sztuczna inteligencja nawiguje po USPTO (United States Patent and Trademark Office), obsługuje dynamiczną treść i wyodrębnia dokładnie to, o co prosiłeś.
- Otrzymaj swoje dane: Otrzymaj czyste, ustrukturyzowane dane gotowe do eksportu jako CSV, JSON lub do bezpośredniego przesłania do twoich aplikacji.
Why use AI for scraping:
- Obsługuje złożone portale wyszukiwania JavaScript bez kodowania
- Automatycznie zarządza ciasteczkami sesyjnymi i dynamicznymi timeoutami
- Zaplanowane przebiegi do automatycznego wykrywania nowych zgłoszeń
- Łatwo ekstrahuje rysunki patentowe i logo znaków towarowych
- Transformuje nieuporządkowane tabele rządowe w czysty format CSV lub JSON
Scrapery No-Code dla USPTO (United States Patent and Trademark Office)
Alternatywy point-and-click dla scrapingu opartego na AI
Różne narzędzia no-code jak Browse.ai, Octoparse, Axiom i ParseHub mogą pomóc w scrapowaniu USPTO (United States Patent and Trademark Office) bez pisania kodu. Te narzędzia używają wizualnych interfejsów do wyboru danych, choć mogą mieć problemy ze złożoną dynamiczną zawartością lub zabezpieczeniami anti-bot.
Typowy Workflow z Narzędziami No-Code
Częste Wyzwania
Krzywa uczenia
Zrozumienie selektorów i logiki ekstrakcji wymaga czasu
Selektory się psują
Zmiany na stronie mogą zepsuć cały przepływ pracy
Problemy z dynamiczną treścią
Strony bogate w JavaScript wymagają złożonych obejść
Ograniczenia CAPTCHA
Większość narzędzi wymaga ręcznej interwencji przy CAPTCHA
Blokowanie IP
Agresywne scrapowanie może prowadzić do zablokowania IP
Scrapery No-Code dla USPTO (United States Patent and Trademark Office)
Różne narzędzia no-code jak Browse.ai, Octoparse, Axiom i ParseHub mogą pomóc w scrapowaniu USPTO (United States Patent and Trademark Office) bez pisania kodu. Te narzędzia używają wizualnych interfejsów do wyboru danych, choć mogą mieć problemy ze złożoną dynamiczną zawartością lub zabezpieczeniami anti-bot.
Typowy Workflow z Narzędziami No-Code
- Zainstaluj rozszerzenie przeglądarki lub zarejestruj się na platformie
- Przejdź do docelowej strony i otwórz narzędzie
- Wybierz elementy danych do wyodrębnienia metodą point-and-click
- Skonfiguruj selektory CSS dla każdego pola danych
- Ustaw reguły paginacji do scrapowania wielu stron
- Obsłuż CAPTCHA (często wymaga ręcznego rozwiązywania)
- Skonfiguruj harmonogram automatycznych uruchomień
- Eksportuj dane do CSV, JSON lub połącz przez API
Częste Wyzwania
- Krzywa uczenia: Zrozumienie selektorów i logiki ekstrakcji wymaga czasu
- Selektory się psują: Zmiany na stronie mogą zepsuć cały przepływ pracy
- Problemy z dynamiczną treścią: Strony bogate w JavaScript wymagają złożonych obejść
- Ograniczenia CAPTCHA: Większość narzędzi wymaga ręcznej interwencji przy CAPTCHA
- Blokowanie IP: Agresywne scrapowanie może prowadzić do zablokowania IP
Przykłady kodu
import requests
from bs4 import BeautifulSoup
# Uwaga: Dane bulk są łatwiejsze przy dużych wolumenach
url = 'https://bulkdata.uspto.gov/'
headers = {'User-Agent': 'Mozilla/5.0'}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Znajdowanie linków do cotygodniowych plików zip z patentami
links = [a['href'] for a in soup.find_all('a', href=True) if '.zip' in a['href']]
print(f'Znaleziono {len(links)} zestawów danych gotowych do pobrania')
except Exception as e:
print(f'Błąd: {e}')Kiedy Używać
Najlepsze dla statycznych stron HTML z minimalnym JavaScript. Idealne dla blogów, serwisów informacyjnych i prostych stron produktowych e-commerce.
Zalety
- ●Najszybsze wykonanie (bez narzutu przeglądarki)
- ●Najniższe zużycie zasobów
- ●Łatwe do zrównoleglenia z asyncio
- ●Świetne dla API i stron statycznych
Ograniczenia
- ●Nie może wykonywać JavaScript
- ●Zawodzi na SPA i dynamicznej zawartości
- ●Może mieć problemy ze złożonymi systemami anti-bot
Jak scrapować USPTO (United States Patent and Trademark Office) za pomocą kodu
Python + Requests
import requests
from bs4 import BeautifulSoup
# Uwaga: Dane bulk są łatwiejsze przy dużych wolumenach
url = 'https://bulkdata.uspto.gov/'
headers = {'User-Agent': 'Mozilla/5.0'}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Znajdowanie linków do cotygodniowych plików zip z patentami
links = [a['href'] for a in soup.find_all('a', href=True) if '.zip' in a['href']]
print(f'Znaleziono {len(links)} zestawów danych gotowych do pobrania')
except Exception as e:
print(f'Błąd: {e}')Python + Playwright
from playwright.sync_api import sync_playwright
def scrape_uspto_trademark():
with sync_playwright() as p:
# USPTO wymaga realnego fingerprintu przeglądarki, aby uniknąć triggerów Cloudflare
browser = p.chromium.launch(headless=True)
page = browser.new_page()
# Nawigacja do strony statusu TSDR
page.goto('https://tsdr.uspto.gov/')
# Wpisanie numeru seryjnego (Przykład: 98021018)
page.fill('#caseNumber', '98021018')
page.click('#statusSearch')
# Czekanie na wyrenderowanie sekcji statusu przez JS
page.wait_for_selector('.status-info')
# Ekstrakcja danych ze strony
mark_name = page.inner_text('.mark-name')
print(f'Trademark Name: {mark_name}')
browser.close()
scrape_uspto_trademark()Python + Scrapy
import scrapy
class UsptoSpider(scrapy.Spider):
name = 'uspto_spider'
# Celowanie w katalog Patent Grant Red Book
start_urls = ['https://bulkdata.uspto.gov/data/patent/grant/redbook/2024/']
def parse(self, response):
# Scrapowanie wszystkich linków do plików zip dla roku 2024
for file_link in response.css('a::attr(href)').getall():
if file_link.endswith('.zip'):
yield {
'file_url': response.urljoin(file_link),
'year': 2024
}
# Tutaj można dodać logikę przechodzenia przez katalogiNode.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
// Dostęp do strony głównej Patent Public Search
await page.goto('https://ppubs.uspto.gov/pubwebapp/static/pages/landing.html');
// Czekanie na pojawienie się przycisku 'Basic Search'
await page.waitForSelector('#basic-search-button');
await page.click('#basic-search-button');
// Dodatkowa logika do wprowadzania zapytań i czekania na dynamiczne tabele
await page.waitForSelector('.result-item');
const results = await page.evaluate(() => {
return Array.from(document.querySelectorAll('.patent-title')).map(el => el.innerText);
});
console.log('Scraped Titles:', results);
await browser.close();
})();Co Możesz Zrobić Z Danymi USPTO (United States Patent and Trademark Office)
Poznaj praktyczne zastosowania i wnioski z danych USPTO (United States Patent and Trademark Office).
Konkurencyjne monitorowanie marek
Sprzedawcy i właściciele marek mogą monitorować nowe zgłoszenia znaków towarowych, aby chronić się przed naruszeniami i wejściem konkurencji na rynek.
Jak wdrożyć:
- 1Scrapuj cotygodniowe zgłoszenia znaków towarowych pod kątem określonych słów kluczowych związanych z Twoją marką.
- 2Porównuj nowe zgłoszenia z istniejącymi znakami towarowymi i wzorami.
- 3Alertuj zespoły prawne, gdy podobne znaki zostaną zgłoszone w odpowiednich klasach towarowych (IC classes).
Użyj Automatio do wyodrębnienia danych z USPTO (United States Patent and Trademark Office) i budowania tych aplikacji bez pisania kodu.
Co Możesz Zrobić Z Danymi USPTO (United States Patent and Trademark Office)
- Konkurencyjne monitorowanie marek
Sprzedawcy i właściciele marek mogą monitorować nowe zgłoszenia znaków towarowych, aby chronić się przed naruszeniami i wejściem konkurencji na rynek.
- Scrapuj cotygodniowe zgłoszenia znaków towarowych pod kątem określonych słów kluczowych związanych z Twoją marką.
- Porównuj nowe zgłoszenia z istniejącymi znakami towarowymi i wzorami.
- Alertuj zespoły prawne, gdy podobne znaki zostaną zgłoszone w odpowiednich klasach towarowych (IC classes).
- Mapowanie trendów innowacji
Laboratoria R&D mogą analizować przyznane patenty, aby sprawdzić, w które technologie globalne korporacje inwestują najwięcej.
- Scrapuj abstrakty patentowe i kategorie w kroczącym okresie 5 lat.
- Użyj NLP, aby zidentyfikować trendujące słowa kluczowe i klasyfikacje CPC.
- Wizualizuj wzrost konkretnych sektorów technologicznych, takich jak AI, biotechnologia czy zielona energia.
- Due Diligence w Legal Tech
Kancelarie prawne mogą zautomatyzować gromadzenie całego portfela IP danego podmiotu na potrzeby fuzji i przejęć (M&A) oraz wycen.
- Wprowadź listę nazw firm lub identyfikatorów cesjonariuszy do scrapera.
- Wyodrębnij wszystkie aktywne rekordy patentowe i znaki towarowe dla tych podmiotów, w tym daty wygaśnięcia.
- Generuj raport na temat siły, różnorodności i terminów odnowienia aktywów.
- Lead Generation dla usług IP
Rzecznicy patentowi mogą identyfikować nowych zgłaszających, którzy mogą potrzebować specjalistycznych usług w zakresie rzecznictwa patentowego lub znaków towarowych.
- Filtruj nowe wnioski o znaki towarowe bez wskazanego pełnomocnika.
- Wyodrębnij dane kontaktowe korespondenta i szczegóły właściciela.
- Prowadź ukierunkowane działania outreach w celu oferowania reprezentacji prawnej lub usług zarządzania odnowieniami.
Przyspiesz swoj workflow z automatyzacja AI
Automatio laczy moc agentow AI, automatyzacji web i inteligentnych integracji, aby pomoc Ci osiagnac wiecej w krotszym czasie.
Profesjonalne Porady dla Scrapowania USPTO (United States Patent and Trademark Office)
Porady ekspertów dotyczące skutecznej ekstrakcji danych z USPTO (United States Patent and Trademark Office).
Priorytetyzuj Bulk Data Storage System (BDSS) przy zapotrzebowaniu na dane o dużej skali, aby uniknąć zablokowania na głównym portalu wyszukiwania.
Używaj headless browser, takich jak Playwright, do obsługi złożonego JavaScriptu i stanów sesji wymaganych przez nowoczesne portale.
Monitoruj harmonogram prac konserwacyjnych USPTO, ponieważ bazy danych często przechodzą w tryb offline w celu aktualizacji w weekendy.
Rotuj residential proxies, aby ominąć rygorystyczne rate limits zapytań wyszukiwania i Cloudflare challenges.
Wyodrębniaj adresy URL obrazów dokumentów, aby uzyskać oryginalne pliki TIFF lub PDF zgłoszeń urzędowych w wysokiej rozdzielczości.
Parsuj pliki XML z portalu bulk, jeśli potrzebujesz technicznych zastrzeżeń (claims), ponieważ interfejs webowy często skraca tekst.
Opinie
Co mowia nasi uzytkownicy
Dolacz do tysiecy zadowolonych uzytkownikow, ktorzy przeksztalcili swoj workflow
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Powiazane Web Scraping
Często Zadawane Pytania o USPTO (United States Patent and Trademark Office)
Znajdź odpowiedzi na częste pytania o USPTO (United States Patent and Trademark Office)