
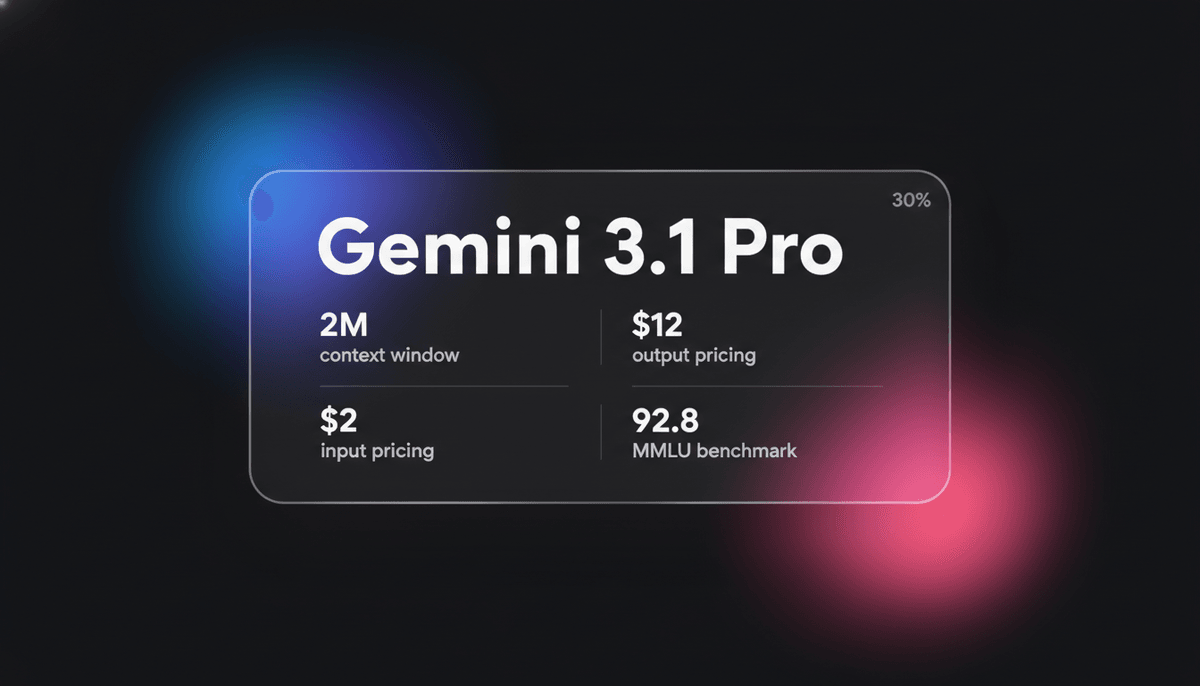
Gemini 3.1 Pro
Gemini 3.1 Pro to elitarny model multimodal od Google z silnikiem rozumowania DeepThink, 1M+ context window i wiodącymi w branży wynikami logicznymi ARC-AGI.
O Gemini 3.1 Pro
Dowiedz sie o mozliwosciach Gemini 3.1 Pro, funkcjach i jak moze pomoc Ci osiagnac lepsze wyniki.
Gemini 3.1 Pro stanowi dojrzałą implementację architektury Sparse Mixture-of-Experts (MoE), natywnie połączoną z zaawansowanym silnikiem przetwarzania multimodal. Cechą wyróżniającą jest demokratyzacja warstwy DeepThink System 2, która pozwala modelowi deliberować wewnętrznie przed wygenerowaniem tokena wyjściowego. Model wprowadza unikalny system trzech poziomów myślenia: Low, Medium i High, umożliwiając deweloperom bezpośrednią kontrolę nad balansem między latency, kosztem a głębią reasoning.
Dzięki ogromnemu 1-milionowemu context window, Gemini 3.1 Pro jest wysoce zoptymalizowany pod kątem złożonych procesów w finansach, analityce danych i migracjach całych repozytoriów kodu. Wykazuje wyłaniającą się zdolność do rozwiązywania nowatorskich wzorców logicznych, osiągając bezprecedensowe 77,1% w benchmarku ARC-AGI-2. Dzięki temu jest to preferowany wybór dla deweloperów, którzy wymagają zarówno niskiej latency w interakcjach multimodal, jak i wysokiej wydajności poznawczej w zadaniach agentic.
Przypadki uzycia dla Gemini 3.1 Pro
Odkryj rozne sposoby wykorzystania Gemini 3.1 Pro do osiagniecia swietnych wynikow.
Analiza całych repozytoriów kodu
Wykorzystanie 1M context window do wczytania całych projektów software'owych w celu refaktoryzacji i mapowania zależności.
Autonomiczne komitety agentów
Kierowanie wieloetapowymi procesami agentic, w których wewnętrzne pod-agenty dyskutują i weryfikują rozwiązania przed wykonaniem.
Synteza badań naukowych
Analiza tysięcy publikacji naukowych i złożonych zbiorów danych w celu ekstrakcji ustrukturyzowanej wiedzy i faktów.
Multimodalne tworzenie treści
Jednoczesne przetwarzanie tekstu, obrazów i audio w celu generowania złożonych materiałów instruktażowych i interaktywnych mediów.
Automatyzacja w terminalu
Precyzyjne wykonywanie złożonych poleceń bash i manipulacja systemem plików dzięki zaawansowanym trybom reasoning.
Audyt danych korporacyjnych
Analiza nieustrukturyzowanych danych finansowych i dokumentów prawnych w celu wykrywania luk w compliance z niemal perfekcyjną pamięcią faktów.
Mocne strony
Ograniczenia
Szybki start API
google/gemini-3.1-pro-preview
import { GoogleGenAI } from "@google/genai";
const genAI = new GoogleGenAI(process.env.GOOGLE_API_KEY);
const model = genAI.getGenerativeModel({
model: "gemini-3.1-pro-preview",
thinkingConfig: { tier: "high" }
});
const prompt = "Przeanalizuj cały ten codebase pod kątem luk w zabezpieczeniach.";
const result = await model.generateContent(prompt);
console.log(result.response.text());Zainstaluj SDK i zacznij wykonywac wywolania API w kilka minut.
Co mowia ludzie o Gemini 3.1 Pro
Zobacz, co spolecznosc mysli o Gemini 3.1 Pro
“Wynik 77,1% w Gemini 3.1 Pro to najbardziej przełomowa zmiana na rynku; podwaja poprzedni najlepszy wynik w ARC-AGI.”
“Benchmarki kodowania nie kłamią. Ten model znalazł błąd w moim repo, który 3.5 i GPT-4o całkowicie pominęły.”
“Całe zamieszanie wokół Gemini 3.1 jest fascynujące. Zmiażdżył benchmarki, ale użytkownicy twierdzą, że ton i vibe są niespójne.”
“Silnik DeepThink może powodować spore opóźnienia, czasami powyżej 90 sekund, przy zadaniach wymagających głębokiej logiki.”
“Context caching to zabójcza funkcja. Uruchamiam całego bota z dokumentacją za grosze w porównaniu do GPT-4o.”
“Gemini w ogóle nie omówiło Pythona w złożonym zadaniu planowania... pewna logika po prostu nie była obecna w planie końcowym.”
Filmy o Gemini 3.1 Pro
Ogladaj samouczki, recenzje i dyskusje o Gemini 3.1 Pro
“Gemini 3.1 Pro generuje jak dotąd najbardziej szczegółową wersję tej pagody”
“Gemini ma zdecydowanie najszersze okno kontekstowe, bo aż milion tokenów”
“Wierność multimodal w przetwarzaniu audio jest zauważalnie lepsza niż w 3.0”
“Throughput tokenów pozostaje stabilny, nawet gdy context window jest zapełnione”
“Długoterminowa pamięć jest właściwie perfekcyjna w całym milionie tokenów”
“W zagadkach, których nie powinno być w zbiorze treningowym, seria Gemini 3 przewyższa wszystkie inne modele”
“3.1 Pro faktycznie może skrócić czas wykonywania skryptu fine-tuning z 300 do 47 sekund”
“Kroki logiki DeepThink są wyraźnie widoczne w logach, pokazując prawdziwe deliberowanie”
“Osiągamy nasycenie benchmarków, gdzie tylko ARC-AGI naprawdę liczy się w postępie”
“Trajektoria AGI przyspiesza dzięki tym skokom w abstract reasoning”
“Uważam, że 3.1 faktycznie sprawia wrażenie kroku naprzód, nawet jeśli jest on bardzo mały”
“Wydaje się, że przewyższa Gemini 3.0 Pro, gdy testujemy te same prompty obok siebie”
“Dokładność kodowania przy złożonych refaktoryzacjach Python jest najlepsza, jaką widziałem”
“Niezawodność API znacząco się poprawiła w ciągu ostatniego miesiąca testów”
“Wydajność w świecie rzeczywistym wreszcie odpowiada szumowi wokół wyników benchmarków”
Przyspiesz swoj workflow z automatyzacja AI
Automatio laczy moc agentow AI, automatyzacji web i inteligentnych integracji, aby pomoc Ci osiagnac wiecej w krotszym czasie.
Porady Pro dla Gemini 3.1 Pro
Wskazówki ekspertów, aby w pełni wykorzystać Gemini 3.1 Pro.
Wybór poziomu reasoning
Używaj trybu High dla złożonych zadań matematycznych lub logicznych, ale przełączaj na Low przy standardowym formatowaniu, aby zaoszczędzić na kosztach.
Context Caching
Wdróż context caching dla statycznej dokumentacji, aby zredukować ceny wejściowe nawet o 90% za milion tokenów.
Strukturyzowane artefakty
Wykorzystaj zdolność modelu do generowania ustrukturyzowanych list zadań w celu łatwiejszego nadzoru ludzkiego podczas pracy agentic.
Multimodal prompt
Łącz wideo i audio, aby dostarczyć modelowi pełny kontekst scenariuszy ze świata rzeczywistego, zamiast ograniczać się tylko do opisu tekstowego.
Opinie
Co mowia nasi uzytkownicy
Dolacz do tysiecy zadowolonych uzytkownikow, ktorzy przeksztalcili swoj workflow
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Powiazane AI Models
Claude Opus 4.7
Anthropic
Claude Opus 4.7 is Anthropic's flagship model with a 1-million-token context, adaptive reasoning, and 3.3x vision resolution for enterprise-scale agents.
Gemini 3.1 Flash Live Preview
Gemini 3.1 Flash Live Preview is Google's ultra-low-latency, audio-to-audio model featuring a 131K context window, high-fidelity multimodal reasoning, and...
GPT-5.5
OpenAI
GPT-5.5 is OpenAI's flagship frontier model with a 1M context window and five reasoning effort levels, optimized for autonomous agentic workflows and coding.
Grok-3
xAI
Grok-3 is xAI's flagship reasoning model, featuring deep logic deduction, a 128k context window, and real-time integration with X for live research and coding.
Kimi K3
Moonshot
Kimi K3 is Moonshot AI's 2.8T MoE model with a 1M token context window, native multimodal vision, and frontier-tier coding performance for complex agents.
GPT-5.2 Pro
OpenAI
GPT-5.2 Pro is OpenAI's 2025 flagship reasoning model featuring Extended Thinking for SOTA performance in mathematics, coding, and expert knowledge work.
Qwen 3.7 Max
alibaba
Qwen 3.7 Max is Alibaba’s flagship AI model for deep reasoning and autonomous agent tasks, featuring a 256k context window and top-tier coding performance.
Gemini 3 Pro
Google's Gemini 3 Pro is a multimodal powerhouse featuring a 1M token context window, native video processing, and industry-leading reasoning performance.
Często Zadawane Pytania o Gemini 3.1 Pro
Znajdź odpowiedzi na częste pytania o Gemini 3.1 Pro