
Gemini 3.1 Pro
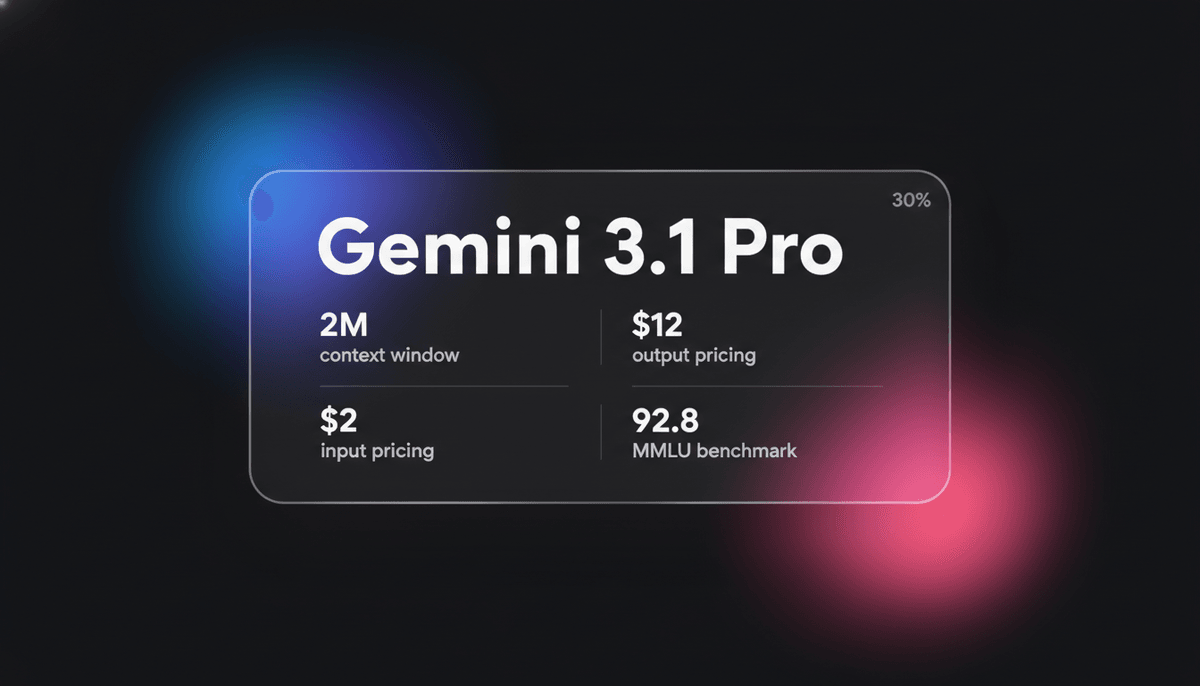
O Gemini 3.1 Pro é o model multimodal de elite do Google, com motor de reasoning DeepThink, context window de 1M+ e pontuações de lógica ARC-AGI líderes da...
Sobre Gemini 3.1 Pro
Aprenda sobre as capacidades do Gemini 3.1 Pro, recursos e como ele pode ajuda-lo a obter melhores resultados.
O Gemini 3.1 Pro representa uma execução madura do framework Sparse Mixture-of-Experts (MoE), nativamente emparelhado com um motor de processamento multimodal avançado. O destaque da arquitetura é a democratização da camada DeepThink System 2, que permite ao model deliberar internamente antes de se comprometer com um token de saída. Este model introduz um sistema de pensamento exclusivo de três níveis (Baixo, Médio e Alto), permitindo que os desenvolvedores controlem explicitamente a troca entre latency, custo e profundidade de reasoning.
Com uma context window massiva de 1 milhão de tokens, o Gemini 3.1 Pro é altamente otimizado para fluxos de trabalho complexos em finanças, análise de dados e migrações de código de repositório inteiro. Ele demonstra uma capacidade emergente de resolver novos padrões lógicos, pontuando 77,1% sem precedentes no benchmark ARC-AGI-2. Isso o torna a escolha preferida para desenvolvedores que exigem interações multimodais de baixa latency e desempenho cognitivo de alto nível para tarefas agentic autônomas.
Casos de Uso para Gemini 3.1 Pro
Descubra as diferentes maneiras de usar Gemini 3.1 Pro para obter otimos resultados.
Análise de Código de Repositório Completo
Utilizando a context window de 1M para processar repositórios de software inteiros para refatoração e mapeamento de dependências.
Comitês de Agentes Autônomos
Conduzindo fluxos de trabalho agentic de várias etapas onde sub-agentes internos debatem e verificam soluções antes da execução.
Síntese de Pesquisa Científica
Analisando milhares de artigos de pesquisa e conjuntos de dados complexos para extrair inteligência estruturada e insights factuais.
Criação de Conteúdo Multimodal
Processando simultaneamente texto, imagens e áudio para gerar materiais instrucionais complexos e mídia interativa.
Automação Baseada em Terminal
Executando comandos bash complexos e manipulando sistemas de arquivos com alta precisão via modos de reasoning avançados.
Auditoria de Dados Corporativos
Analisando dados financeiros não estruturados e documentos legais para identificar lacunas de conformidade com recall factual quase perfeito.
Pontos Fortes
Limitacoes
Inicio Rapido da API
google/gemini-3.1-pro-preview
import { GoogleGenAI } from "@google/genai";
const genAI = new GoogleGenAI(process.env.GOOGLE_API_KEY);
const model = genAI.getGenerativeModel({
model: "gemini-3.1-pro-preview",
thinkingConfig: { tier: "high" }
});
const prompt = "Analyze this entire codebase for security vulnerabilities.";
const result = await model.generateContent(prompt);
console.log(result.response.text());Instale o SDK e comece a fazer chamadas de API em minutos.
O Que as Pessoas Estao Dizendo Sobre Gemini 3.1 Pro
Veja o que a comunidade pensa sobre Gemini 3.1 Pro
“A pontuação de 77,1% do Gemini 3.1 Pro representa a mudança de mercado mais disruptiva; ela mais que dobra o recorde anterior no ARC-AGI.”
“Os benchmarks de codificação não mentem. Este model encontrou um bug no meu repositório que o 3.5 e o GPT-4o perderam completamente.”
“O caos sobre o Gemini 3.1 é realmente interessante. Ele destruiu os benchmarks, mas os usuários reais dizem que o tom e a vibe são inconsistentes.”
“O motor DeepThink pode levar a atrasos significativos, às vezes mais de 90 segundos, ao processar tarefas que exigem lógica profunda.”
“Context caching é o recurso matador aqui. Estou rodando um bot de documentação inteiro por centavos comparado ao GPT-4o.”
“O Gemini falhou em discutir Python em uma tarefa de planejamento complexa... alguma lógica simplesmente não estava presente em seu plano final.”
Videos Sobre Gemini 3.1 Pro
Assista tutoriais, analises e discussoes sobre Gemini 3.1 Pro
“O Gemini 3.1 Pro gera a versão mais detalhada deste pagode até agora”
“O Gemini tem, de longe, a janela mais ampla de um milhão de tokens”
“A fidelidade multimodal no processamento de áudio é visivelmente melhor que no 3.0”
“O throughput de tokens permanece estável mesmo à medida que a context window é preenchida”
“O recall de longo prazo é praticamente perfeito em todo o milhão de tokens”
“Em quebra-cabeças que não deveriam estar em seus dados de treinamento, a série Gemini 3 supera todos os outros modelos”
“O 3.1 Pro poderia, de fato, reduzir o tempo de execução de um script de fine-tuning de 300 segundos para 47 segundos”
“Os passos de lógica do DeepThink são claramente visíveis no trace, mostrando deliberação real”
“Estamos atingindo a saturação de benchmark onde apenas o ARC-AGI realmente importa para o progresso”
“A trajetória da AGI está acelerando com base nesses saltos de reasoning abstrato”
“Acho que, como o 3.1, ele genuinamente parece um passo à frente, mesmo que seja apenas muito leve”
“Ele parece superar o Gemini 3.0 Pro quando testamos exatamente os mesmos prompts lado a lado”
“A precisão de codificação em refatorações complexas de Python é a mais alta que já vi”
“A confiabilidade da API melhorou significativamente durante o último mês de testes”
“O desempenho no mundo real finalmente corresponde ao hype das pontuações de benchmark”
Potencialize seu fluxo de trabalho com Automacao de IA
Automatio combina o poder de agentes de IA, automacao web e integracoes inteligentes para ajuda-lo a realizar mais em menos tempo.
Dicas Profissionais para Gemini 3.1 Pro
Dicas de especialistas para ajuda-lo a aproveitar ao maximo Gemini 3.1 Pro e obter melhores resultados.
Seleção de Nível de Reasoning
Use o modo de pensamento Alto para lógica ou matemática complexa, mas mude para Baixo para formatação padrão para economizar compute.
Context Caching
Implemente context caching para documentação estática para reduzir os preços de input em até 90% por milhão de tokens.
Artefatos Estruturados
Aproveite a capacidade do model de gerar listas de tarefas estruturadas para facilitar a supervisão humana durante execuções agentic.
Multimodal Prompting
Combine inputs de vídeo e áudio para dar ao model o contexto completo de cenários do mundo real em vez de apenas descrições em texto.
Depoimentos
O Que Nossos Usuarios Dizem
Junte-se a milhares de usuarios satisfeitos que transformaram seu fluxo de trabalho
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Relacionados AI Models
Claude Opus 4.7
Anthropic
Claude Opus 4.7 is Anthropic's flagship model with a 1-million-token context, adaptive reasoning, and 3.3x vision resolution for enterprise-scale agents.
Gemini 3.1 Flash Live Preview
Gemini 3.1 Flash Live Preview is Google's ultra-low-latency, audio-to-audio model featuring a 131K context window, high-fidelity multimodal reasoning, and...
GPT-5.5
OpenAI
GPT-5.5 is OpenAI's flagship frontier model with a 1M context window and five reasoning effort levels, optimized for autonomous agentic workflows and coding.
Grok-3
xAI
Grok-3 is xAI's flagship reasoning model, featuring deep logic deduction, a 128k context window, and real-time integration with X for live research and coding.
Kimi K3
Moonshot
Kimi K3 is Moonshot AI's 2.8T MoE model with a 1M token context window, native multimodal vision, and frontier-tier coding performance for complex agents.
GPT-5.2 Pro
OpenAI
GPT-5.2 Pro is OpenAI's 2025 flagship reasoning model featuring Extended Thinking for SOTA performance in mathematics, coding, and expert knowledge work.
Qwen 3.7 Max
alibaba
Qwen 3.7 Max is Alibaba’s flagship AI model for deep reasoning and autonomous agent tasks, featuring a 256k context window and top-tier coding performance.
Gemini 3 Pro
Google's Gemini 3 Pro is a multimodal powerhouse featuring a 1M token context window, native video processing, and industry-leading reasoning performance.
Perguntas Frequentes Sobre Gemini 3.1 Pro
Encontre respostas para perguntas comuns sobre Gemini 3.1 Pro