
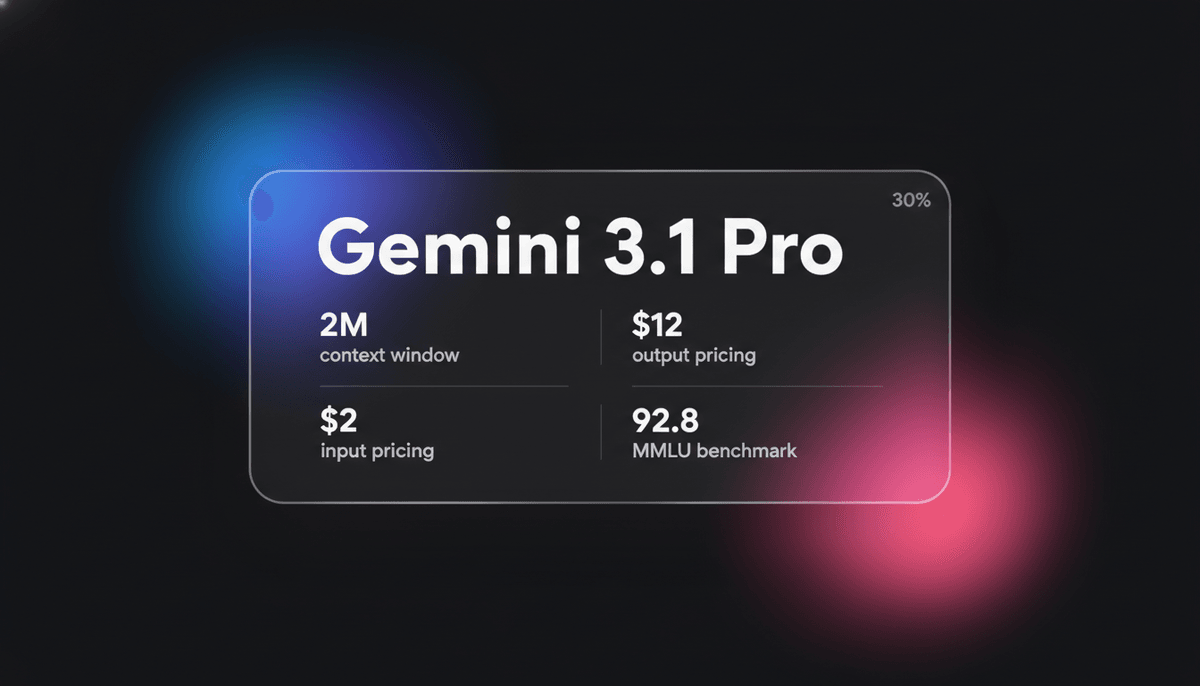
Gemini 3.1 Pro
Gemini 3.1 Pro — элитная multimodal модель Google с движком DeepThink, context window 1M+ и лучшими в индустрии результатами логики ARC-AGI.
О модели Gemini 3.1 Pro
Узнайте о возможностях, функциях и способах использования Gemini 3.1 Pro.
Gemini 3.1 Pro представляет собой зрелую реализацию фреймворка Sparse Mixture-of-Experts (MoE), встроенного в продвинутый multimodal движок обработки. Ключевой особенностью архитектуры является демократизация слоя DeepThink System 2, который позволяет модели обдумывать ответ перед генерацией выходного token. Модель представляет уникальную трехуровневую систему мышления (Low, Medium, High), позволяющую разработчикам явно контролировать баланс между latency, стоимостью и глубиной reasoning.
Благодаря огромному context window в 1 миллион tokens, Gemini 3.1 Pro максимально оптимизирована для сложных рабочих процессов в финансах, аналитике данных и миграции кодовых баз. Она демонстрирует эмерджентную способность решать новые логические паттерны, набрав рекордные 77.1% в benchmark ARC-AGI-2. Это делает ее предпочтительным выбором для разработчиков, которым требуются как низкая latency при multimodal взаимодействии, так и высокая когнитивная производительность для автономных agentic задач.
Варианты использования Gemini 3.1 Pro
Откройте для себя различные способы использования Gemini 3.1 Pro для достижения отличных результатов.
Анализ кода целых репозиториев
Использование 1M context window для обработки целых программных репозиториев для рефакторинга и построения карт зависимостей.
Автономные комитеты агентов
Управление многошаговыми agentic рабочими процессами, где внутренние под-агенты обсуждают и проверяют решения перед выполнением.
Синтез научных исследований
Анализ тысяч научных работ и сложных наборов данных для извлечения структурированных данных и фактов.
Создание multimodal контента
Одновременная обработка текста, изображений и аудио для создания сложных учебных материалов и интерактивных медиа.
Терминальная автоматизация
Выполнение сложных bash-команд и манипуляция файловыми системами с высокой точностью через продвинутые режимы reasoning.
Аудит корпоративных данных
Парсинг неструктурированных финансовых и юридических документов для выявления пробелов в комплаенсе с почти идеальной точностью извлечения фактов.
Преимущества
Ограничения
Быстрый старт API
google/gemini-3.1-pro-preview
import { GoogleGenAI } from "@google/genai";
const genAI = new GoogleGenAI(process.env.GOOGLE_API_KEY);
const model = genAI.getGenerativeModel({
model: "gemini-3.1-pro-preview",
thinkingConfig: { tier: "high" }
});
const prompt = "Analyze this entire codebase for security vulnerabilities.";
const result = await model.generateContent(prompt);
console.log(result.response.text());Установите SDK и начните делать API-запросы за несколько минут.
Что люди говорят о Gemini 3.1 Pro
Посмотрите, что думает сообщество о Gemini 3.1 Pro
“Результат 77.1% у Gemini 3.1 Pro, это самый разрушительный сдвиг на рынке; он более чем вдвое превышает предыдущий рекорд в ARC-AGI.”
“Benchmarks кодирования не врут. Эта модель нашла ошибку в моем репозитории, которую пропустили 3.5 и GPT-4o.”
“Шумиха вокруг Gemini 3.1 действительно интересна. Она разгромила benchmarks, но реальные пользователи говорят, что тон и «вайб» модели непоследовательны.”
“Движок DeepThink может приводить к значительным задержкам, иногда более 90 секунд, при выполнении задач, требующих глубокой логики.”
“Context caching, это киллер-фича. Я запускаю целый бот для документации за копейки по сравнению с GPT-4o.”
“Gemini вообще не смогла обсудить Python в сложной задаче планирования... логика просто отсутствовала в финальном плане.”
Видео о Gemini 3.1 Pro
Смотрите обучающие материалы, обзоры и обсуждения о Gemini 3.1 Pro
“Gemini 3.1 Pro генерирует самую детальную версию этой пагоды на данный момент”
“Gemini обладает самым широким окном в миллион tokens”
“Multimodal точность при обработке аудио заметно лучше, чем в 3.0”
“Пропускная способность tokens остается стабильной, даже когда context window заполняется”
“Долгосрочное удержание контекста практически идеально на всем миллионе tokens”
“В задачах, которых не должно быть в обучающих данных, серия Gemini 3 превосходит все остальные модели”
“3.1 Pro действительно может сократить время выполнения скрипта fine-tuning с 300 до 47 секунд”
“Шаги логики DeepThink четко видны в трассировке, показывая реальное обдумывание”
“Мы достигаем насыщения benchmarks, где для прогресса имеет значение только ARC-AGI”
“Траектория AGI ускоряется благодаря этим скачкам в abstract reasoning”
“Я действительно считаю, что 3.1, это шаг вперед, даже если он очень небольшой”
“Похоже, она превосходит Gemini 3.0 Pro при тестировании тех же самых prompts”
“Точность кодирования при сложных рефакторах Python, самая высокая из всех, что я видел”
“Надежность API значительно улучшилась за последний месяц тестирования”
“Реальная производительность наконец соответствует хайпу вокруг оценок в benchmark”
Улучшите свой рабочий процесс с ИИ-Автоматизацией
Automatio объединяет мощь ИИ-агентов, веб-автоматизации и умных интеграций, чтобы помочь вам достигать большего за меньшее время.
Советы для Gemini 3.1 Pro
Экспертные советы для максимальной эффективности Gemini 3.1 Pro.
Выбор уровня reasoning
Используйте режим High для сложных математических или логических задач, но переключайтесь на Low для стандартного форматирования, чтобы сэкономить ресурсы.
Context Caching
Внедрите context caching для статической документации, чтобы снизить затраты на ввод до 90% на миллион tokens.
Структурированные артефакты
Используйте способность модели генерировать структурированные списки задач для упрощения контроля человеком во время выполнения agentic процессов.
Multimodal prompting
Комбинируйте ввод видео и аудио, чтобы предоставить модели полный контекст реальных сценариев, а не только текстовые описания.
Отзывы
Что Говорят Наши Пользователи
Присоединяйтесь к тысячам довольных пользователей, которые трансформировали свой рабочий процесс
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Похожие AI Models
Claude Opus 4.7
Anthropic
Claude Opus 4.7 is Anthropic's flagship model with a 1-million-token context, adaptive reasoning, and 3.3x vision resolution for enterprise-scale agents.
Gemini 3.1 Flash Live Preview
Gemini 3.1 Flash Live Preview is Google's ultra-low-latency, audio-to-audio model featuring a 131K context window, high-fidelity multimodal reasoning, and...
GPT-5.5
OpenAI
GPT-5.5 is OpenAI's flagship frontier model with a 1M context window and five reasoning effort levels, optimized for autonomous agentic workflows and coding.
Grok-3
xAI
Grok-3 is xAI's flagship reasoning model, featuring deep logic deduction, a 128k context window, and real-time integration with X for live research and coding.
Kimi K3
Moonshot
Kimi K3 is Moonshot AI's 2.8T MoE model with a 1M token context window, native multimodal vision, and frontier-tier coding performance for complex agents.
GPT-5.2 Pro
OpenAI
GPT-5.2 Pro is OpenAI's 2025 flagship reasoning model featuring Extended Thinking for SOTA performance in mathematics, coding, and expert knowledge work.
Qwen 3.7 Max
alibaba
Qwen 3.7 Max is Alibaba’s flagship AI model for deep reasoning and autonomous agent tasks, featuring a 256k context window and top-tier coding performance.
Gemini 3 Pro
Google's Gemini 3 Pro is a multimodal powerhouse featuring a 1M token context window, native video processing, and industry-leading reasoning performance.
Часто задаваемые вопросы о Gemini 3.1 Pro
Найдите ответы на частые вопросы о Gemini 3.1 Pro