
Gemini 3.1 Pro
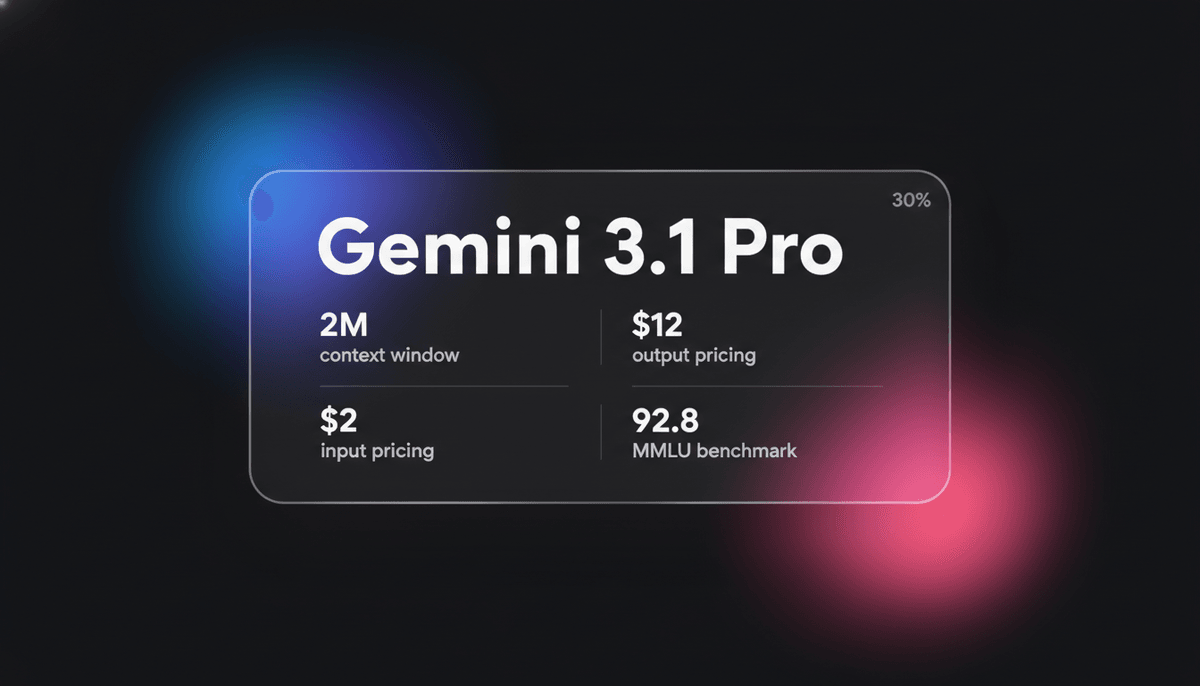
Gemini 3.1 Pro je Google-ov elitni multimodalni model koji sadrži DeepThink reasoning engine, 1M+ context window i vodeće ARC-AGI logičke rezultate u...
О моделу Gemini 3.1 Pro
Сазнајте о могућностима, функцијама и начинима коришћења модела Gemini 3.1 Pro.
Gemini 3.1 Pro predstavlja zrelu implementaciju Sparse Mixture-of-Experts (MoE) okvira, nativno uparenog sa naprednim multimodalnim procesorom. Istaknuta karakteristika arhitekture je demokratizacija DeepThink System 2 sloja, koji modelu omogućava da promišlja interno pre nego što se posveti output tokenu. Ovaj model uvodi jedinstveni sistem razmišljanja na tri nivoa (Low, Medium i High), omogućavajući programerima da eksplicitno kontrolišu odnos između latency-ja, cene i dubine reasoning-a.
Sa masivnim context window-om od 1 milion tokens, Gemini 3.1 Pro je visoko optimizovan za kompleksne workflow-ove u finansijama, analitici podataka i migracijama koda celih repozitorijuma. Pokazuje emergentnu sposobnost rešavanja novih logičkih obrazaca, postižući rekordnih 77,1% na ARC-AGI-2 benchmark-u. To ga čini preferiranim izborom za programere kojima su potrebne kako multimodalne interakcije niske latency, tako i kognitivne performanse visokog nivoa za autonomne agentic zadatke.
Случајеви употребе за Gemini 3.1 Pro
Откријте различите начине коришћења модела Gemini 3.1 Pro за постизање одличних резултата.
Analiza koda celog repozitorijuma
Korišćenje 1M context window-a za učitavanje celih softverskih repozitorijuma radi refaktorisanja i mapiranja zavisnosti.
Autonomni komiteti agenata
Pokretanje multi-step agentic workflow-ova gde interni sub-agenti debatuju i verifikuju rešenja pre izvršenja.
Sinteza naučnih istraživanja
Analiza hiljada istraživačkih radova i kompleksnih skupova podataka radi izvlačenja strukturirane inteligencije i činjeničnih uvida.
Multimodal kreiranje sadržaja
Istovremena obrada teksta, slika i zvuka za generisanje kompleksnih edukativnih materijala i interaktivnih medija.
Terminalska automatizacija
Izvršavanje kompleksnih bash komandi i manipulacija sistemom datoteka sa visokom preciznošću kroz napredne reasoning modove.
Revizija korporativnih podataka
Parsiranje nestrukturiranih finansijskih podataka i pravnih dokumenata radi identifikacije propusta u usklađenosti sa gotovo savršenom činjeničnom preciznošću.
Предности
Ограничења
АПИ брзи старт
google/gemini-3.1-pro-preview
import { GoogleGenAI } from "@google/genai";
const genAI = new GoogleGenAI(process.env.GOOGLE_API_KEY);
const model = genAI.getGenerativeModel({
model: "gemini-3.1-pro-preview",
thinkingConfig: { tier: "high" }
});
const prompt = "Analyze this entire codebase for security vulnerabilities.";
const result = await model.generateContent(prompt);
console.log(result.response.text());Инсталирајте SDK и почните са АПИ позивима за неколико минута.
Шта људи кажу о моделу Gemini 3.1 Pro
Погледајте шта заједница мисли о моделу Gemini 3.1 Pro
“Skor od 77,1% za Gemini 3.1 Pro predstavlja najdisruptivniji tržišni pomak; više nego udvostručuje prethodni maksimum na ARC-AGI.”
“Benchmark-ovi za kodiranje ne lažu. Ovaj model je pronašao bug u mom repozitorijumu koji su 3.5 i GPT-4o potpuno propustili.”
“Ova drama oko Gemini 3.1 je zaista interesantna. Razbio je benchmark-ove, ali stvarni korisnici kažu da su ton i 'vajb' nedosledni.”
“DeepThink engine može dovesti do značajnih kašnjenja, ponekad preko 90 sekundi, kada obrađuje zadatke koji zahtevaju duboku logiku.”
“Context caching je ovde glavna funkcija. Pokrećem ceo bot za dokumentaciju za sitniš u poređenju sa GPT-4o.”
“Gemini uopšte nije diskutovao o Python-u u kompleksnom zadatku planiranja... neka logika jednostavno nije bila prisutna u njegovom konačnom planu.”
Видео снимци о моделу Gemini 3.1 Pro
Гледајте туторијале, рецензије и дискусије о моделу Gemini 3.1 Pro
“Gemini 3.1 Pro generiše najdetaljniju verziju ove pagode do sada”
“Gemini ima ubedljivo najširi prozor od milion tokens”
“Multimodalna vernost u audio obradi je primetno bolja nego kod 3.0”
“Token throughput ostaje stabilan čak i kada se context window popuni”
“Dugoročni recall je u suštini savršen kroz svih milion tokens”
“Na slagalicama koje ne bi trebalo da budu u podacima za treniranje, serija Gemini 3 nadmašuje sve ostale modele”
“3.1 Pro bi zaista mogao da skrati vreme izvršavanja fine-tuning skripte sa 300 na 47 sekundi”
“DeepThink logički koraci su jasno vidljivi u tragu, pokazujući pravo promišljanje”
“Dostižemo zasićenje benchmark-ova gde je samo ARC-AGI zaista važan za napredak”
“Putanja ka AGI se ubrzava na osnovu ovih iskoraka u apstraktnom reasoning-u”
“Mislim da se za 3.1 zaista oseća da je korak napred, čak i ako je vrlo mali”
“Čini se da nadmašuje Gemini 3.0 Pro kada testiramo potpuno iste prompt-ove jedne pored drugih”
“Tačnost kodiranja na kompleksnim Python refaktorizacijama je najviša koju sam video”
“Pouzdanost API-ja se značajno poboljšala tokom poslednjeg meseca testiranja”
“Performanse u stvarnom svetu konačno odgovaraju haipu oko benchmark rezultata”
Побољшајте свој радни ток са AI Automatizacijom
Automatio kombinuje moc AI agenata, web automatizacije i pametnih integracija kako bi vam pomogao da postignete vise za manje vremena.
Pro Saveti za Gemini 3.1 Pro
Stručni saveti za maksimalno iskorišćenje Gemini 3.1 Pro.
Izbor nivoa reasoning-a
Koristite High thinking mod za kompleksnu matematiku ili logiku, ali prebacite na Low za standardno formatiranje kako biste uštedeli compute.
Context Caching
Implementirajte context caching za statičnu dokumentaciju kako biste smanjili cene input-a do 90% na milion tokens.
Strukturirani artefakti
Iskoristite sposobnost modela da generiše strukturirane liste zadataka radi lakšeg ljudskog nadzora tokom agentic izvršavanja.
Multimodal prompting
Kombinujte video i audio input-e da biste modelu dali pun kontekst situacija iz stvarnog sveta umesto opisa samo u tekstualnom formatu.
Сведочанства
Sta Kazu Nasi Korisnici
Pridruzite se hiljadama zadovoljnih korisnika koji su transformisali svoj radni tok
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Povezani AI Models
Claude Opus 4.7
Anthropic
Claude Opus 4.7 is Anthropic's flagship model with a 1-million-token context, adaptive reasoning, and 3.3x vision resolution for enterprise-scale agents.
Gemini 3.1 Flash Live Preview
Gemini 3.1 Flash Live Preview is Google's ultra-low-latency, audio-to-audio model featuring a 131K context window, high-fidelity multimodal reasoning, and...
GPT-5.5
OpenAI
GPT-5.5 is OpenAI's flagship frontier model with a 1M context window and five reasoning effort levels, optimized for autonomous agentic workflows and coding.
Grok-3
xAI
Grok-3 is xAI's flagship reasoning model, featuring deep logic deduction, a 128k context window, and real-time integration with X for live research and coding.
Kimi K3
Moonshot
Kimi K3 is Moonshot AI's 2.8T MoE model with a 1M token context window, native multimodal vision, and frontier-tier coding performance for complex agents.
GPT-5.2 Pro
OpenAI
GPT-5.2 Pro is OpenAI's 2025 flagship reasoning model featuring Extended Thinking for SOTA performance in mathematics, coding, and expert knowledge work.
Qwen 3.7 Max
alibaba
Qwen 3.7 Max is Alibaba’s flagship AI model for deep reasoning and autonomous agent tasks, featuring a 256k context window and top-tier coding performance.
Gemini 3 Pro
Google's Gemini 3 Pro is a multimodal powerhouse featuring a 1M token context window, native video processing, and industry-leading reasoning performance.
Често Постављана Питања о Gemini 3.1 Pro
Пронађите одговоре на честа питања о Gemini 3.1 Pro