Hur man skrapar GOV.UK | Guide för webbskrapning av brittiska myndigheter
Omfattande guide för att skrapa GOV.UK för myndighetsvägledning, policyuppdateringar och officiell statistik. Lär dig att extrahera värdefull offentlig data.
Anti-bot-skydd upptäckt
- Hastighetsbegränsning
- Begränsar förfrågningar per IP/session över tid. Kan kringgås med roterande proxyservrar, fördröjda förfrågningar och distribuerad skrapning.
- User-Agent Filtering
- IP-blockering
- Blockerar kända datacenter-IP:er och flaggade adresser. Kräver bostads- eller mobilproxyservrar för effektiv kringgång.
Om GOV.UK
Upptäck vad GOV.UK erbjuder och vilka värdefulla data som kan extraheras.
GOV.UK är den centrala digitala portalen för den brittiska regeringen, som erbjuder en enda åtkomstpunkt till tjänster och information från alla departement och myndigheter. Den skapades av Government Digital Service (GDS) och ersatte hundratals enskilda myndighetswebbplatser med ett enhetligt, användarvänligt gränssnitt designat för transparens och effektivitet.
Plattformen innehåller ett enormt arkiv av data, inklusive regulatorisk vägledning, officiell statistik, policyrapporter och upphandlingsmeddelanden. Eftersom den brittiska regeringen följer en policy om 'öppen data som standard', publiceras det mesta av informationen på GOV.UK under Open Government Licence, vilket gör den till en guldgruva för forskare, juridiska byråer och företag.
Att skrapa GOV.UK är mycket värdefullt för att övervaka regulatoriska förändringar, spåra ekonomiska indikatorer och samla in konkurrensinformation från offentliga upphandlingsannonser. Organisationer använder denna data för att automatisera arbetsflöden för efterlevnad och ligga steget före politiska utvecklingar som påverkar deras branscher.
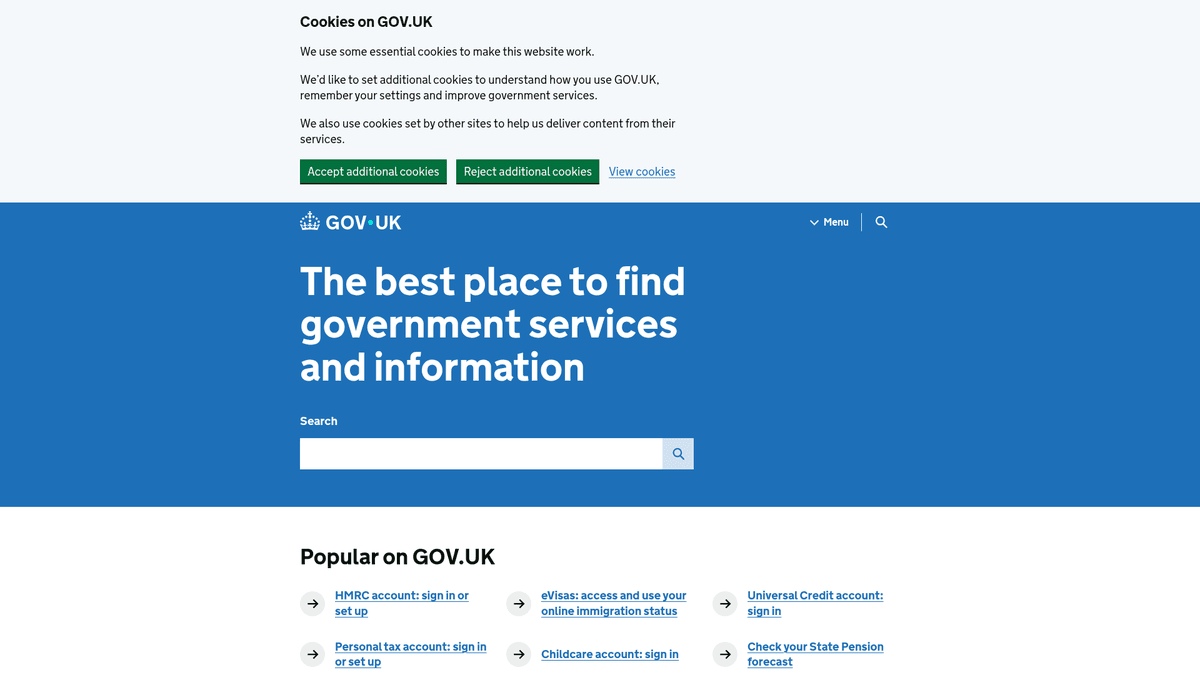
Varför Skrapa GOV.UK?
Upptäck affärsvärdet och användningsfallen för dataextraktion från GOV.UK.
Övervaka efterlevnad av lagar och regler
Följ policyförändringar i realtid
Samla in ekonomisk och statistisk data
Hitta offentliga upphandlingar och kontraktsmöjligheter
Arkivera juridiska och historiska dokument
Utföra akademisk socioekonomisk forskning
Skrapningsutmaningar
Tekniska utmaningar du kan stöta på när du skrapar GOV.UK.
Djupt nästlad hierarkisk sidstruktur
Hög volym av dokument och PDF-bilagor
Strikt rate limit på 3 000 förfrågningar per 5 minuter
Mindre layoutvariationer mellan olika departement
Skrapa GOV.UK med AI
Ingen kod krävs. Extrahera data på minuter med AI-driven automatisering.
Hur det fungerar
Beskriv vad du behöver
Berätta för AI vilka data du vill extrahera från GOV.UK. Skriv det bara på vanligt språk — ingen kod eller selektorer behövs.
AI extraherar datan
Vår artificiella intelligens navigerar GOV.UK, hanterar dynamiskt innehåll och extraherar exakt det du bad om.
Få dina data
Få ren, strukturerad data redo att exportera som CSV, JSON eller skicka direkt till dina appar och arbetsflöden.
Varför använda AI för skrapning
AI gör det enkelt att skrapa GOV.UK utan att skriva kod. Vår AI-drivna plattform använder artificiell intelligens för att förstå vilka data du vill ha — beskriv det bara på vanligt språk och AI extraherar dem automatiskt.
How to scrape with AI:
- Beskriv vad du behöver: Berätta för AI vilka data du vill extrahera från GOV.UK. Skriv det bara på vanligt språk — ingen kod eller selektorer behövs.
- AI extraherar datan: Vår artificiella intelligens navigerar GOV.UK, hanterar dynamiskt innehåll och extraherar exakt det du bad om.
- Få dina data: Få ren, strukturerad data redo att exportera som CSV, JSON eller skicka direkt till dina appar och arbetsflöden.
Why use AI for scraping:
- Konfiguration utan kod för komplex navigering
- Schemalagda körningar för att övervaka policyförändringar
- Direkt export till Google Sheets eller CSV
- Automatisk extrahering av dolda dokumentlänkar
No-code webbskrapare för GOV.UK
Peka-och-klicka-alternativ till AI-driven skrapning
Flera no-code-verktyg som Browse.ai, Octoparse, Axiom och ParseHub kan hjälpa dig att skrapa GOV.UK utan att skriva kod. Dessa verktyg använder vanligtvis visuella gränssnitt för att välja data, även om de kan ha problem med komplext dynamiskt innehåll eller anti-bot-åtgärder.
Typiskt arbetsflöde med no-code-verktyg
Vanliga utmaningar
Inlärningskurva
Att förstå selektorer och extraktionslogik tar tid
Selektorer går sönder
Webbplatsändringar kan förstöra hela ditt arbetsflöde
Problem med dynamiskt innehåll
JavaScript-tunga sidor kräver komplexa lösningar
CAPTCHA-begränsningar
De flesta verktyg kräver manuell hantering av CAPTCHAs
IP-blockering
Aggressiv scraping kan leda till att din IP blockeras
No-code webbskrapare för GOV.UK
Flera no-code-verktyg som Browse.ai, Octoparse, Axiom och ParseHub kan hjälpa dig att skrapa GOV.UK utan att skriva kod. Dessa verktyg använder vanligtvis visuella gränssnitt för att välja data, även om de kan ha problem med komplext dynamiskt innehåll eller anti-bot-åtgärder.
Typiskt arbetsflöde med no-code-verktyg
- Installera webbläsartillägg eller registrera dig på plattformen
- Navigera till målwebbplatsen och öppna verktyget
- Välj dataelement att extrahera med point-and-click
- Konfigurera CSS-selektorer för varje datafält
- Ställ in pagineringsregler för att scrapa flera sidor
- Hantera CAPTCHAs (kräver ofta manuell lösning)
- Konfigurera schemaläggning för automatiska körningar
- Exportera data till CSV, JSON eller anslut via API
Vanliga utmaningar
- Inlärningskurva: Att förstå selektorer och extraktionslogik tar tid
- Selektorer går sönder: Webbplatsändringar kan förstöra hela ditt arbetsflöde
- Problem med dynamiskt innehåll: JavaScript-tunga sidor kräver komplexa lösningar
- CAPTCHA-begränsningar: De flesta verktyg kräver manuell hantering av CAPTCHAs
- IP-blockering: Aggressiv scraping kan leda till att din IP blockeras
Kodexempel
import requests
from bs4 import BeautifulSoup
# PROFFSTIPS: Lägg till .json i slutet av många GOV.UK-URL:er för rådata
url = 'https://www.gov.uk/search/news-and-communications'
headers = {'User-Agent': 'ResearchBot/1.0 (contact@example.com)'}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
for item in soup.select('.gem-c-document-list__item'):
title = item.select_one('.gem-c-document-list__item-title').text.strip()
link = item.select_one('a')['href']
print(f'Uppdatering: {title} | https://www.gov.uk{link}')
except Exception as e:
print(f'Fel: {e}')När ska det användas
Bäst för statiska HTML-sidor med minimal JavaScript. Idealiskt för bloggar, nyhetssidor och enkla e-handelsproduktsidor.
Fördelar
- ●Snabbaste exekveringen (ingen webbläsaröverhead)
- ●Lägsta resursförbrukning
- ●Lätt att parallellisera med asyncio
- ●Utmärkt för API:er och statiska sidor
Begränsningar
- ●Kan inte köra JavaScript
- ●Misslyckas på SPA:er och dynamiskt innehåll
- ●Kan ha problem med komplexa anti-bot-system
Hur man skrapar GOV.UK med kod
Python + Requests
import requests
from bs4 import BeautifulSoup
# PROFFSTIPS: Lägg till .json i slutet av många GOV.UK-URL:er för rådata
url = 'https://www.gov.uk/search/news-and-communications'
headers = {'User-Agent': 'ResearchBot/1.0 (contact@example.com)'}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
for item in soup.select('.gem-c-document-list__item'):
title = item.select_one('.gem-c-document-list__item-title').text.strip()
link = item.select_one('a')['href']
print(f'Uppdatering: {title} | https://www.gov.uk{link}')
except Exception as e:
print(f'Fel: {e}')Python + Playwright
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
try:
page.goto('https://www.gov.uk/search/all?keywords=data+protection')
page.wait_for_selector('.gem-c-document-list__item')
titles = page.locator('.gem-c-document-list__item-title').all_text_contents()
for t in titles:
print(f'Extraherat: {t.strip()}')
finally:
browser.close()Python + Scrapy
import scrapy
class GovSpider(scrapy.Spider):
name = 'gov_spider'
start_urls = ['https://www.gov.uk/search/news-and-communications']
def parse(self, response):
for article in response.css('.gem-c-document-list__item'):
yield {
'title': article.css('.gem-c-document-list__item-title::text').get().strip(),
'link': response.urljoin(article.css('a::attr(href)').get())
}
next_page = response.css('a[rel="next"]::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
try {
await page.goto('https://www.gov.uk/search/news-and-communications', { waitUntil: 'networkidle2' });
const results = await page.evaluate(() =>
Array.from(document.querySelectorAll('.gem-c-document-list__item-title'))
.map(el => el.innerText.trim())
);
console.log(results);
} finally {
await browser.close();
}
})();Vad Du Kan Göra Med GOV.UK-Data
Utforska praktiska tillämpningar och insikter från GOV.UK-data.
System för regulatoriska varningar
Juridiska team och efterlevnadsteam kan övervaka specifika vägledningskategorier för att omedelbart upptäcka lagändringar.
Så här implementerar du:
- 1Skrapa sektionen 'Guidance and Regulation' dagligen.
- 2Extrahera dokumenttext och tidsstämplar för senaste uppdatering.
- 3Jämför innehåll mot tidigare versioner för att markera skillnader (diffs).
- 4Skicka automatiserade varningar till relevanta interna intressenter.
Använd Automatio för att extrahera data från GOV.UK och bygga dessa applikationer utan att skriva kod.
Vad Du Kan Göra Med GOV.UK-Data
- System för regulatoriska varningar
Juridiska team och efterlevnadsteam kan övervaka specifika vägledningskategorier för att omedelbart upptäcka lagändringar.
- Skrapa sektionen 'Guidance and Regulation' dagligen.
- Extrahera dokumenttext och tidsstämplar för senaste uppdatering.
- Jämför innehåll mot tidigare versioner för att markera skillnader (diffs).
- Skicka automatiserade varningar till relevanta interna intressenter.
- Bevakning av upphandlingar
Säljteam kan skrapa upphandlingsmeddelanden för att hitta nya möjligheter till statliga kontrakt.
- Rikta in dig på sökkategorin 'Procurement' på GOV.UK.
- Skrapa sista ansökningsdatum, kontakt-e-post och kontraktsvärden.
- Filtrera resultat efter branschnyckelord relevanta för din verksamhet.
- Importera leads direkt till ett CRM för uppföljning.
- Analys av ekonomiska trender
Ekonomer kan sammanställa statistiska utgåvor för longitudinella studier av Storbritanniens prestationer.
- Identifiera URL:er för statistiska dataserier.
- Skrapa direktlänkar till CSV- eller Excel-filer.
- Ladda ner och rensa dataseten med automatiserade skript.
- Slå samman data i en centraliserad databas för visualisering.
- Arkiv för offentlig politik
Journalister och forskare kan skapa ett sökbart arkiv över officiella myndighetsmeddelanden.
- Skrapa sektionen 'News and Communications' kontinuerligt.
- Extrahera rubriker, brödtext och departementstaggar.
- Indexera data i en sökbar plattform som Elasticsearch.
- Analysera sentiment och frekvens av specifika policynyckelord.
- Automatiserade rådgivningsbottar
Ideella organisationer kan använda officiell vägledning för att driva chatbots som hjälper medborgare att hitta information om förmåner.
- Skrapa vägledningssidor för förmåner och bostäder.
- Mappa extraherad text till en vector-databas för RAG (Retrieval-Augmented Generation).
- Ställ in en trigger för att uppdatera databasen när innehållet på GOV.UK ändras.
- Tillhandahåll korrekta svar i realtid på användarfrågor.
- Sökmotor för bidrag och finansiering
Utbildningsinstitutioner kan hitta möjligheter till bidrag och finansiering för forskningsprojekt.
- Skrapa finansieringskategorin 'Education, Training and Skills'.
- Extrahera behörighetskriterier och ansökningsdeadlines.
- Kategorisera anslag efter departement och finansieringsbelopp.
- Automatisera veckovisa e-postsammanfattningar till fakultetsmedlemmar.
Superladda ditt arbetsflode med AI-automatisering
Automatio kombinerar kraften av AI-agenter, webbautomatisering och smarta integrationer for att hjalpa dig astadkomma mer pa kortare tid.
Proffstips för Skrapning av GOV.UK
Expertråd för framgångsrik dataextraktion från GOV.UK.
Lägg till '.json' i slutet av nästan vilken GOV.UK-URL som helst för att hämta underliggande metadata utan HTML-parsing.
Identifiera element med hjälp av CSS-klasser som börjar med 'gem-c-', eftersom dessa ingår i standarden för GDS Design System.
Ange en beskrivande User-Agent-sträng som innehåller din e-postadress så att GDS kan kontakta dig om din bot orsakar problem.
Håll dig under rate limit-gränsen på 3 000 förfrågningar per 5 minuter för att undvika tillfälliga IP-blockeringar.
Fokusera på 'Sök'-sidorna för storskalig discovery, eftersom de erbjuder rena, sidnumrerade listor med dokument.
Kontrollera tidsstämpeln för 'Last Updated' för att undvika att skrapa oförändrat innehåll på nytt.
Omdomen
Vad vara anvandare sager
Ga med tusentals nojda anvandare som har transformerat sitt arbetsflode
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Relaterat Web Scraping
Vanliga fragor om GOV.UK
Hitta svar pa vanliga fragor om GOV.UK