
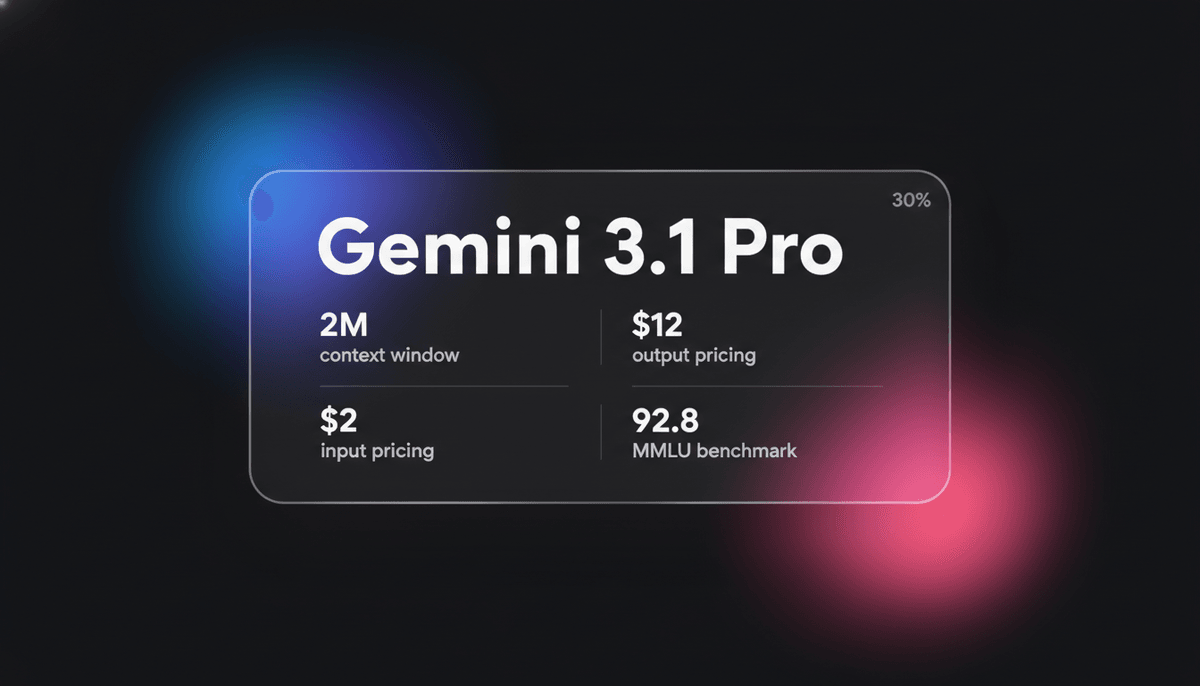
Gemini 3.1 Pro
Gemini 3.1 Pro คือโมเดล multimodal ชั้นนำจาก Google ที่มาพร้อมเอนจินการใช้เหตุผล DeepThink, context window กว่า 1 ล้าน tokens และคะแนนตรรกะ ARC-AGI...
เกี่ยวกับ Gemini 3.1 Pro
เรียนรู้เกี่ยวกับความสามารถของ Gemini 3.1 Pro คุณสมบัติ และวิธีที่จะช่วยให้คุณได้ผลลัพธ์ที่ดีขึ้น
Gemini 3.1 Pro เป็นการนำเฟรมเวิร์ก Sparse Mixture-of-Experts (MoE) มาประยุกต์ใช้อย่างเต็มรูปแบบ โดยจับคู่กับเอนจินประมวลผล multimodal ขั้นสูง ฟีเจอร์ที่โดดเด่นของสถาปัตยกรรมนี้คือการทำให้ DeepThink System 2 layer เข้าถึงได้มากขึ้น ซึ่งช่วยให้โมเดลสามารถไตร่ตรองภายในก่อนที่จะสร้าง output ออกมา โมเดลนี้แนะนำระบบการคิด 3 ระดับที่เป็นเอกลักษณ์ ได้แก่ Low, Medium และ High ซึ่งช่วยให้นักพัฒนาสามารถควบคุมความสมดุลระหว่าง latency, ต้นทุน และความลึกของการใช้เหตุผลได้อย่างแม่นยำ
ด้วย context window ขนาด 1 ล้าน tokens ทำให้ Gemini 3.1 Pro ได้รับการปรับแต่งอย่างเหมาะสมสำหรับเวิร์กโฟลว์ที่ซับซ้อนในภาคการเงิน การวิเคราะห์ข้อมูล และการย้าย codebase ทั้ง repository นอกจากนี้ยังแสดงความสามารถในการแก้รูปแบบตรรกะใหม่ๆ โดยทำคะแนนได้ถึง 77.1% ใน ARC-AGI-2 benchmark ทำให้เป็นตัวเลือกที่นักพัฒนาชื่นชอบ สำหรับผู้ที่ต้องการทั้งการโต้ตอบแบบ multimodal ที่มี latency ต่ำและประสิทธิภาพเชิงสติปัญญาระดับสูงสำหรับงานแบบ agentic
กรณีการใช้งานสำหรับ Gemini 3.1 Pro
ค้นพบวิธีต่างๆ ที่คุณสามารถใช้ Gemini 3.1 Pro เพื่อได้ผลลัพธ์ที่ยอดเยี่ยม
การวิเคราะห์ Codebase ทั้งโปรเจกต์
ใช้ประโยชน์จาก context window ขนาด 1 ล้าน tokens เพื่อประมวลผลซอฟต์แวร์ทั้ง repository สำหรับการ refactoring และการทำ dependency mapping
คณะทำงาน Autonomous Agent
ขับเคลื่อนเวิร์กโฟลว์แบบ agentic หลายขั้นตอนที่ sub-agent ภายในสามารถโต้เถียงและตรวจสอบวิธีแก้ไขปัญหาก่อนเริ่มดำเนินการจริง
การสังเคราะห์งานวิจัยทางวิทยาศาสตร์
วิเคราะห์เอกสารวิจัยและชุดข้อมูลที่ซับซ้อนนับพันชุดเพื่อสกัดข้อมูลเชิงลึกที่มีโครงสร้างและข้อเท็จจริง
การสร้างคอนเทนต์แบบ Multimodal
ประมวลผลข้อความ รูปภาพ และเสียงไปพร้อมๆ กันเพื่อสร้างสื่อการสอนที่ซับซ้อนและสื่อเชิงโต้ตอบ
ระบบอัตโนมัติผ่าน Terminal
เรียกใช้คำสั่ง bash ที่ซับซ้อนและจัดการระบบไฟล์ด้วยความแม่นยำสูงผ่านโหมดการใช้เหตุผลขั้นสูง
การตรวจสอบข้อมูลองค์กร
แยกวิเคราะห์ข้อมูลทางการเงินและเอกสารทางกฎหมายที่ไม่มีโครงสร้างเพื่อระบุช่องว่างด้านการปฏิบัติตามกฎระเบียบด้วยการเรียกคืนข้อมูลเชิงข้อเท็จจริงที่แม่นยำเกือบสมบูรณ์
จุดแข็ง
ข้อจำกัด
เริ่มต้นด่วน API
google/gemini-3.1-pro-preview
import { GoogleGenAI } from "@google/genai";
const genAI = new GoogleGenAI(process.env.GOOGLE_API_KEY);
const model = genAI.getGenerativeModel({
model: "gemini-3.1-pro-preview",
thinkingConfig: { tier: "high" }
});
const prompt = "วิเคราะห์ codebase ทั้งหมดนี้เพื่อหาช่องโหว่ด้านความปลอดภัย";
const result = await model.generateContent(prompt);
console.log(result.response.text());ติดตั้ง SDK และเริ่มเรียก API ภายในไม่กี่นาที
ผู้คนพูดอะไรเกี่ยวกับ Gemini 3.1 Pro
ดูว่าชุมชนคิดอย่างไรเกี่ยวกับ Gemini 3.1 Pro
“คะแนน 77.1% ของ Gemini 3.1 Pro ถือเป็นการเปลี่ยนแปลงตลาดที่ก่อให้เกิดผลกระทบสูงสุด โดยเพิ่มขึ้นกว่าสองเท่าจากคะแนนสูงสุดเดิมบน ARC-AGI”
“benchmark การเขียนโค้ดไม่เคยโกหก โมเดลนี้เจอบั๊กใน repo ของผมที่ 3.5 และ GPT-4o พลาดไปอย่างสิ้นเชิง”
“ดราม่าเรื่อง Gemini 3.1 น่าสนใจมาก มันทำคะแนน benchmark ได้ถล่มทลาย แต่ผู้ใช้จริงกลับบอกว่าโทนและบรรยากาศยังไม่ค่อยสม่ำเสมอ”
“เอนจิน DeepThink อาจทำให้เกิดความล่าช้าอย่างมาก บางครั้งนานกว่า 90 วินาที เมื่อต้องประมวลผลงานที่ต้องใช้ตรรกะลึกซึ้ง”
“Context caching คือฟีเจอร์เด็ดของรุ่นนี้ ผมรันบอทตอบคำถามเอกสารทั้งหมดได้ในราคาถูกกว่า GPT-4o มาก”
“Gemini ล้มเหลวในการอภิปรายเกี่ยวกับ Python ในงานวางแผนที่ซับซ้อน... ตรรกะบางอย่างหายไปจากแผนสุดท้ายของมัน”
วิดีโอเกี่ยวกับ Gemini 3.1 Pro
ดูบทเรียน รีวิว และการสนทนาเกี่ยวกับ Gemini 3.1 Pro
“Gemini 3.1 Pro สร้างรายละเอียดของเจดีย์นี้ได้ดีที่สุดเท่าที่เคยมีมา”
“Gemini มี window ที่กว้างที่สุดถึงหนึ่งล้าน tokens”
“ความแม่นยำของ multimodal ในการประมวลผลเสียงดีกว่า 3.0 อย่างเห็นได้ชัด”
“throughput ของ tokens ยังคงมีเสถียรภาพแม้ในขณะที่ context window เต็ม”
“การเรียกคืนข้อมูลระยะยาวนั้นสมบูรณ์แบบแทบจะในทุกส่วนของล้าน tokens”
“ในปริศนาที่ไม่ควรจะอยู่ในข้อมูลฝึกฝน Gemini 3 series ทำผลงานได้เหนือกว่าโมเดลอื่นๆ ทั้งหมด”
“3.1 Pro สามารถลดเวลาการทำงานของ fine-tuning script จาก 300 วินาทีเหลือ 47 วินาทีได้จริง”
“ขั้นตอนตรรกะของ DeepThink สามารถเห็นได้ชัดเจนใน trace ซึ่งแสดงถึงการพิจารณาอย่างถี่ถ้วน”
“เรากำลังเข้าสู่ภาวะอิ่มตัวของ benchmark ที่เหลือเพียงแค่ ARC-AGI เท่านั้นที่สำคัญต่อความก้าวหน้า”
“วิถีสู่ AGI กำลังเร่งตัวขึ้นตามการก้าวกระโดดของการใช้เหตุผลเชิงนามธรรมเหล่านี้”
“ผมคิดว่า 3.1 ให้ความรู้สึกว่าเป็นการยกระดับขึ้นจริงๆ แม้จะเป็นเพียงเล็กน้อยก็ตาม”
“ดูเหมือนว่าจะทำผลงานได้ดีกว่า Gemini 3.0 Pro เมื่อทดสอบด้วย prompt เดียวกันเปรียบเทียบกัน”
“ความแม่นยำในการเขียนโค้ดสำหรับการ refactor Python ที่ซับซ้อนนั้นสูงที่สุดเท่าที่ผมเคยเห็นมา”
“ความน่าเชื่อถือของ API ได้รับการปรับปรุงอย่างมากในช่วงเดือนที่ผ่านมาของการทดสอบ”
“ประสิทธิภาพในการใช้งานจริงในที่สุดก็ทำได้ตามความคาดหวังของคะแนน benchmark”
เพิ่มพลังให้เวิร์กโฟลว์ของคุณด้วย ระบบอัตโนมัติ AI
Automatio รวมพลังของ AI agents การอัตโนมัติเว็บ และการผสานรวมอัจฉริยะเพื่อช่วยให้คุณทำงานได้มากขึ้นในเวลาน้อยลง
เคล็ดลับมือโปรสำหรับ Gemini 3.1 Pro
เคล็ดลับจากผู้เชี่ยวชาญเพื่อช่วยให้คุณใช้ประโยชน์สูงสุดจาก Gemini 3.1 Pro และได้ผลลัพธ์ที่ดีขึ้น
การเลือก Reasoning Tier
ใช้โหมด High thinking สำหรับงานคณิตศาสตร์หรือตรรกะที่ซับซ้อน แต่ให้เปลี่ยนเป็น Low สำหรับการจัดรูปแบบมาตรฐานเพื่อประหยัด compute
Context Caching
ใช้งาน context caching สำหรับเอกสารแบบ static เพื่อลดราคาค่าบริการ input ลงได้สูงสุดถึง 90% ต่อ 1 ล้าน tokens
Structured Artifacts
ใช้ประโยชน์จากความสามารถของโมเดลในการสร้างรายการงานที่มีโครงสร้างเพื่อความสะดวกในการกำกับดูแลโดยมนุษย์ระหว่างการทำงานแบบ agentic
Multimodal Prompting
รวม input ทั้งวิดีโอและเสียงเพื่อให้โมเดลได้รับบริบทที่ครบถ้วนของสถานการณ์จริง แทนที่จะใช้เพียงแค่คำบรรยายที่เป็นข้อความ
คำรับรอง
ผู้ใช้ของเราพูดอย่างไร
เข้าร่วมกับผู้ใช้ที่พึงพอใจนับพันที่ได้เปลี่ยนแปลงเวิร์กโฟลว์ของพวกเขา
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
ที่เกี่ยวข้อง AI Models
Claude Opus 4.7
Anthropic
Claude Opus 4.7 is Anthropic's flagship model with a 1-million-token context, adaptive reasoning, and 3.3x vision resolution for enterprise-scale agents.
Gemini 3.1 Flash Live Preview
Gemini 3.1 Flash Live Preview is Google's ultra-low-latency, audio-to-audio model featuring a 131K context window, high-fidelity multimodal reasoning, and...
GPT-5.5
OpenAI
GPT-5.5 is OpenAI's flagship frontier model with a 1M context window and five reasoning effort levels, optimized for autonomous agentic workflows and coding.
Grok-3
xAI
Grok-3 is xAI's flagship reasoning model, featuring deep logic deduction, a 128k context window, and real-time integration with X for live research and coding.
Kimi K3
Moonshot
Kimi K3 is Moonshot AI's 2.8T MoE model with a 1M token context window, native multimodal vision, and frontier-tier coding performance for complex agents.
GPT-5.2 Pro
OpenAI
GPT-5.2 Pro is OpenAI's 2025 flagship reasoning model featuring Extended Thinking for SOTA performance in mathematics, coding, and expert knowledge work.
Qwen 3.7 Max
alibaba
Qwen 3.7 Max is Alibaba’s flagship AI model for deep reasoning and autonomous agent tasks, featuring a 256k context window and top-tier coding performance.
Gemini 3 Pro
Google's Gemini 3 Pro is a multimodal powerhouse featuring a 1M token context window, native video processing, and industry-leading reasoning performance.
คำถามที่พบบ่อยเกี่ยวกับ Gemini 3.1 Pro
ค้นหาคำตอบสำหรับคำถามทั่วไปเกี่ยวกับ Gemini 3.1 Pro