GOV.UK Nasıl Scrape Edilir | Birleşik Krallık Hükümeti Web Scraper Rehberi
Hükümet yönergeleri, politika güncellemeleri ve resmi istatistikler için GOV.UK scraping rehberi. Yüksek değerli kamu sektörü verilerini nasıl ayıklayacağınızı...
Anti-Bot Koruması Tespit Edildi
- Hız sınırlama
- IP/oturum başına zamana bağlı istek sayısını sınırlar. Dönen proxy'ler, istek gecikmeleri ve dağıtılmış kazıma ile atlatılabilir.
- User-Agent Filtering
- IP engelleme
- Bilinen veri merkezi IP'lerini ve işaretlenmiş adresleri engeller. Etkili atlatma için konut veya mobil proxy'ler gerektirir.
GOV.UK Hakkında
GOV.UK'in sunduklarını ve çıkarılabilecek değerli verileri keşfedin.
GOV.UK, Birleşik Krallık hükümetinin tüm departman ve ajansların hizmet ve bilgilerine tek bir noktadan erişim sağlayan merkezi dijital portalıdır. Government Digital Service (GDS) tarafından oluşturulan platform, yüzlerce ayrı ajans sitesinin yerini şeffaflık ve verimlilik odaklı, birleşik ve kullanıcı dostu bir arayüzle almıştır.
Platform; yasal kılavuzlar, resmi istatistikler, politika raporları (white papers) ve ihale duyuruları dahil olmak üzere devasa bir veri deposu barındırır. Birleşik Krallık hükümetinin 'varsayılan olarak açık veri' politikasını izlemesi nedeniyle, GOV.UK'deki bilgilerin çoğu Open Government Licence altında yayınlanır; bu da burayı araştırmacılar, hukuk firmaları ve işletmeler için bir altın madeni haline getirir.
GOV.UK'i scrape etmek; regülasyon değişikliklerini izlemek, ekonomik göstergeleri takip etmek ve kamu ihale duyurularından rekabet analizi toplamak için son derece değerlidir. Kuruluşlar, uyumluluk iş akışlarını otomatize etmek ve sektörlerini etkileyen siyasi gelişmelerden haberdar olmak için bu verileri kullanır.
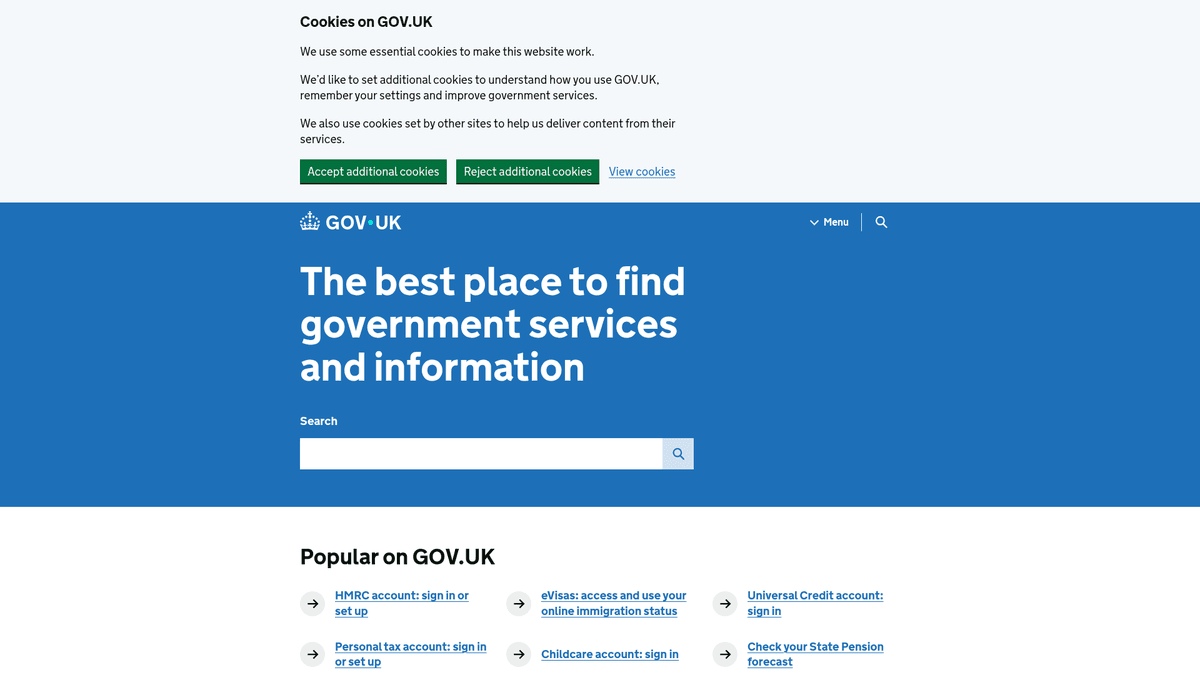
Neden GOV.UK Kazımalı?
GOV.UK'den veri çıkarmanın iş değerini ve kullanım durumlarını keşfedin.
Regülasyon uyumluluk güncellemelerini izlemek
Politika değişikliklerini gerçek zamanlı takip etmek
Ekonomik ve istatistiksel verileri bir araya getirmek
Kamu ihale ve sözleşme fırsatlarını keşfetmek
Hukuki ve tarihi belgeleri arşivlemek
Akademik sosyo-ekonomik araştırmalar yürütmek
Kazıma Zorlukları
GOV.UK kazırken karşılaşabileceğiniz teknik zorluklar.
Derin iç içe geçmiş hiyerarşik sayfa yapısı
Yüksek hacimli doküman ve PDF ekleri
5 dakikada 3.000 istek ile sınırlı katı rate limit
Farklı departmanlar arasındaki küçük düzen varyasyonları
AI ile GOV.UK Kazıyın
Kod gerekmez. AI destekli otomasyonla dakikalar içinde veri çıkarın.
Nasıl Çalışır
İhtiyacınızı tanımlayın
AI'ya GOV.UK üzerinden hangi verileri çıkarmak istediğinizi söyleyin. Doğal dilde yazmanız yeterli — kod veya seçiciler gerekmez.
AI verileri çıkarır
Yapay zekamız GOV.UK'i dolaşır, dinamik içerikleri işler ve tam olarak istediğiniz verileri çıkarır.
Verilerinizi alın
CSV, JSON olarak dışa aktarmaya veya doğrudan uygulamalarınıza göndermeye hazır temiz, yapılandırılmış veriler alın.
Kazıma için neden AI kullanmalısınız
AI, kod yazmadan GOV.UK'i kazımayı kolaylaştırır. Yapay zeka destekli platformumuz hangi verileri istediğinizi anlar — doğal dilde tanımlayın, AI otomatik olarak çıkarsın.
How to scrape with AI:
- İhtiyacınızı tanımlayın: AI'ya GOV.UK üzerinden hangi verileri çıkarmak istediğinizi söyleyin. Doğal dilde yazmanız yeterli — kod veya seçiciler gerekmez.
- AI verileri çıkarır: Yapay zekamız GOV.UK'i dolaşır, dinamik içerikleri işler ve tam olarak istediğiniz verileri çıkarır.
- Verilerinizi alın: CSV, JSON olarak dışa aktarmaya veya doğrudan uygulamalarınıza göndermeye hazır temiz, yapılandırılmış veriler alın.
Why use AI for scraping:
- Karmaşık navigasyon için kodsuz (no-code) konfigürasyon
- Politika değişikliklerini izlemek için zamanlanmış çalışmalar
- Google Sheets veya CSV formatına doğrudan dışa aktarma
- Gizli doküman linklerinin otomatik ayıklanması
GOV.UK için Kodsuz Web Kazıyıcılar
AI destekli kazımaya tıkla ve seç alternatifleri
Browse.ai, Octoparse, Axiom ve ParseHub gibi birçok kodsuz araç, kod yazmadan GOV.UK kazımanıza yardımcı olabilir. Bu araçlar genellikle veri seçmek için görsel arayüzler kullanır, ancak karmaşık dinamik içerik veya anti-bot önlemleriyle zorlanabilirler.
Kodsuz Araçlarla Tipik İş Akışı
Yaygın Zorluklar
Öğrenme eğrisi
Seçicileri ve çıkarma mantığını anlamak zaman alır
Seçiciler bozulur
Web sitesi değişiklikleri tüm iş akışınızı bozabilir
Dinamik içerik sorunları
JavaScript ağırlıklı siteler karmaşık çözümler gerektirir
CAPTCHA sınırlamaları
Çoğu araç CAPTCHA için manuel müdahale gerektirir
IP engelleme
Agresif scraping IP'nizin engellenmesine yol açabilir
GOV.UK için Kodsuz Web Kazıyıcılar
Browse.ai, Octoparse, Axiom ve ParseHub gibi birçok kodsuz araç, kod yazmadan GOV.UK kazımanıza yardımcı olabilir. Bu araçlar genellikle veri seçmek için görsel arayüzler kullanır, ancak karmaşık dinamik içerik veya anti-bot önlemleriyle zorlanabilirler.
Kodsuz Araçlarla Tipik İş Akışı
- Tarayıcı eklentisini kurun veya platforma kaydolun
- Hedef web sitesine gidin ve aracı açın
- Çıkarmak istediğiniz veri öğelerini tıklayarak seçin
- Her veri alanı için CSS seçicileri yapılandırın
- Birden fazla sayfayı scrape etmek için sayfalama kuralları ayarlayın
- CAPTCHA'ları yönetin (genellikle manuel çözüm gerektirir)
- Otomatik çalıştırmalar için zamanlama yapılandırın
- Verileri CSV, JSON'a aktarın veya API ile bağlanın
Yaygın Zorluklar
- Öğrenme eğrisi: Seçicileri ve çıkarma mantığını anlamak zaman alır
- Seçiciler bozulur: Web sitesi değişiklikleri tüm iş akışınızı bozabilir
- Dinamik içerik sorunları: JavaScript ağırlıklı siteler karmaşık çözümler gerektirir
- CAPTCHA sınırlamaları: Çoğu araç CAPTCHA için manuel müdahale gerektirir
- IP engelleme: Agresif scraping IP'nizin engellenmesine yol açabilir
Kod Örnekleri
import requests
from bs4 import BeautifulSoup
# İPUCU: Ham veri için çoğu GOV.UK URL'sinin sonuna .json ekleyin
url = 'https://www.gov.uk/search/news-and-communications'
headers = {'User-Agent': 'ResearchBot/1.0 (contact@example.com)'}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
for item in soup.select('.gem-c-document-list__item'):
title = item.select_one('.gem-c-document-list__item-title').text.strip()
link = item.select_one('a')['href']
print(f'Update: {title} | https://www.gov.uk{link}')
except Exception as e:
print(f'Error: {e}')Ne Zaman Kullanılır
Minimal JavaScript içeren statik HTML sayfaları için en iyisi. Bloglar, haber siteleri ve basit e-ticaret ürün sayfaları için idealdir.
Avantajlar
- ●En hızlı çalışma (tarayıcı yükü yok)
- ●En düşük kaynak tüketimi
- ●asyncio ile kolayca paralelleştirilebilir
- ●API'ler ve statik sayfalar için harika
Sınırlamalar
- ●JavaScript çalıştıramaz
- ●SPA'larda ve dinamik içerikte başarısız olur
- ●Karmaşık anti-bot sistemleriyle zorlanabilir
Kod ile GOV.UK Nasıl Kazınır
Python + Requests
import requests
from bs4 import BeautifulSoup
# İPUCU: Ham veri için çoğu GOV.UK URL'sinin sonuna .json ekleyin
url = 'https://www.gov.uk/search/news-and-communications'
headers = {'User-Agent': 'ResearchBot/1.0 (contact@example.com)'}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
for item in soup.select('.gem-c-document-list__item'):
title = item.select_one('.gem-c-document-list__item-title').text.strip()
link = item.select_one('a')['href']
print(f'Update: {title} | https://www.gov.uk{link}')
except Exception as e:
print(f'Error: {e}')Python + Playwright
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
try:
page.goto('https://www.gov.uk/search/all?keywords=data+protection')
page.wait_for_selector('.gem-c-document-list__item')
titles = page.locator('.gem-c-document-list__item-title').all_text_contents()
for t in titles:
print(f'Extracted: {t.strip()}')
finally:
browser.close()Python + Scrapy
import scrapy
class GovSpider(scrapy.Spider):
name = 'gov_spider'
start_urls = ['https://www.gov.uk/search/news-and-communications']
def parse(self, response):
for article in response.css('.gem-c-document-list__item'):
yield {
'title': article.css('.gem-c-document-list__item-title::text').get().strip(),
'link': response.urljoin(article.css('a::attr(href)').get())
}
next_page = response.css('a[rel="next"]::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
try {
await page.goto('https://www.gov.uk/search/news-and-communications', { waitUntil: 'networkidle2' });
const results = await page.evaluate(() =>
Array.from(document.querySelectorAll('.gem-c-document-list__item-title'))
.map(el => el.innerText.trim())
);
console.log(results);
} finally {
await browser.close();
}
})();GOV.UK Verileriyle Neler Yapabilirsiniz
GOV.UK verilerinden pratik uygulamaları ve içgörüleri keşfedin.
Regülasyon Uyarı Sistemi
Hukuk ve uyumluluk ekipleri, yasa değişikliklerini anında tespit etmek için belirli kılavuz kategorilerini izleyebilir.
Nasıl uygulanır:
- 1'Guidance and Regulation' bölümünü günlük olarak scrape edin.
- 2Doküman metinlerini ve son güncelleme zaman damgalarını ayıklayın.
- 3Farklılıkları belirlemek için içeriği önceki sürümlerle karşılaştırın.
- 4İlgili kurum içi paydaşlara otomatik uyarılar gönderin.
GOV.UK sitesinden veri çıkarmak ve kod yazmadan bu uygulamaları oluşturmak için Automatio kullanın.
GOV.UK Verileriyle Neler Yapabilirsiniz
- Regülasyon Uyarı Sistemi
Hukuk ve uyumluluk ekipleri, yasa değişikliklerini anında tespit etmek için belirli kılavuz kategorilerini izleyebilir.
- 'Guidance and Regulation' bölümünü günlük olarak scrape edin.
- Doküman metinlerini ve son güncelleme zaman damgalarını ayıklayın.
- Farklılıkları belirlemek için içeriği önceki sürümlerle karşılaştırın.
- İlgili kurum içi paydaşlara otomatik uyarılar gönderin.
- İhale Fırsatı Takipçisi
Satış ekipleri, yeni hükümet sözleşme fırsatlarını bulmak için ihale duyurularını scrape edebilir.
- GOV.UK üzerindeki 'Procurement' arama kategorisini hedefleyin.
- Son başvuru tarihlerini, iletişim e-postalarını ve sözleşme değerlerini scrape edin.
- Sonuçları işinizle ilgili endüstri anahtar kelimelerine göre filtreleyin.
- Potansiyel müşterileri takip için doğrudan bir CRM sistemine aktarın.
- Ekonomik Trend Analizi
Ekonomistler, Birleşik Krallık performansı üzerine boylamsal çalışmalar yapmak için istatistiksel yayınları bir araya getirebilir.
- İstatistiksel veri serisi URL'lerini belirleyin.
- CSV veya Excel dosyalarına giden doğrudan linkleri scrape edin.
- Otomatik script'ler kullanarak veri setlerini indirin ve temizleyin.
- Verileri görselleştirme için merkezi bir veritabanında birleştirin.
- Kamu Politikası Arşivi
Gazeteciler ve araştırmacılar, resmi hükümet duyurularından oluşan aranabilir bir arşiv oluşturabilir.
- 'News and Communications' bölümünü sürekli olarak scrape edin.
- Başlıkları, metin gövdelerini ve departman etiketlerini ayıklayın.
- Verileri Elasticsearch gibi aranabilir bir platformda indeksleyin.
- Belirli politika anahtar kelimelerinin duygu analizini ve sıklığını analiz edin.
- Otomatik Danışmanlık Botları
Sivil toplum kuruluşları, vatandaşların yardım bilgilerini bulmasına destek olan chatbot'ları güçlendirmek için resmi kılavuzları kullanabilir.
- Yardım ve konut rehberliği sayfalarını scrape edin.
- Ayıklanan metni RAG (Retrieval-Augmented Generation) için bir vector veritabanına eşleyin.
- GOV.UK içeriği değiştiğinde veritabanını yenilemek için bir tetikleyici ayarlayın.
- Kullanıcı sorularına gerçek zamanlı ve doğru yanıtlar sağlayın.
- Hibe Keşif Motoru
Eğitim kurumları, araştırma projeleri için hibe ve finansman fırsatlarını bulabilir.
- 'Education, Training and Skills' finansman kategorisini scrape edin.
- Uygunluk kriterlerini ve uygulama son tarihlerini ayıklayın.
- Hibeleri departmana ve finansman miktarına göre kategorize edin.
- Öğretim üyeleri için haftalık e-posta özetlerini otomatize edin.
İş akışınızı güçlendirin Yapay Zeka Otomasyonu
Automatio, yapay zeka ajanlari, web otomasyonu ve akilli entegrasyonlarin gucunu birlestirerek daha az zamanda daha fazlasini basarmaniza yardimci olur.
GOV.UK Kazımak için Pro İpuçları
GOV.UK'den başarılı veri çıkarmak için uzman tavsiyeler.
HTML parsing işlemiyle uğraşmadan temel metadataya erişmek için hemen hemen her GOV.UK URL'sinin sonuna '.json' ekleyin.
Standart GDS Design System'ın bir parçası oldukları için 'gem-c-' ile başlayan CSS class'larını kullanarak öğeleri tanımlayın.
Botunuzun sorun yaratması durumunda GDS'nin sizinle iletişime geçebilmesi için e-posta adresinizi içeren açıklayıcı bir User-Agent string'i ayarlayın.
Geçici IP yasaklarından kaçınmak için 5 dakikada 3.000 istek olan rate limit sınırının altında kalın.
Büyük ölçekli veri keşfi için temiz ve sayfalandırılmış doküman listeleri sunan 'Search' sayfalarına odaklanın.
Değişmeyen içeriği tekrar scrape etmekten kaçınmak için 'Last Updated' zaman damgasını kontrol edin.
Referanslar
Kullanicilarimiz Ne Diyor
Is akisini donusturen binlerce memnun kullaniciya katilin
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
İlgili Web Scraping
GOV.UK Hakkında Sık Sorulan Sorular
GOV.UK hakkında sık sorulan soruların cevaplarını bulun