
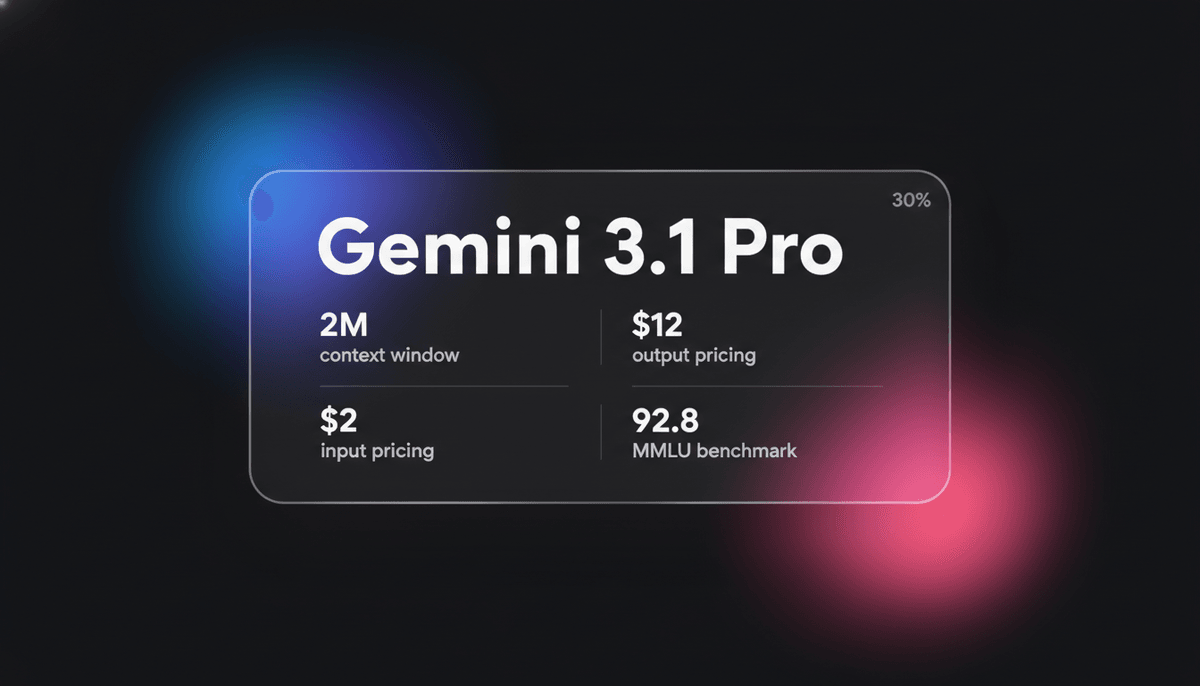
Gemini 3.1 Pro
Gemini 3.1 Pro, DeepThink reasoning motoru, 1M+ context window ve sektör lideri ARC-AGI mantık skorları içeren Google'ın seçkin multimodal modelidir.
Gemini 3.1 Pro Hakkında
Gemini 3.1 Pro'in yetenekleri, özellikleri ve kullanım yolları hakkında bilgi edinin.
Gemini 3.1 Pro, gelişmiş bir multimodal işleme motoruyla yerel olarak eşleştirilmiş Sparse Mixture-of-Experts (MoE) çerçevesinin olgun bir uygulamasını temsil eder. Mimarinin öne çıkan özelliği, modelin bir output token'ı taahhüt etmeden önce dahili olarak düşünmesine izin veren DeepThink System 2 katmanının demokratikleşmesidir. Bu model; geliştiricilerin latency, maliyet ve reasoning derinliği arasındaki dengeyi açıkça kontrol etmelerine olanak tanıyan Düşük, Orta ve Yüksek olmak üzere üç kademeli benzersiz bir düşünme sistemi sunar.
Devasa 1 milyon tokenlık context window ile Gemini 3.1 Pro; finans, veri analitiği ve tüm kod deposu geçişleri gibi karmaşık iş akışları için yüksek oranda optimize edilmiştir. ARC-AGI-2 benchmark testinde benzeri görülmemiş bir şekilde %77,1 puan alarak yeni mantıksal kalıpları çözme konusunda ortaya çıkan bir yetenek sergiler. Bu, hem düşük latency'li multimodal etkileşimlere hem de otonom agentic görevler için üst düzey bilişsel performansa ihtiyaç duyan geliştiriciler için onu tercih edilen bir seçenek haline getirir.
Gemini 3.1 Pro için Kullanım Alanları
Harika sonuçlar elde etmek için Gemini 3.1 Pro'i kullanmanın farklı yollarını keşfedin.
Tüm Kod Deposu Analizi
Yeniden düzenleme (refactoring) ve bağımlılık eşlemesi için tüm yazılım depolarını 1M context window kullanarak işleme.
Otonom Agent Komiteleri
İç sub-agent'ların yürütmeden önce çözümleri tartışıp doğruladığı çok adımlı agentic iş akışlarını yönetme.
Bilimsel Araştırma Sentezi
Yapılandırılmış istihbarat ve olgusal içgörüler elde etmek için binlerce araştırma makalesini ve karmaşık veri setini analiz etme.
Multimodal İçerik Oluşturma
Karmaşık öğretim materyalleri ve etkileşimli medya oluşturmak için metin, görsel ve sesleri eşzamanlı işleme.
Terminal Tabanlı Otomasyon
Gelişmiş reasoning modları sayesinde yüksek hassasiyetle karmaşık bash komutları çalıştırma ve dosya sistemlerini manipüle etme.
Kurumsal Veri Denetimi
Yapılandırılmamış finansal verileri ve hukuki belgeleri ayrıştırarak, neredeyse kusursuz olgusal geri çağırma ile uyumluluk açıklarını belirleme.
Güçlü Yönler
Sınırlamalar
API Hızlı Başlangıç
google/gemini-3.1-pro-preview
import { GoogleGenAI } from "@google/genai";
const genAI = new GoogleGenAI(process.env.GOOGLE_API_KEY);
const model = genAI.getGenerativeModel({
model: "gemini-3.1-pro-preview",
thinkingConfig: { tier: "high" }
});
const prompt = "Bu kod tabanının tamamını güvenlik açıkları için analiz et.";
const result = await model.generateContent(prompt);
console.log(result.response.text());SDK'yı yükleyin ve dakikalar içinde API çağrıları yapmaya başlayın.
İnsanlar Gemini 3.1 Pro Hakkında Ne Diyor
Topluluğun Gemini 3.1 Pro hakkında ne düşündüğünü görün
“Gemini 3.1 Pro'nun %77,1 puanı en yıkıcı pazar değişimini temsil ediyor; ARC-AGI'deki önceki en yüksek puanı ikiye katlıyor.”
“Kodlama benchmark'ları yalan söylemez. Bu model, depomda 3.5 ve GPT-4o'nun tamamen gözden kaçırdığı bir hata buldu.”
“Gemini 3.1 kaosu gerçekten ilginç. Benchmark'ları yerle bir etti ancak gerçek kullanıcılar tonun ve hissin tutarsız olduğunu söylüyor.”
“DeepThink motoru, derin mantık gerektiren görevleri işlerken bazen 90 saniyeyi aşan ciddi gecikmelere yol açabiliyor.”
“Context caching buradaki en önemli özellik. GPT-4o'ya kıyasla kuruşlar karşılığında tüm bir dokümantasyon botunu çalıştırıyorum.”
“Gemini, karmaşık bir planlama görevinde Python hakkında hiç konuşamadı... bazı mantık yürütmeleri final planında hiç yoktu.”
Gemini 3.1 Pro Hakkında Videolar
Gemini 3.1 Pro hakkında eğitimler, incelemeler ve tartışmalar izleyin
“Gemini 3.1 Pro bu pagodanın şimdiye kadarki en detaylı versiyonunu oluşturuyor”
“Gemini açık ara bir milyon tokenlık en geniş pencereye sahip”
“Ses işlemedeki multimodal sadakat, 3.0'dan fark edilir derecede daha iyi”
“Token throughput, context window dolduğunda bile stabil kalıyor”
“Uzun vadeli geri çağırma, bir milyon tokenın tamamında neredeyse kusursuz”
“Eğitim verisinde olmaması gereken bulmacalarda Gemini 3 serisi tüm diğer modelleri geride bırakıyor”
“3.1 Pro gerçekten bir fine-tuning betiğinin çalışma süresini 300 saniyeden 47 saniyeye indirebilir”
“DeepThink mantık adımları iz üzerinde açıkça görülebiliyor, gerçek bir değerlendirme var”
“İlerleme için sadece ARC-AGI'nin gerçekten önemli olduğu benchmark doygunluğuna ulaşıyoruz”
“AGI yörüngesi, bu soyut reasoning sıçramalarına dayanarak hızlanıyor”
“3.1'in çok hafif bir fark olsa bile gerçekten bir adım ileri olduğunu düşünüyorum”
“Aynı prompt'ları yan yana test ettiğimizde Gemini 3.0 Pro'dan daha iyi performans gösteriyor”
“Karmaşık Python düzenlemelerinde kodlama doğruluğu gördüğüm en yüksek seviyede”
“API güvenilirliği, testlerin son bir ayında önemli ölçüde iyileşti”
“Gerçek dünya performansı sonunda benchmark skorlarının getirdiği beklentiyi karşılıyor”
İş akışınızı güçlendirin Yapay Zeka Otomasyonu
Automatio, yapay zeka ajanlari, web otomasyonu ve akilli entegrasyonlarin gucunu birlestirerek daha az zamanda daha fazlasini basarmaniza yardimci olur.
Gemini 3.1 Pro için Pro İpuçları
Gemini 3.1 Pro'den en iyi şekilde yararlanmak için uzman ipuçları.
Reasoning Kademe Seçimi
Karmaşık matematik veya mantık işlemleri için High thinking modunu kullanın, ancak standart formatlama işlemleri için compute maliyetinden tasarruf etmek adına Low moduna geçin.
Context Caching
Statik belgeler için context caching kullanarak milyon token başına input maliyetlerini %90'a kadar düşürün.
Yapılandırılmış Artifacts
Agentic çalışma süreçlerinde insan gözetimini kolaylaştırmak için modelin yapılandırılmış görev listeleri oluşturma yeteneğinden yararlanın.
Multimodal Prompting
Modele yalnızca metin tanımlamaları yerine gerçek dünya senaryolarının tam bağlamını vermek için video ve ses girişlerini birleştirin.
Referanslar
Kullanicilarimiz Ne Diyor
Is akisini donusturen binlerce memnun kullaniciya katilin
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
İlgili AI Models
Claude Opus 4.7
Anthropic
Claude Opus 4.7 is Anthropic's flagship model with a 1-million-token context, adaptive reasoning, and 3.3x vision resolution for enterprise-scale agents.
Gemini 3.1 Flash Live Preview
Gemini 3.1 Flash Live Preview is Google's ultra-low-latency, audio-to-audio model featuring a 131K context window, high-fidelity multimodal reasoning, and...
GPT-5.5
OpenAI
GPT-5.5 is OpenAI's flagship frontier model with a 1M context window and five reasoning effort levels, optimized for autonomous agentic workflows and coding.
Grok-3
xAI
Grok-3 is xAI's flagship reasoning model, featuring deep logic deduction, a 128k context window, and real-time integration with X for live research and coding.
Kimi K3
Moonshot
Kimi K3 is Moonshot AI's 2.8T MoE model with a 1M token context window, native multimodal vision, and frontier-tier coding performance for complex agents.
GPT-5.2 Pro
OpenAI
GPT-5.2 Pro is OpenAI's 2025 flagship reasoning model featuring Extended Thinking for SOTA performance in mathematics, coding, and expert knowledge work.
Qwen 3.7 Max
alibaba
Qwen 3.7 Max is Alibaba’s flagship AI model for deep reasoning and autonomous agent tasks, featuring a 256k context window and top-tier coding performance.
Gemini 3 Pro
Google's Gemini 3 Pro is a multimodal powerhouse featuring a 1M token context window, native video processing, and industry-leading reasoning performance.
Gemini 3.1 Pro Hakkında Sık Sorulan Sorular
Gemini 3.1 Pro hakkında sık sorulan soruların cevaplarını bulun