
Gemini 3.1 Pro
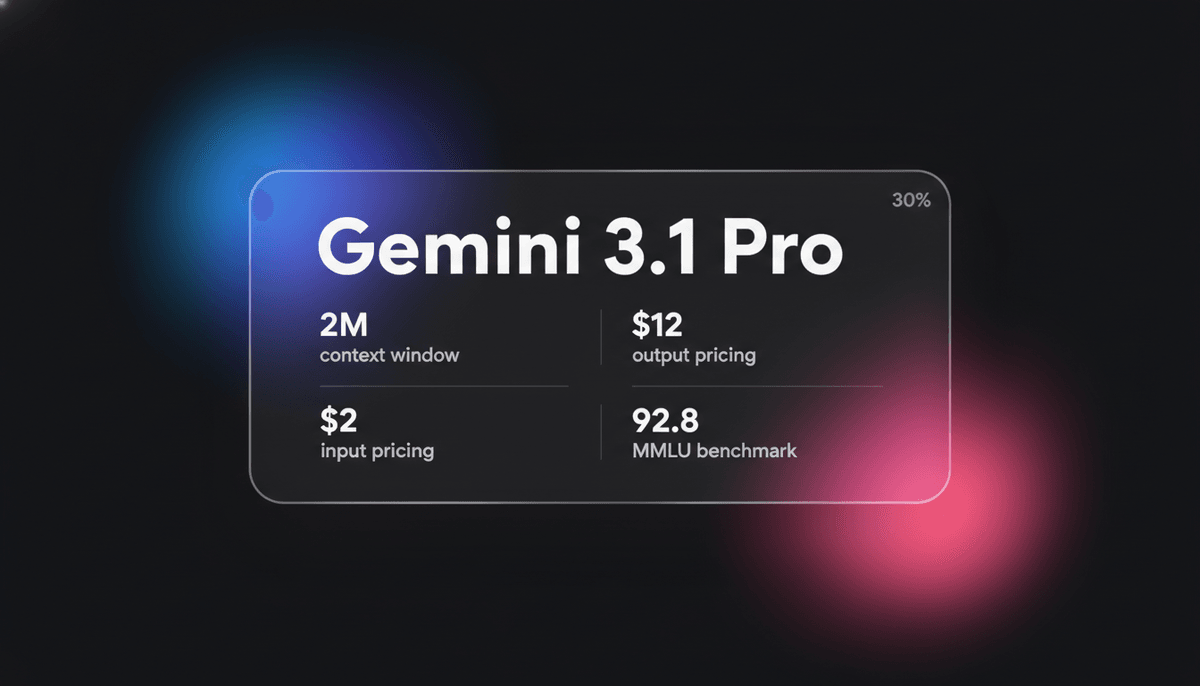
Gemini 3.1 Pro — це елітна multimodal модель Google з рушієм reasoning DeepThink, context window 1M+ та провідними в галузі показниками логіки ARC-AGI.
Про Gemini 3.1 Pro
Дізнайтеся про можливості Gemini 3.1 Pro, функції та як це може допомогти вам досягти кращих результатів.
Gemini 3.1 Pro представляє собою зрілу реалізацію фреймворку Sparse Mixture-of-Experts (MoE), що нативно поєднується з просунутим механізмом multimodal обробки. Визначною рисою архітектури є демократизація рівня DeepThink System 2, який дозволяє моделі внутрішньо обмірковувати рішення перед виведенням токена. Ця модель представляє унікальну трирівневу систему мислення, Low, Medium та High, що дає розробникам можливість прямо контролювати компроміс між latency, вартістю та глибиною reasoning.
Завдяки масивному context window у 1 мільйон tokens, Gemini 3.1 Pro оптимізована для складних робочих процесів у фінансах, аналітиці даних та міграції цілих репозиторіїв коду. Вона демонструє здатність вирішувати нові логічні паттерни, набираючи безпрецедентні 77.1% у benchmark ARC-AGI-2. Це робить її кращим вибором для розробників, яким потрібні як низьколатентні multimodal взаємодії, так і висока когнітивна продуктивність для виконання agentic завдань.
Випадки використання для Gemini 3.1 Pro
Відкрийте різні способи використання Gemini 3.1 Pro для досягнення чудових результатів.
Аналіз цілих репозиторіїв коду
Використання context window в 1 млн tokens для завантаження цілих програмних репозиторіїв для рефакторингу та побудови карти залежностей.
Комітети автономних агентів
Керування багатоетапними agentic робочими процесами, де внутрішні субагенти обговорюють та перевіряють рішення перед виконанням.
Синтез наукових досліджень
Аналіз тисяч наукових робіт та складних наборів даних для вилучення структурованої інформації та фактичних інсайтів.
Створення multimodal контенту
Одночасна обробка тексту, зображень та аудіо для генерації складних навчальних матеріалів та інтерактивного медіа.
Автоматизація через термінал
Виконання складних bash-команд та керування файловими системами з високою точністю через просунуті режими reasoning.
Аудит корпоративних даних
Парсинг неструктурованих фінансових даних та юридичних документів для виявлення порушень комплаєнсу з майже ідеальним запам'ятовуванням фактів.
Сильні сторони
Обмеження
Швидкий старт API
google/gemini-3.1-pro-preview
import { GoogleGenAI } from "@google/genai";
const genAI = new GoogleGenAI(process.env.GOOGLE_API_KEY);
const model = genAI.getGenerativeModel({
model: "gemini-3.1-pro-preview",
thinkingConfig: { tier: "high" }
});
const prompt = "Analyze this entire codebase for security vulnerabilities.";
const result = await model.generateContent(prompt);
console.log(result.response.text());Встановіть SDK і почніть робити API-виклики за лічені хвилини.
Що кажуть люди про Gemini 3.1 Pro
Подивіться, що думає спільнота про Gemini 3.1 Pro
“Результат 77.1% у Gemini 3.1 Pro, це найбільш руйнівний зсув на ринку; він більш ніж удвічі перевищує попередній рекорд на ARC-AGI.”
“Benchmark кодування не брешуть. Ця модель знайшла баг у моєму репозиторії, який повністю пропустили 3.5 та GPT-4o.”
“Шум навколо Gemini 3.1 справді цікавий. Модель розгромила benchmark, але реальні користувачі кажуть, що тон і вайб непослідовні.”
“Двигун DeepThink може призводити до значних затримок, іноді понад 90 секунд, при виконанні завдань, що потребують глибокої логіки.”
“Context caching, це головна фіча. Я запускаю цілий бот документації за копійки порівняно з GPT-4o.”
“Gemini не змогла обговорити Python у складному завданні з планування... деяка логіка просто відсутня у фінальному плані.”
Відео про Gemini 3.1 Pro
Дивіться навчальні матеріали, огляди та обговорення про Gemini 3.1 Pro
“Gemini 3.1 Pro створює найдетальнішу версію цієї пагоди на даний момент”
“Gemini має значно ширше вікно в один мільйон tokens”
“Multimodal точність в обробці аудіо помітно краща, ніж у 3.0”
“Throughput tokens залишається стабільним, навіть коли context window заповнюється”
“Відтворення довгострокової пам'яті майже ідеальне в межах усього мільйона tokens”
“У задачах, яких не повинно бути в навчальних даних, серія Gemini 3 перевершує всі інші моделі”
“3.1 Pro справді може скоротити час виконання скрипта для fine-tuning з 300 до 47 секунд”
“Кроки логіки DeepThink чітко видно в логах, що демонструє реальне обмірковування”
“Ми досягаємо насичення benchmark, де для прогресу важливим залишається лише ARC-AGI”
“Траєкторія AGI прискорюється на основі цих стрибків в абстрактному reasoning”
“Я справді вважаю, що 3.1, це крок вперед, навіть якщо дуже незначний”
“Схоже, вона перевершує Gemini 3.0 Pro при порівняльному тестуванні однакових prompt”
“Точність кодування у складних рефакторингах на Python найвища, яку я бачив”
“Надійність API значно покращилася за останній місяць тестування”
“Продуктивність у реальних умовах нарешті відповідає хайпу навколо результатів benchmark”
Прискорте вашу роботу з AI-автоматизацією
Automatio поєднує силу AI-агентів, веб-автоматизації та розумних інтеграцій, щоб допомогти вам досягти більшого за менший час.
Професійні поради для Gemini 3.1 Pro
Експертні поради, які допоможуть вам отримати максимум від Gemini 3.1 Pro та досягти кращих результатів.
Вибір рівня reasoning
Використовуйте режим High для складної математики чи логіки, але перемикайтеся на Low для стандартного форматування, щоб зекономити обчислювальні ресурси.
Context caching
Впроваджуйте context caching для статичної документації, щоб знизити витрати на вхідні дані до 90% за мільйон tokens.
Структуровані артефакти
Використовуйте здатність моделі створювати структуровані списки завдань для легшого контролю з боку людини під час agentic процесів.
Multimodal prompting
Поєднуйте відео та аудіо входи, щоб надати моделі повний контекст реальних сценаріїв, а не лише текстовий опис.
Відгуки
Що кажуть наші користувачі
Приєднуйтесь до тисяч задоволених користувачів, які трансформували свою роботу
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Пов'язані AI Models
Claude Opus 4.7
Anthropic
Claude Opus 4.7 is Anthropic's flagship model with a 1-million-token context, adaptive reasoning, and 3.3x vision resolution for enterprise-scale agents.
Gemini 3.1 Flash Live Preview
Gemini 3.1 Flash Live Preview is Google's ultra-low-latency, audio-to-audio model featuring a 131K context window, high-fidelity multimodal reasoning, and...
GPT-5.5
OpenAI
GPT-5.5 is OpenAI's flagship frontier model with a 1M context window and five reasoning effort levels, optimized for autonomous agentic workflows and coding.
Grok-3
xAI
Grok-3 is xAI's flagship reasoning model, featuring deep logic deduction, a 128k context window, and real-time integration with X for live research and coding.
Kimi K3
Moonshot
Kimi K3 is Moonshot AI's 2.8T MoE model with a 1M token context window, native multimodal vision, and frontier-tier coding performance for complex agents.
GPT-5.2 Pro
OpenAI
GPT-5.2 Pro is OpenAI's 2025 flagship reasoning model featuring Extended Thinking for SOTA performance in mathematics, coding, and expert knowledge work.
Qwen 3.7 Max
alibaba
Qwen 3.7 Max is Alibaba’s flagship AI model for deep reasoning and autonomous agent tasks, featuring a 256k context window and top-tier coding performance.
Gemini 3 Pro
Google's Gemini 3 Pro is a multimodal powerhouse featuring a 1M token context window, native video processing, and industry-leading reasoning performance.
Часті запитання про Gemini 3.1 Pro
Знайдіть відповіді на поширені запитання про Gemini 3.1 Pro