كيفية سحب بيانات باقات جولات ومراجعات Thrillophilia
تعلم كيفية سحب بيانات Thrillophilia لاستخراج أسعار باقات الجولات، ومسارات الرحلات، ومراجعات العملاء. بيانات سفر عالية الجودة لتحليل السوق ومراقبته.
تم اكتشاف حماية ضد البوتات
- Cloudflare
- جدار حماية تطبيقات الويب وإدارة البوتات على مستوى المؤسسات. يستخدم تحديات JavaScript وCAPTCHA وتحليل السلوك. يتطلب أتمتة المتصفح بإعدادات التخفي.
- تحديد معدل الطلبات
- يحد من الطلبات لكل IP/جلسة عبر الوقت. يمكن تجاوزه بالبروكسيات الدوارة وتأخير الطلبات والاستخراج الموزع.
- حظر IP
- يحظر عناوين IP المعروفة لمراكز البيانات والعناوين المُعلَّمة. يتطلب بروكسيات سكنية أو محمولة للتجاوز الفعال.
- بصمة المتصفح
- يحدد البوتات من خلال خصائص المتصفح: canvas وWebGL والخطوط والإضافات. يتطلب التزييف أو ملفات تعريف متصفح حقيقية.
حول Thrillophilia
اكتشف ما يقدمه Thrillophilia وما هي البيانات القيمة التي يمكن استخراجها.
الوجهة الرائدة لتجارب السفر
Thrillophilia هي منصة بارزة للسفر والمغامرات مقرها الهند توفر باقات جولات شاملة تحت إشراف خبراء في جميع أنحاء العالم. تتخصص في تجارب السفر المنسقة التي تتراوح من بعثات الهيمالايا وجولات التراث في راجستان إلى الرحلات الدولية في أوروبا وجنوب شرق آسيا والشرق الأوسط.
غنى البيانات وقيمتها
تتميز المنصة بقوائم مفصلة للجولات متعددة الأيام، وباقات شهر العسل، ومغامرات المجموعات. تحتوي القوائم في Thrillophilia على ثروة من البيانات المهيكلة بما في ذلك مسارات الرحلة المحددة، وتفاصيل الإقامة ليلة بليلة، والأسعار المخفضة، وتقييمات المستخدمين، والمراجعات الوصفية. هذه المعلومات قيمة للغاية لوكالات السفر وباحثي السوق.
لماذا تهم تحليل البيانات
بالنسبة للشركات في قطاع السفر، يوفر سحب بيانات Thrillophilia ميزة تنافسية. من خلال مراقبة تقلبات الأسعار وانطباعات العملاء عبر المراجعات، يمكن للشركات تحسين عروضها الخاصة وتحديد اتجاهات السفر الناشئة قبل أن تصبح سائدة.
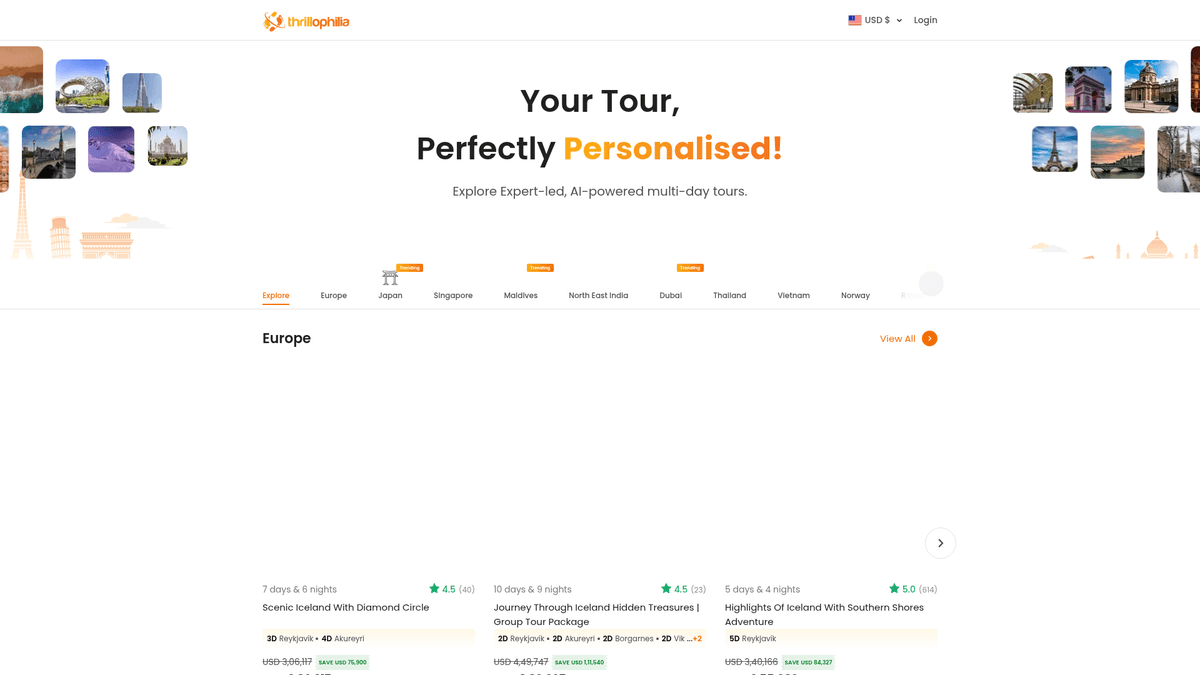
لماذا تجريد Thrillophilia؟
اكتشف القيمة التجارية وحالات الاستخدام لاستخراج البيانات من Thrillophilia.
مراقبة أسعار المنافسين لباقات جولات مماثلة في الوقت الفعلي
تحليل مشاعر العملاء وجودة الخدمة من خلال مراجعات المستخدمين المفصلة
تجميع مسارات الرحلة المعقدة لتحليل اتجاهات السوق العالمية
تحديد وجهات السفر الشهيرة والناشئة للتخطيط الاستراتيجي
تتبع مقاييس الموثوقية والأداء لمنظمي الرحلات المحليين
تزويد نماذج AI ببيانات مسارات الرحلة المهيكلة للتخطيط الآلي للسفر
تحديات التجريد
التحديات التقنية التي قد تواجهها عند تجريد Thrillophilia.
آليات حماية البوتات القوية من Cloudflare
تحميل المحتوى الديناميكي عبر إطار عمل Next.js و React
هياكل HTML المتداخلة والمعقدة لمسارات الرحلة لعدة أيام
سياسات تقييد المعدل (rate limiting) الصارمة على الطلبات عالية التكرار
بصمة المتصفح (browser fingerprinting) التي تكشف الـ headless browsers المؤتمتة
استخرج بيانات Thrillophilia بالذكاء الاصطناعي
لا حاجة للبرمجة. استخرج البيانات في دقائق مع الأتمتة المدعومة بالذكاء الاصطناعي.
كيف يعمل
صف ما تحتاجه
أخبر الذكاء الاصطناعي بالبيانات التي تريد استخراجها من Thrillophilia. فقط اكتب بلغة طبيعية — لا حاجة لأكواد أو محددات.
الذكاء الاصطناعي يستخرج البيانات
ذكاؤنا الاصطناعي يتصفح Thrillophilia، يتعامل مع المحتوى الديناميكي، ويستخرج بالضبط ما طلبته.
احصل على بياناتك
احصل على بيانات نظيفة ومنظمة جاهزة للتصدير كـ CSV أو JSON أو إرسالها مباشرة إلى تطبيقاتك.
لماذا تستخدم الذكاء الاصطناعي للاستخراج
الذكاء الاصطناعي يجعل استخراج بيانات Thrillophilia سهلاً بدون كتابة أكواد. منصتنا المدعومة بالذكاء الاصطناعي تفهم البيانات التي تريدها — فقط صفها بلغة طبيعية والذكاء الاصطناعي يستخرجها تلقائياً.
How to scrape with AI:
- صف ما تحتاجه: أخبر الذكاء الاصطناعي بالبيانات التي تريد استخراجها من Thrillophilia. فقط اكتب بلغة طبيعية — لا حاجة لأكواد أو محددات.
- الذكاء الاصطناعي يستخرج البيانات: ذكاؤنا الاصطناعي يتصفح Thrillophilia، يتعامل مع المحتوى الديناميكي، ويستخرج بالضبط ما طلبته.
- احصل على بياناتك: احصل على بيانات نظيفة ومنظمة جاهزة للتصدير كـ CSV أو JSON أو إرسالها مباشرة إلى تطبيقاتك.
Why use AI for scraping:
- يتجاوز تدابير مكافحة البوتات المتطورة مثل Cloudflare تلقائياً
- واجهة بدون كود (no-code) تسمح ببناء أدوات سحب بيانات السفر دون موارد مطورين
- يتعامل مع رندر JavaScript والمحتوى الديناميكي بسهولة
- تتيح عمليات السحب المجدولة مراقبة يومية مؤتمتة للأسعار
- تكامل مباشر مع Google Sheets لتصور البيانات بشكل فوري
أدوات تجريد الويب بدون كود لـThrillophilia
بدائل النقر والتأشير للتجريد المدعوم بالذكاء الاصطناعي
يمكن لعدة أدوات بدون كود مثل Browse.ai وOctoparse وAxiom وParseHub مساعدتك في تجريد Thrillophilia بدون كتابة كود. تستخدم هذه الأدوات عادةً واجهات مرئية لتحديد البيانات، على الرغم من أنها قد تواجه صعوبة مع المحتوى الديناميكي المعقد أو إجراءات مكافحة البوتات.
سير العمل النموذجي مع أدوات بدون كود
التحديات الشائعة
منحنى التعلم
فهم المحددات ومنطق الاستخراج يستغرق وقتًا
المحددات تتعطل
تغييرات الموقع يمكن أن تكسر سير العمل بالكامل
مشاكل المحتوى الديناميكي
المواقع الغنية بـ JavaScript تتطلب حلولاً معقدة
قيود CAPTCHA
معظم الأدوات تتطلب تدخلاً يدويًا لـ CAPTCHA
حظر IP
الاستخراج المكثف قد يؤدي إلى حظر عنوان IP الخاص بك
أدوات تجريد الويب بدون كود لـThrillophilia
يمكن لعدة أدوات بدون كود مثل Browse.ai وOctoparse وAxiom وParseHub مساعدتك في تجريد Thrillophilia بدون كتابة كود. تستخدم هذه الأدوات عادةً واجهات مرئية لتحديد البيانات، على الرغم من أنها قد تواجه صعوبة مع المحتوى الديناميكي المعقد أو إجراءات مكافحة البوتات.
سير العمل النموذجي مع أدوات بدون كود
- تثبيت إضافة المتصفح أو التسجيل في المنصة
- الانتقال إلى الموقع المستهدف وفتح الأداة
- اختيار عناصر البيانات المراد استخراجها بالنقر
- تكوين محددات CSS لكل حقل بيانات
- إعداد قواعد التصفح لاستخراج صفحات متعددة
- التعامل مع CAPTCHA (غالبًا يتطلب حلاً يدويًا)
- تكوين الجدولة للتشغيل التلقائي
- تصدير البيانات إلى CSV أو JSON أو الاتصال عبر API
التحديات الشائعة
- منحنى التعلم: فهم المحددات ومنطق الاستخراج يستغرق وقتًا
- المحددات تتعطل: تغييرات الموقع يمكن أن تكسر سير العمل بالكامل
- مشاكل المحتوى الديناميكي: المواقع الغنية بـ JavaScript تتطلب حلولاً معقدة
- قيود CAPTCHA: معظم الأدوات تتطلب تدخلاً يدويًا لـ CAPTCHA
- حظر IP: الاستخراج المكثف قد يؤدي إلى حظر عنوان IP الخاص بك
أمثلة الكود
import requests
from bs4 import BeautifulSoup
# Thrillophilia uses Cloudflare, so standard requests might fail without proper headers or session management
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
url = 'https://www.thrillophilia.com/destinations/bali/tours'
def scrape_thrill(url):
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Selectors vary based on specific destination pages
tours = soup.select('.tour-card')
for tour in tours:
title = tour.find('h3').text.strip()
price = tour.select_one('.price-value').text.strip() if tour.select_one('.price-value') else 'N/A'
print(f'Tour: {title} | Price: {price}')
except Exception as e:
print(f'Error occurred: {e}')
scrape_thrill(url)متى تستخدم
الأفضل لصفحات HTML الثابتة مع حد أدنى من JavaScript. مثالي للمدونات ومواقع الأخبار وصفحات المنتجات البسيطة.
المزايا
- ●أسرع تنفيذ (بدون عبء المتصفح)
- ●أقل استهلاك للموارد
- ●سهل التوازي مع asyncio
- ●ممتاز لواجهات API والصفحات الثابتة
القيود
- ●لا يمكنه تنفيذ JavaScript
- ●يفشل في تطبيقات الصفحة الواحدة والمحتوى الديناميكي
- ●قد يواجه صعوبة مع أنظمة مكافحة البوتات المعقدة
كيفية استخراج بيانات Thrillophilia بالكود
Python + Requests
import requests
from bs4 import BeautifulSoup
# Thrillophilia uses Cloudflare, so standard requests might fail without proper headers or session management
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
url = 'https://www.thrillophilia.com/destinations/bali/tours'
def scrape_thrill(url):
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Selectors vary based on specific destination pages
tours = soup.select('.tour-card')
for tour in tours:
title = tour.find('h3').text.strip()
price = tour.select_one('.price-value').text.strip() if tour.select_one('.price-value') else 'N/A'
print(f'Tour: {title} | Price: {price}')
except Exception as e:
print(f'Error occurred: {e}')
scrape_thrill(url)Python + Playwright
from playwright.sync_api import sync_playwright
def run():
with sync_playwright() as p:
# Launching with a real browser profile helps bypass basic detections
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto('https://www.thrillophilia.com/destinations/egypt/tours', wait_until='networkidle')
# Wait for tour cards to load dynamically
page.wait_for_selector('.tour-card')
tours = page.query_selector_all('.tour-card')
for tour in tours:
title = tour.query_selector('h3').inner_text()
print(f'Extracted: {title}')
browser.close()
run()Python + Scrapy
import scrapy
class ThrillSpider(scrapy.Spider):
name = 'thrillophilia'
start_urls = ['https://www.thrillophilia.com/destinations/japan/tours']
def parse(self, response):
for tour in response.css('.tour-card'):
yield {
'title': tour.css('h3::text').get(),
'price': tour.css('.current-price::text').get(),
'rating': tour.css('.rating-value::text').get()
}
# Handling pagination
next_page = response.css('a.next-page::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.thrillophilia.com/destinations/maldives');
// Execute script in browser context to extract data
const tours = await page.evaluate(() => {
const items = document.querySelectorAll('.tour-card');
return Array.from(items).map(item => ({
title: item.querySelector('h3')?.innerText,
price: item.querySelector('.price')?.innerText
}));
});
console.log(tours);
await browser.close();
})();ماذا يمكنك فعله ببيانات Thrillophilia
استكشف التطبيقات العملية والرؤى من بيانات Thrillophilia.
مراقبة الأسعار الديناميكية
مراقبة أسعار الأنشطة يومياً لضبط استراتيجيات التسعير التنافسية.
كيفية التنفيذ:
- 1سحب أسعار الجولات يومياً للوجهات الرائدة
- 2تخزين البيانات التاريخية في قاعدة بيانات SQL
- 3إعداد تنبيهات لانخفاض الأسعار بنسبة تزيد عن 15%
- 4المزامنة مع CRM الداخلي لتحديث تسعيرك الخاص
استخدم Automatio لاستخراج البيانات من Thrillophilia وبناء هذه التطبيقات بدون كتابة كود.
ماذا يمكنك فعله ببيانات Thrillophilia
- مراقبة الأسعار الديناميكية
مراقبة أسعار الأنشطة يومياً لضبط استراتيجيات التسعير التنافسية.
- سحب أسعار الجولات يومياً للوجهات الرائدة
- تخزين البيانات التاريخية في قاعدة بيانات SQL
- إعداد تنبيهات لانخفاض الأسعار بنسبة تزيد عن 15%
- المزامنة مع CRM الداخلي لتحديث تسعيرك الخاص
- تحليل المشاعر في المراجعات
تحليل آلاف المراجعات لفهم نقاط الألم لدى المسافرين.
- استخراج جميع نصوص المراجعات والتقييمات
- تطبيق نماذج NLP لتصنيف المشاعر
- تحديد كلمات رئيسية محددة تتعلق بـ 'الأمان' أو 'التأخير'
- إنشاء تقارير لتحسين الخدمة
- اكتشاف اتجاهات مسار الرحلة
استخدام بيانات مسار الرحلة لتصميم باقات جولات جديدة تتبع اتجاهات السوق.
- سحب تفاصيل الرحلات ليلة بليلة للجولات الأكثر مبيعاً
- تحديد أنماط الفنادق والأنشطة الشائعة
- مقارنة شعبية الوجهات عبر المناطق المختلفة
- صياغة منتجات جديدة بناءً على هياكل مسارات الرحلة عالية الأداء
- توليد العملاء لمعدات السفر
تحديد الأنشطة الشائعة لاستهداف مبيعات المعدات لفئات ديموغرافية محددة.
- تتبع أنواع المغامرات الأكثر حجزاً (مثل التنزه مقابل الفخامة)
- ربط شعبية الأنشطة بالاتجاهات الموسمية
- توجيه حملات تسويق المعدات بناءً على تاغات نشاط الوجهة
- التحقق من منظمي الرحلات
مراقبة المشغلين الذين يحصلون باستمرار على تقييمات عالية عبر المنصة.
- استخراج أسماء المشغلين ومتوسط تقييماتهم
- تتبع حجم الجولات التي يتعامل معها كل مشغل
- فحص الشركاء المحتملين لشبكة وكالة السفر الخاصة بك
عزز سير عملك مع أتمتة الذكاء الاصطناعي
يجمع Automatio بين قوة وكلاء الذكاء الاصطناعي وأتمتة الويب والتكاملات الذكية لمساعدتك على إنجاز المزيد في وقت أقل.
نصائح احترافية لتجريد Thrillophilia
نصائح الخبراء لاستخراج البيانات بنجاح من Thrillophilia.
استخدم بروكسيات سكنية (residential proxies) عالية الجودة لتجاوز حماية Cloudflare بشكل أكثر فعالية
قم بتنفيذ فترات انتظار (sleep) عشوائية بين 5 إلى 15 ثانية لمحاكاة سلوك التصفح البشري
قم بتدوير سلسلة User-Agent بشكل متكرر لمنع تحديد بصمة الجهاز (fingerprinting)
افحص وسم السكريبت __NEXT_DATA__ الذي يحتوي غالباً على بيانات JSON مهيكلة للصفحة
جدول عمليات سحب البيانات (scraping) خلال ساعات خارج الذروة لتجنب تقييد المعدل (rate limiting) الشديد
قم بتنظيف بيانات مسار الرحلة عن طريق إزالة وسوم HTML وتنسيق المسافات البيضاء
الشهادات
ماذا يقول مستخدمونا
انضم إلى الآلاف من المستخدمين الراضين الذين حولوا سير عملهم
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
ذو صلة Web Scraping
الأسئلة الشائعة حول Thrillophilia
ابحث عن إجابات للأسئلة الشائعة حول Thrillophilia