Jak scrapovat zájezdy a recenze z Thrillophilia
Naučte se, jak scrapovat Thrillophilia pro extrakci cen zájezdů, itinerářů a zákaznických recenzí. Kvalitní cestovní data pro analýzu trhu a monitoring.
Detekována anti-bot ochrana
- Cloudflare
- Podnikový WAF a správa botů. Používá JavaScript výzvy, CAPTCHA a analýzu chování. Vyžaduje automatizaci prohlížeče se stealth nastavením.
- Omezení rychlosti
- Omezuje požadavky na IP/relaci v čase. Lze obejít rotujícími proxy, zpožděním požadavků a distribuovaným scrapingem.
- Blokování IP
- Blokuje známé IP datových center a označené adresy. Vyžaduje rezidenční nebo mobilní proxy pro efektivní obejití.
- Otisk prohlížeče
- Identifikuje boty pomocí vlastností prohlížeče: canvas, WebGL, písma, pluginy. Vyžaduje spoofing nebo skutečné profily prohlížeče.
O Thrillophilia
Objevte, co Thrillophilia nabízí a jaká cenná data lze extrahovat.
Přední destinace pro cestovatelské zážitky
Thrillophilia je prominentní cestovní a dobrodružná platforma se sídlem v Indii, která poskytuje odborníky vedené, komplexní balíčky zájezdů po celém světě. Specializuje se na kurátorské cestovatelské zážitky od himálajských expedic a kulturních prohlídek Rádžasthánu až po mezinárodní pobyty v Evropě, jihovýchodní Asii a na Blízkém východě.
Bohatost a hodnota dat
Platforma obsahuje podrobné výpisy vícedenních zájezdů, svatebních balíčků a skupinových dobrodružství. Výpisy na Thrillophilia obsahují množství strukturovaných dat, včetně konkrétních itinerářů, detailů o ubytování noc po noci, zvýhodněných cen, uživatelských hodnocení a popisných recenzí. Tyto informace jsou vysoce hodnotné pro cestovní kanceláře a výzkumníky trhu.
Proč je to důležité pro analýzu dat
Pro firmy v sektoru cestovního ruchu poskytuje scrapování Thrillophilia konkurenční výhodu. Sledováním kolísání cen a sentimentu zákazníků prostřednictvím recenzí mohou společnosti optimalizovat své vlastní nabídky a identifikovat vznikající cestovní trendy dříve, než se stanou hlavním proudem.
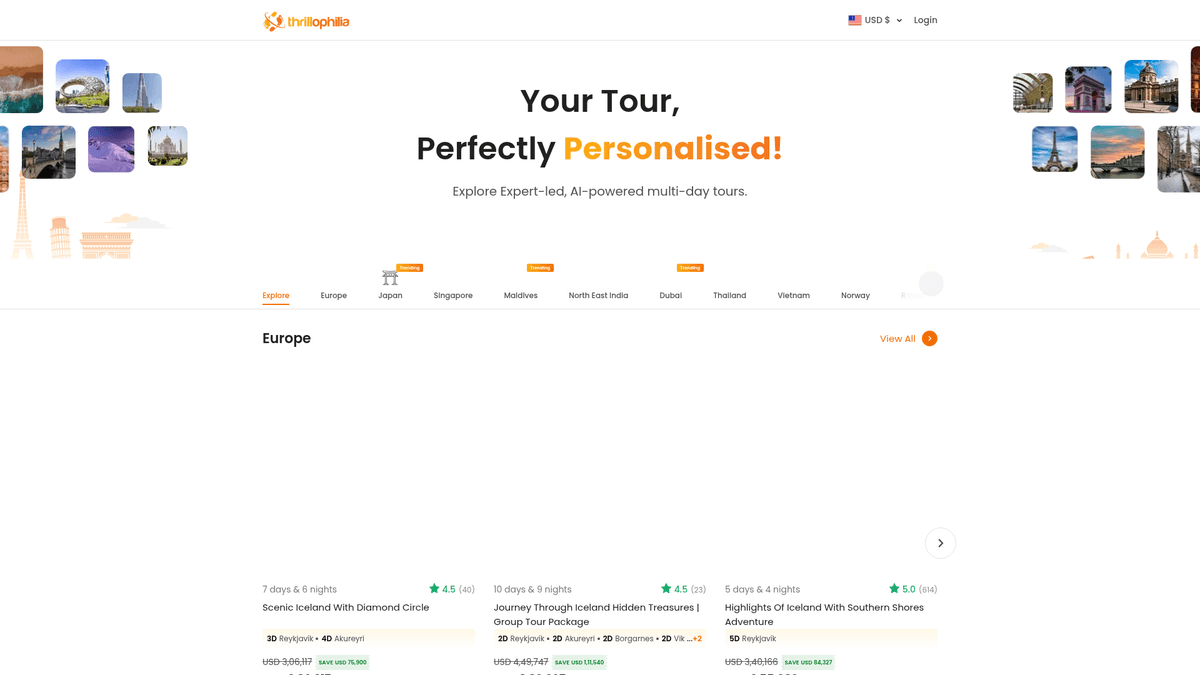
Proč Scrapovat Thrillophilia?
Objevte obchodní hodnotu a případy použití pro extrakci dat z Thrillophilia.
Monitorujte ceny konkurence pro podobné balíčky zájezdů v reálném čase
Analyzujte sentiment zákazníků a kvalitu služeb prostřednictvím detailních uživatelských recenzí
Agregujte komplexní itineráře pro analýzu globálních tržních trendů
Identifikujte oblíbené a vznikající cestovní destinace pro strategické plánování
Sledujte metriky spolehlivosti a výkonu místních operátorů zájezdů
Plňte AI modely strukturovanými daty z itinerářů pro automatizované plánování cest
Výzvy Scrapování
Technické výzvy, se kterými se můžete setkat při scrapování Thrillophilia.
Agresivní mechanismy ochrany proti botům od Cloudflare
Dynamické načítání obsahu přes Next.js a React framework
Komplexní zanořené HTML struktury pro vícedenní itineráře
Přísné zásady rate limiting pro vysokofrekvenční požadavky
Browser fingerprinting, který detekuje automatizované headless browsery
Scrapujte Thrillophilia pomocí AI
Žádný kód není potřeba. Extrahujte data během minut s automatizací poháněnou AI.
Jak to funguje
Popište, co potřebujete
Řekněte AI, jaká data chcete extrahovat z Thrillophilia. Stačí to napsat přirozeným jazykem — žádný kód ani selektory.
AI extrahuje data
Naše umělá inteligence prochází Thrillophilia, zpracovává dynamický obsah a extrahuje přesně to, co jste požadovali.
Získejte svá data
Získejte čistá, strukturovaná data připravená k exportu jako CSV, JSON nebo k odeslání přímo do vašich aplikací.
Proč používat AI pro scrapování
AI usnadňuje scrapování Thrillophilia bez psaní kódu. Naše platforma poháněná umělou inteligencí rozumí, jaká data chcete — stačí je popsat přirozeným jazykem a AI je automaticky extrahuje.
How to scrape with AI:
- Popište, co potřebujete: Řekněte AI, jaká data chcete extrahovat z Thrillophilia. Stačí to napsat přirozeným jazykem — žádný kód ani selektory.
- AI extrahuje data: Naše umělá inteligence prochází Thrillophilia, zpracovává dynamický obsah a extrahuje přesně to, co jste požadovali.
- Získejte svá data: Získejte čistá, strukturovaná data připravená k exportu jako CSV, JSON nebo k odeslání přímo do vašich aplikací.
Why use AI for scraping:
- Automaticky obchází sofistikovaná anti-bot opatření jako Cloudflare
- No-code rozhraní umožňuje vytvářet cestovní scrapery bez vývojářských zdrojů
- Bez námahy zvládá vykreslování JavaScriptu a dynamický obsah
- Plánované spouštění scrapingu umožňuje automatizované denní monitorování cen
- Přímá integrace s Google Sheets pro okamžitou vizualizaci dat
No-code webové scrapery pro Thrillophilia
Alternativy point-and-click k AI scrapingu
Několik no-code nástrojů jako Browse.ai, Octoparse, Axiom a ParseHub vám může pomoci scrapovat Thrillophilia bez psaní kódu. Tyto nástroje obvykle používají vizuální rozhraní pro výběr dat, i když mohou mít problémy se složitým dynamickým obsahem nebo anti-bot opatřeními.
Typický workflow s no-code nástroji
Běžné výzvy
Křivka učení
Pochopení selektorů a logiky extrakce vyžaduje čas
Selektory se rozbijí
Změny webu mohou rozbít celý pracovní postup
Problémy s dynamickým obsahem
Weby s hodně JavaScriptem vyžadují složitá řešení
Omezení CAPTCHA
Většina nástrojů vyžaduje ruční zásah u CAPTCHA
Blokování IP
Agresivní scrapování může vést k zablokování vaší IP
No-code webové scrapery pro Thrillophilia
Několik no-code nástrojů jako Browse.ai, Octoparse, Axiom a ParseHub vám může pomoci scrapovat Thrillophilia bez psaní kódu. Tyto nástroje obvykle používají vizuální rozhraní pro výběr dat, i když mohou mít problémy se složitým dynamickým obsahem nebo anti-bot opatřeními.
Typický workflow s no-code nástroji
- Nainstalujte rozšíření prohlížeče nebo se zaregistrujte na platformě
- Přejděte na cílový web a otevřete nástroj
- Vyberte datové prvky k extrakci kliknutím
- Nakonfigurujte CSS selektory pro každé datové pole
- Nastavte pravidla stránkování pro scrapování více stránek
- Vyřešte CAPTCHA (často vyžaduje ruční řešení)
- Nakonfigurujte plánování automatických spuštění
- Exportujte data do CSV, JSON nebo připojte přes API
Běžné výzvy
- Křivka učení: Pochopení selektorů a logiky extrakce vyžaduje čas
- Selektory se rozbijí: Změny webu mohou rozbít celý pracovní postup
- Problémy s dynamickým obsahem: Weby s hodně JavaScriptem vyžadují složitá řešení
- Omezení CAPTCHA: Většina nástrojů vyžaduje ruční zásah u CAPTCHA
- Blokování IP: Agresivní scrapování může vést k zablokování vaší IP
Příklady kódu
import requests
from bs4 import BeautifulSoup
# Thrillophilia uses Cloudflare, so standard requests might fail without proper headers or session management
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
url = 'https://www.thrillophilia.com/destinations/bali/tours'
def scrape_thrill(url):
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Selectors vary based on specific destination pages
tours = soup.select('.tour-card')
for tour in tours:
title = tour.find('h3').text.strip()
price = tour.select_one('.price-value').text.strip() if tour.select_one('.price-value') else 'N/A'
print(f'Tour: {title} | Price: {price}')
except Exception as e:
print(f'Error occurred: {e}')
scrape_thrill(url)Kdy použít
Nejlepší pro statické HTML stránky s minimem JavaScriptu. Ideální pro blogy, zpravodajské weby a jednoduché e-commerce produktové stránky.
Výhody
- ●Nejrychlejší provedení (bez režie prohlížeče)
- ●Nejnižší spotřeba zdrojů
- ●Snadná paralelizace s asyncio
- ●Skvělé pro API a statické stránky
Omezení
- ●Nemůže spustit JavaScript
- ●Selhává na SPA a dynamickém obsahu
- ●Může mít problémy se složitými anti-bot systémy
Jak scrapovat Thrillophilia pomocí kódu
Python + Requests
import requests
from bs4 import BeautifulSoup
# Thrillophilia uses Cloudflare, so standard requests might fail without proper headers or session management
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
url = 'https://www.thrillophilia.com/destinations/bali/tours'
def scrape_thrill(url):
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Selectors vary based on specific destination pages
tours = soup.select('.tour-card')
for tour in tours:
title = tour.find('h3').text.strip()
price = tour.select_one('.price-value').text.strip() if tour.select_one('.price-value') else 'N/A'
print(f'Tour: {title} | Price: {price}')
except Exception as e:
print(f'Error occurred: {e}')
scrape_thrill(url)Python + Playwright
from playwright.sync_api import sync_playwright
def run():
with sync_playwright() as p:
# Launching with a real browser profile helps bypass basic detections
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto('https://www.thrillophilia.com/destinations/egypt/tours', wait_until='networkidle')
# Wait for tour cards to load dynamically
page.wait_for_selector('.tour-card')
tours = page.query_selector_all('.tour-card')
for tour in tours:
title = tour.query_selector('h3').inner_text()
print(f'Extracted: {title}')
browser.close()
run()Python + Scrapy
import scrapy
class ThrillSpider(scrapy.Spider):
name = 'thrillophilia'
start_urls = ['https://www.thrillophilia.com/destinations/japan/tours']
def parse(self, response):
for tour in response.css('.tour-card'):
yield {
'title': tour.css('h3::text').get(),
'price': tour.css('.current-price::text').get(),
'rating': tour.css('.rating-value::text').get()
}
# Handling pagination
next_page = response.css('a.next-page::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.thrillophilia.com/destinations/maldives');
// Execute script in browser context to extract data
const tours = await page.evaluate(() => {
const items = document.querySelectorAll('.tour-card');
return Array.from(items).map(item => ({
title: item.querySelector('h3')?.innerText,
price: item.querySelector('.price')?.innerText
}));
});
console.log(tours);
await browser.close();
})();Co Můžete Dělat S Daty Thrillophilia
Prozkoumejte praktické aplikace a poznatky z dat Thrillophilia.
Dynamické monitorování cen
Denně sledujte ceny aktivit a upravujte své konkurenční cenové strategie.
Jak implementovat:
- 1Denně scrapujte ceny zájezdů pro top destinace
- 2Ukládejte historická data do SQL databáze
- 3Nastavte upozornění na pokles cen o více než 15 %
- 4Synchronizujte s interním CRM pro aktualizaci vlastních cen
Použijte Automatio k extrakci dat z Thrillophilia a vytvoření těchto aplikací bez psaní kódu.
Co Můžete Dělat S Daty Thrillophilia
- Dynamické monitorování cen
Denně sledujte ceny aktivit a upravujte své konkurenční cenové strategie.
- Denně scrapujte ceny zájezdů pro top destinace
- Ukládejte historická data do SQL databáze
- Nastavte upozornění na pokles cen o více než 15 %
- Synchronizujte s interním CRM pro aktualizaci vlastních cen
- Analýza sentimentu recenzí
Analyzujte tisíce recenzí, abyste pochopili slabá místa cestovatelů.
- Extrahujte všechny texty recenzí a hodnocení
- Aplikujte NLP modely pro kategorizaci sentimentu
- Identifikujte specifická klíčová slova související s 'bezpečností' nebo 'zpožděním'
- Generujte reporty pro zlepšení služeb
- Objevování trendů v itinerářích
Využívejte data z itinerářů k navrhování nových balíčků zájezdů, které sledují tržní trendy.
- Scrapujte rozpis noc po noci u nejprodávanějších zájezdů
- Identifikujte běžné vzorce hotelů a aktivit
- Porovnejte popularitu destinací v různých regionech
- Navrhujte nové produkty na základě úspěšných struktur itinerářů
- Lead Gen pro cestovní vybavení
Identifikujte populární aktivity pro cílení prodeje vybavení na konkrétní demografické skupiny.
- Sledujte nejčastěji rezervované typy dobrodružství (např. trekking vs. luxus)
- Korelujte popularitu aktivit se sezónními trendy
- Cilte marketingové kampaně na vybavení podle tagů aktivit v destinaci
- Ověřování operátorů zájezdů
Sledujte, kteří operátoři jsou na platformě konzistentně vysoce hodnoceni.
- Extrahujte názvy operátorů a jejich průměrné skóre hodnocení
- Sledujte objem zájezdů zajišťovaných jednotlivými operátory
- Prověřujte potenciální partnery pro vaši vlastní síť cestovních kanceláří
Zrychlete svuj workflow s AI automatizaci
Automatio kombinuje silu AI agentu, webove automatizace a chytrych integraci, aby vam pomohl dosahnout vice za kratsi cas.
Profesionální Tipy Pro Scrapování Thrillophilia
Odborné rady pro úspěšnou extrakci dat z Thrillophilia.
Používejte kvalitní rezidenční proxy, abyste efektivněji obešli ochranu Cloudflare
Implementujte náhodné intervaly sleep mezi 5 až 15 sekundami pro napodobení lidského prohlížení
Často rotujte svůj User-Agent string, abyste zabránili detekci na základě fingerprinting zařízení
Zkontrolujte script tag __NEXT_DATA__, který často obsahuje strukturovaný JSON dané stránky
Plánujte scraping na hodiny mimo špičku, abyste se vyhnuli přísnému rate limiting
Vyčistěte data itineráře odstraněním HTML tagů a normalizací bílých znaků
Reference
Co rikaji nasi uzivatele
Pridejte se k tisicum spokojenych uzivatelu, kteri transformovali svuj workflow
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Souvisejici Web Scraping
Casto kladene dotazy o Thrillophilia
Najdete odpovedi na bezne otazky o Thrillophilia