Cómo extraer datos de GOV.UK | Guía de Web Scraping del Gobierno del Reino Unido
Guía completa para el scraping de GOV.UK: obtén orientación gubernamental, actualizaciones de políticas y estadísticas oficiales. Aprende a extraer datos de...
Protección Anti-Bot Detectada
- Limitación de velocidad
- Limita solicitudes por IP/sesión en el tiempo. Se puede eludir con proxies rotativos, retrasos en solicitudes y scraping distribuido.
- User-Agent Filtering
- Bloqueo de IP
- Bloquea IPs de centros de datos conocidos y direcciones marcadas. Requiere proxies residenciales o móviles para eludir efectivamente.
Acerca de GOV.UK
Descubre qué ofrece GOV.UK y qué datos valiosos se pueden extraer.
GOV.UK es el portal digital central del gobierno del Reino Unido, que proporciona un único punto de acceso a los servicios e información de todos los departamentos y agencias. Creado por el Government Digital Service (GDS), reemplazó a cientos de sitios de agencias individuales con una interfaz unificada y fácil de usar diseñada para la transparencia y la eficiencia.
La plataforma contiene un repositorio masivo de datos, que incluye orientación legislativa, estadísticas oficiales, libros blancos de políticas y avisos de contratación. Debido a que el gobierno del Reino Unido sigue una política de 'datos abiertos por defecto', la mayor parte de la información en GOV.UK se publica bajo la Open Government Licence, lo que la convierte en una mina de oro para investigadores, bufetes de abogados y empresas.
Extraer datos de GOV.UK es muy valioso para monitorear cambios regulatorios, rastrear indicadores económicos y recopilar inteligencia competitiva a partir de anuncios de licitaciones públicas. Las organizaciones utilizan estos datos para automatizar flujos de trabajo de cumplimiento y mantenerse a la vanguardia de los desarrollos políticos que afectan a sus industrias.
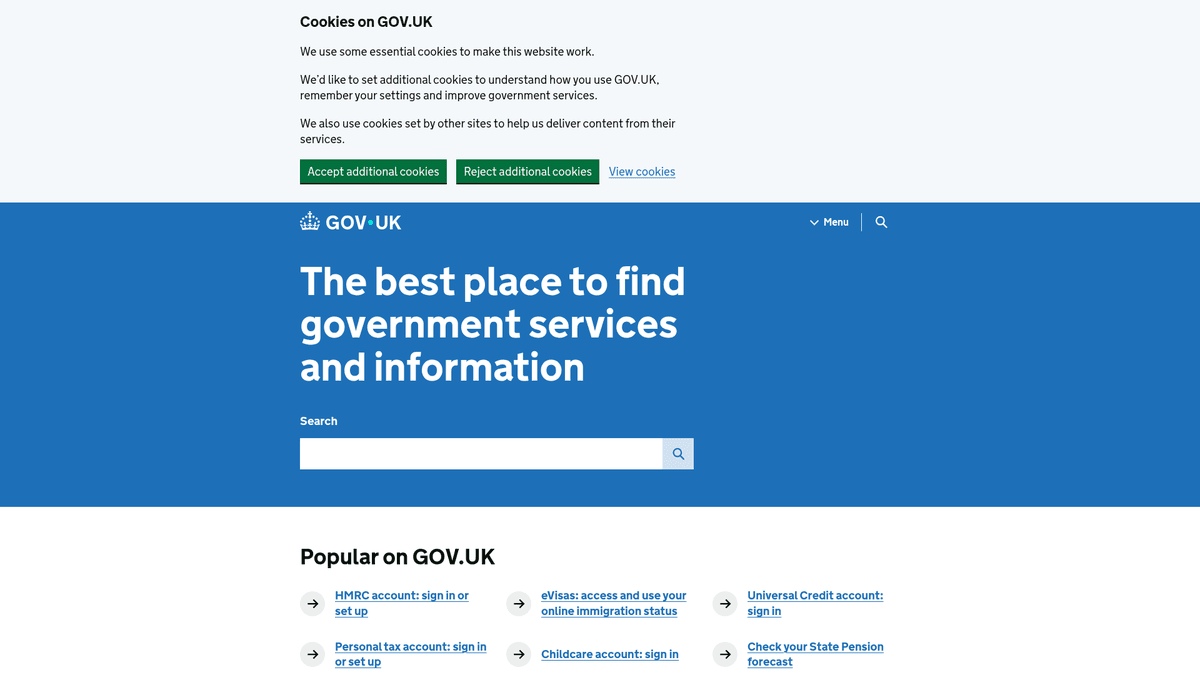
¿Por Qué Scrapear GOV.UK?
Descubre el valor comercial y los casos de uso para extraer datos de GOV.UK.
Análisis del mercado de contratación pública
Analiza más de 600,000 contratos gubernamentales para identificar tendencias de gasto, demandas de servicios de nicho y ciclos de financiación en ayuntamientos y organismos nacionales.
Debida diligencia corporativa
Extrae datos de Companies House para verificar el estado de las empresas, el historial de directores y las personas con control significativo para la evaluación de riesgos y el cumplimiento de normativas de blanqueo de capitales (AML).
Generación de leads para B2G
Identifica empresas que han ganado licitaciones gubernamentales recientemente para ofrecer servicios de subcontratación o soluciones competitivas.
Investigación económica y social
Accede a registros públicos sobre prestaciones, estadísticas de criminalidad y tendencias de empleo para construir modelos económicos integrales o informes de impacto social.
Datos históricos de vehículos
Extrae el historial de MOT y kilometraje para crear herramientas de valoración automotriz o verificar el estado de vehículos en mercados secundarios.
Desafíos de Scraping
Desafíos técnicos que puedes encontrar al scrapear GOV.UK.
Fragmentación de datos
La información está dispersa en varios subservicios como Companies House y Find a Tender, cada uno con diferentes estructuras de URL y esquemas de HTML.
Rate Limiting y Anti-Bot
Gov.uk utiliza Cloudflare y un rate limiting agresivo en ciertos endpoints de búsqueda, lo que puede provocar bloqueos temporales de IP si la velocidad de scraping es demasiado alta.
Actualizaciones estructurales frecuentes
El sitio es actualizado continuamente por varios departamentos, lo que significa que los selectores para valores de contratos o detalles de empresas pueden dejar de funcionar y requieren mantenimiento regular.
Volumen de datos
Con cientos de miles de listados activos y millones de registros históricos, gestionar la profundidad del rastreo y el almacenamiento de datos requiere una infraestructura robusta.
Scrapea GOV.UK con IA
Sin código necesario. Extrae datos en minutos con automatización impulsada por IA.
Cómo Funciona
Describe lo que necesitas
Dile a la IA qué datos quieres extraer de GOV.UK. Solo escríbelo en lenguaje natural — sin código ni selectores.
La IA extrae los datos
Nuestra inteligencia artificial navega GOV.UK, maneja contenido dinámico y extrae exactamente lo que pediste.
Obtén tus datos
Recibe datos limpios y estructurados listos para exportar como CSV, JSON o enviar directamente a tus aplicaciones.
Por Qué Usar IA para el Scraping
La IA facilita el scraping de GOV.UK sin escribir código. Nuestra plataforma impulsada por inteligencia artificial entiende qué datos quieres — solo descríbelo en lenguaje natural y la IA los extrae automáticamente.
How to scrape with AI:
- Describe lo que necesitas: Dile a la IA qué datos quieres extraer de GOV.UK. Solo escríbelo en lenguaje natural — sin código ni selectores.
- La IA extrae los datos: Nuestra inteligencia artificial navega GOV.UK, maneja contenido dinámico y extrae exactamente lo que pediste.
- Obtén tus datos: Recibe datos limpios y estructurados listos para exportar como CSV, JSON o enviar directamente a tus aplicaciones.
Why use AI for scraping:
- Gestión de contenido dinámico: Automatio navega fácilmente por filtros de búsqueda complejos y tablas interactivas con mucho JavaScript sin necesidad de escribir código.
- Paginación automática: Gestiona sin problemas los botones de 'Siguiente' y la paginación numerada a través de miles de páginas de resultados de búsqueda para avisos de contratos.
- Evasión de protecciones: Las funciones integradas ayudan a gestionar los encabezados de las peticiones y los fingerprints para navegar de forma más efectiva por sitios protegidos por Cloudflare.
- Monitoreo programado: Configura scrapers para que se ejecuten diariamente y capturen nuevos avisos de licitación o actualizaciones de registros de empresas en el momento en que se publiquen.
- Exportación de datos estructurados: Transforma HTML desordenado en formatos limpios como JSON o CSV, dejándolos listos para su integración inmediata en herramientas de CRM o BI.
Scrapers Sin Código para GOV.UK
Alternativas de apuntar y clic al scraping con IA
Varias herramientas sin código como Browse.ai, Octoparse, Axiom y ParseHub pueden ayudarte a scrapear GOV.UK. Estas herramientas usan interfaces visuales para seleccionar elementos, pero tienen desventajas comparadas con soluciones con IA.
Flujo de Trabajo Típico con Herramientas Sin Código
Desafíos Comunes
Curva de aprendizaje
Comprender selectores y lógica de extracción lleva tiempo
Los selectores se rompen
Los cambios en el sitio web pueden romper todo el flujo de trabajo
Problemas con contenido dinámico
Los sitios con mucho JavaScript requieren soluciones complejas
Limitaciones de CAPTCHA
La mayoría de herramientas requieren intervención manual para CAPTCHAs
Bloqueo de IP
El scraping agresivo puede resultar en el bloqueo de tu IP
Scrapers Sin Código para GOV.UK
Varias herramientas sin código como Browse.ai, Octoparse, Axiom y ParseHub pueden ayudarte a scrapear GOV.UK. Estas herramientas usan interfaces visuales para seleccionar elementos, pero tienen desventajas comparadas con soluciones con IA.
Flujo de Trabajo Típico con Herramientas Sin Código
- Instalar extensión del navegador o registrarse en la plataforma
- Navegar al sitio web objetivo y abrir la herramienta
- Seleccionar con point-and-click los elementos de datos a extraer
- Configurar selectores CSS para cada campo de datos
- Configurar reglas de paginación para scrapear múltiples páginas
- Resolver CAPTCHAs (frecuentemente requiere intervención manual)
- Configurar programación para ejecuciones automáticas
- Exportar datos a CSV, JSON o conectar vía API
Desafíos Comunes
- Curva de aprendizaje: Comprender selectores y lógica de extracción lleva tiempo
- Los selectores se rompen: Los cambios en el sitio web pueden romper todo el flujo de trabajo
- Problemas con contenido dinámico: Los sitios con mucho JavaScript requieren soluciones complejas
- Limitaciones de CAPTCHA: La mayoría de herramientas requieren intervención manual para CAPTCHAs
- Bloqueo de IP: El scraping agresivo puede resultar en el bloqueo de tu IP
Ejemplos de Código
import requests
from bs4 import BeautifulSoup
# CONSEJO PROFESIONAL: Añade .json a muchas URL de GOV.UK para obtener datos puros
url = 'https://www.gov.uk/search/news-and-communications'
headers = {'User-Agent': 'ResearchBot/1.0 (contact@example.com)'}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
for item in soup.select('.gem-c-document-list__item'):
title = item.select_one('.gem-c-document-list__item-title').text.strip()
link = item.select_one('a')['href']
print(f'Actualización: {title} | https://www.gov.uk{link}')
except Exception as e:
print(f'Error: {e}')Cuándo Usar
Mejor para páginas HTML estáticas donde el contenido se carga del lado del servidor. El enfoque más rápido y simple cuando no se requiere renderizado de JavaScript.
Ventajas
- ●Ejecución más rápida (sin sobrecarga del navegador)
- ●Menor consumo de recursos
- ●Fácil de paralelizar con asyncio
- ●Excelente para APIs y páginas estáticas
Limitaciones
- ●No puede ejecutar JavaScript
- ●Falla en SPAs y contenido dinámico
- ●Puede tener dificultades con sistemas anti-bot complejos
Cómo Scrapear GOV.UK con Código
Python + Requests
import requests
from bs4 import BeautifulSoup
# CONSEJO PROFESIONAL: Añade .json a muchas URL de GOV.UK para obtener datos puros
url = 'https://www.gov.uk/search/news-and-communications'
headers = {'User-Agent': 'ResearchBot/1.0 (contact@example.com)'}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
for item in soup.select('.gem-c-document-list__item'):
title = item.select_one('.gem-c-document-list__item-title').text.strip()
link = item.select_one('a')['href']
print(f'Actualización: {title} | https://www.gov.uk{link}')
except Exception as e:
print(f'Error: {e}')Python + Playwright
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
try:
page.goto('https://www.gov.uk/search/all?keywords=data+protection')
page.wait_for_selector('.gem-c-document-list__item')
titles = page.locator('.gem-c-document-list__item-title').all_text_contents()
for t in titles:
print(f'Extraído: {t.strip()}')
finally:
browser.close()Python + Scrapy
import scrapy
class GovSpider(scrapy.Spider):
name = 'gov_spider'
start_urls = ['https://www.gov.uk/search/news-and-communications']
def parse(self, response):
for article in response.css('.gem-c-document-list__item'):
yield {
'title': article.css('.gem-c-document-list__item-title::text').get().strip(),
'link': response.urljoin(article.css('a::attr(href)').get())
}
next_page = response.css('a[rel="next"]::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
try {
await page.goto('https://www.gov.uk/search/news-and-communications', { waitUntil: 'networkidle2' });
const results = await page.evaluate(() =>
Array.from(document.querySelectorAll('.gem-c-document-list__item-title'))
.map(el => el.innerText.trim())
);
console.log(results);
} finally {
await browser.close();
}
})();Qué Puedes Hacer Con Los Datos de GOV.UK
Explora aplicaciones prácticas e insights de los datos de GOV.UK.
Sistema de Alertas Regulatorias
Los equipos legales y de cumplimiento pueden monitorear categorías de orientación específicas para detectar cambios en las leyes de inmediato.
Cómo implementar:
- 1Extraer diariamente la sección de 'Guidance and Regulation'.
- 2Extraer el texto del documento y las marcas de tiempo de última actualización.
- 3Comparar el contenido con versiones anteriores para resaltar las diferencias.
- 4Enviar alertas automatizadas a las partes interesadas internas relevantes.
Usa Automatio para extraer datos de GOV.UK y crear estas aplicaciones sin escribir código.
Qué Puedes Hacer Con Los Datos de GOV.UK
- Sistema de Alertas Regulatorias
Los equipos legales y de cumplimiento pueden monitorear categorías de orientación específicas para detectar cambios en las leyes de inmediato.
- Extraer diariamente la sección de 'Guidance and Regulation'.
- Extraer el texto del documento y las marcas de tiempo de última actualización.
- Comparar el contenido con versiones anteriores para resaltar las diferencias.
- Enviar alertas automatizadas a las partes interesadas internas relevantes.
- Rastreador de Oportunidades de Licitación
Los equipos de ventas pueden extraer avisos de contratación para encontrar nuevas oportunidades de contratos gubernamentales.
- Dirigirse a la categoría de búsqueda 'Procurement' en GOV.UK.
- Extraer fechas límite, correos electrónicos de contacto y valores de contrato.
- Filtrar resultados por palabras clave de la industria relevantes para su negocio.
- Importar prospectos directamente en un CRM para su seguimiento.
- Análisis de Tendencias Económicas
Los economistas pueden agregar publicaciones estadísticas para estudios longitudinales sobre el desempeño del Reino Unido.
- Identificar las URL de las series de datos estadísticos.
- Extraer enlaces directos a archivos CSV o Excel.
- Descargar y limpiar los conjuntos de datos mediante scripts automatizados.
- Fusionar los datos en una base de datos centralizada para su visualización.
- Archivo de Políticas Públicas
Periodistas e investigadores pueden crear un archivo consultable de anuncios oficiales del gobierno.
- Extraer la sección 'News and Communications' de forma continua.
- Extraer titulares, cuerpo del texto y etiquetas de departamento.
- Indexar los datos en una plataforma de búsqueda como Elasticsearch.
- Analizar el sentimiento y la frecuencia de palabras clave de políticas específicas.
- Bots de Asesoramiento Automatizado
Las organizaciones sin fines de lucro pueden usar la orientación oficial para alimentar chatbots que ayuden a los ciudadanos a encontrar información sobre beneficios.
- Extraer páginas de orientación sobre beneficios y vivienda.
- Mapear el texto extraído a una base de datos de vector para RAG (Retrieval-Augmented Generation).
- Configurar un disparador para actualizar la base de datos cuando cambie el contenido de GOV.UK.
- Proporcionar respuestas precisas y en tiempo real a las consultas de los usuarios.
- Motor de Descubrimiento de Subvenciones
Las instituciones educativas pueden encontrar oportunidades de subvenciones y financiación para proyectos de investigación.
- Extraer la categoría de financiación 'Education, Training and Skills'.
- Extraer criterios de elegibilidad y plazos de solicitud.
- Categorizar las subvenciones por departamento y monto de financiación.
- Automatizar resúmenes semanales por correo electrónico para los miembros de la facultad.
Potencia tu flujo de trabajo con Automatizacion IA
Automatio combina el poder de agentes de IA, automatizacion web e integraciones inteligentes para ayudarte a lograr mas en menos tiempo.
Consejos Pro para Scrapear GOV.UK
Consejos expertos para extraer datos exitosamente de GOV.UK.
El truco de la extensión .json
Muchas páginas de Gov.uk permiten añadir .json al final de la URL para recibir datos estructurados directamente, lo cual es más rápido y fiable que el scraping de HTML.
Limita la velocidad de tus peticiones
Evita velocidades de scraping agresivas; implementa un retraso de 2 a 5 segundos entre peticiones para evitar activar el rate limits y los bloqueos de IP.
Prioriza el uso de APIs oficiales
Aprovecha las APIs específicas de Companies House o Find a Tender, ya que están diseñadas explícitamente para desarrolladores y ofrecen una estabilidad mucho mayor.
Gestiona errores 429 de forma adecuada
Si recibes un error 'Too Many Requests', pausa tu scraper durante varios minutos y verifica tu frecuencia de rastreo antes de reanudar la actividad.
Rota tus User-Agents
Utiliza siempre encabezados User-Agent de navegadores modernos y válidos para evitar ser identificado inmediatamente como un script básico por las capas de seguridad.
Testimonios
Lo Que Dicen Nuestros Usuarios
Unete a miles de usuarios satisfechos que han transformado su flujo de trabajo
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Relacionados Web Scraping
Preguntas Frecuentes Sobre GOV.UK
Encuentra respuestas a preguntas comunes sobre GOV.UK