
Gemini 3.1 Pro
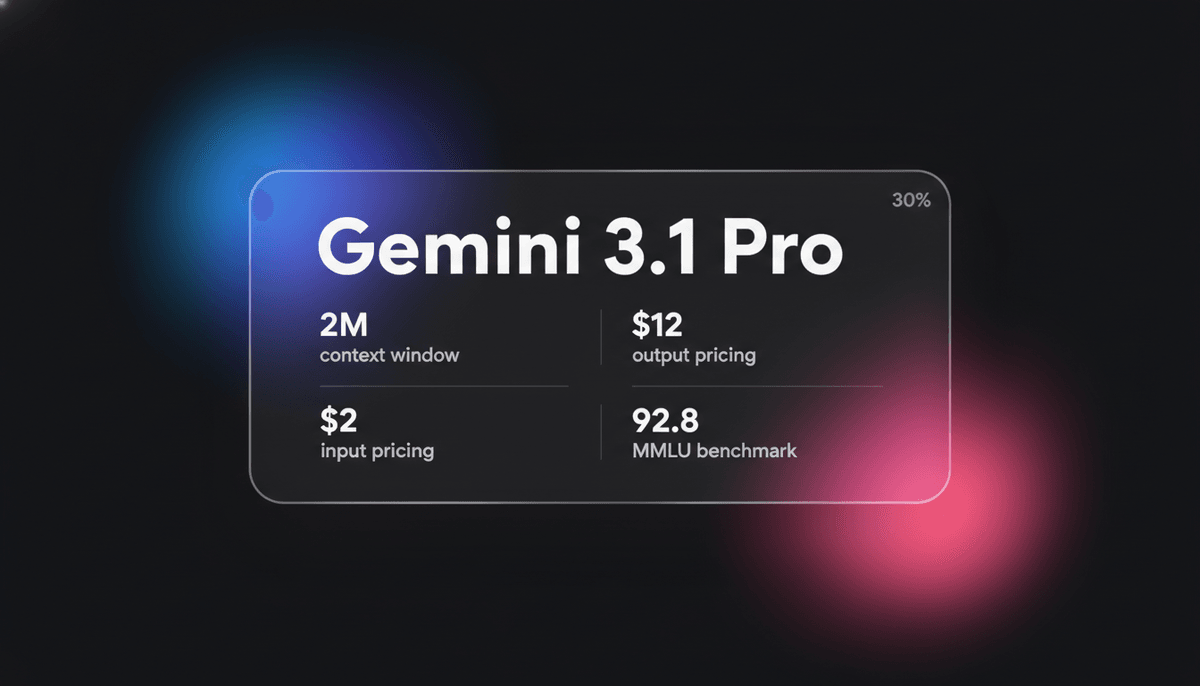
Gemini 3.1 Pro es el modelo multimodal de élite de Google que cuenta con el motor de reasoning DeepThink, una context window de más de 1M y puntuaciones de...
Acerca de Gemini 3.1 Pro
Conoce las capacidades, características y formas de uso de Gemini 3.1 Pro.
Gemini 3.1 Pro representa una ejecución madura del framework Sparse Mixture-of-Experts (MoE), combinado de forma nativa con un motor de procesamiento multimodal avanzado. La característica destacada de la arquitectura es la democratización de la capa DeepThink System 2, que permite al model deliberar internamente antes de comprometerse con un output token. Este model introduce un sistema de pensamiento único de tres niveles: Low, Medium y High, lo que permite a los desarrolladores controlar explícitamente el equilibrio entre latency, costo y profundidad de reasoning.
Con una masiva context window de 1 millón de tokens, Gemini 3.1 Pro está altamente optimizado para flujos de trabajo complejos en finanzas, análisis de datos y migraciones de código de repositorios completos. Demuestra una capacidad emergente para resolver patrones lógicos novedosos, obteniendo un 77.1% sin precedentes en el benchmark ARC-AGI-2. Esto lo convierte en la opción preferida para los desarrolladores que requieren tanto interacciones multimodales de baja latency como un rendimiento cognitivo de alto nivel para tareas agentic autónomas.
Casos de uso de Gemini 3.1 Pro
Descubre las diferentes formas de usar Gemini 3.1 Pro para lograr excelentes resultados.
Análisis de código de repositorio completo
Utiliza la context window de 1M para ingerir repositorios de software completos para refactorización y mapeo de dependencias.
Comités de agentes autónomos
Impulsa flujos de trabajo agentic de varios pasos donde sub-agentes internos debaten y verifican soluciones antes de la ejecución.
Síntesis de investigación científica
Analiza miles de artículos de investigación y conjuntos de datos complejos para extraer inteligencia estructurada y conocimientos fácticos.
Creación de contenido multimodal
Procesa simultáneamente texto, imágenes y audio para generar materiales educativos complejos y medios interactivos.
Automatización basada en terminal
Ejecuta comandos bash complejos y manipula sistemas de archivos con alta precisión mediante modos de reasoning avanzados.
Auditoría de datos empresariales
Analiza datos financieros no estructurados y documentos legales para identificar brechas de cumplimiento con una recuperación fáctica casi perfecta.
Fortalezas
Limitaciones
Inicio rápido de API
google/gemini-3.1-pro-preview
import { GoogleGenAI } from "@google/genai";
const genAI = new GoogleGenAI(process.env.GOOGLE_API_KEY);
const model = genAI.getGenerativeModel({
model: "gemini-3.1-pro-preview",
thinkingConfig: { tier: "high" }
});
const prompt = "Analyze this entire codebase for security vulnerabilities.";
const result = await model.generateContent(prompt);
console.log(result.response.text());Instala el SDK y comienza a hacer llamadas API en minutos.
Lo que la gente dice sobre Gemini 3.1 Pro
Mira lo que la comunidad piensa sobre Gemini 3.1 Pro
“La puntuación de 77.1% de Gemini 3.1 Pro representa el cambio de mercado más disruptivo; más que duplica el máximo anterior en ARC-AGI.”
“Los benchmarks de codificación no mienten. Este model encontró un bug en mi repositorio que 3.5 y GPT-4o pasaron por alto por completo.”
“El revuelo de Gemini 3.1 es realmente interesante. Aplastó los benchmarks, pero los usuarios reales dicen que el tono y la sensación son inconsistentes.”
“El motor DeepThink puede generar retrasos significativos, a veces de más de 90 segundos, al procesar tareas que requieren lógica profunda.”
“El context caching es la característica estrella aquí. Estoy ejecutando un bot de documentación completo por centavos en comparación con GPT-4o.”
“Gemini no logró hablar de Python en absoluto en una tarea de planificación compleja... algo de lógica simplemente no estaba presente en su plan final.”
Videos sobre Gemini 3.1 Pro
Mira tutoriales, reseñas y discusiones sobre Gemini 3.1 Pro
“Gemini 3.1 Pro genera la versión más detallada de esta pagoda hasta el momento”
“Gemini tiene, con diferencia, la window más amplia de un millón de tokens”
“La fidelidad multimodal en el procesamiento de audio es notablemente mejor que en 3.0”
“El throughput de tokens se mantiene estable incluso cuando la context window se llena”
“La recuperación a largo plazo es prácticamente perfecta en todo el millón de tokens”
“En acertijos que no deberían estar en sus datos de entrenamiento, la serie Gemini 3 supera a todos los demás modelos”
“3.1 Pro podría realmente reducir el tiempo de ejecución de un script de fine-tuning de 300 segundos a 47 segundos”
“Los pasos de lógica de DeepThink son claramente visibles en el trace, mostrando una deliberación real”
“Estamos llegando a la saturación de benchmarks donde solo ARC-AGI realmente importa para el progreso”
“La trayectoria hacia la AGI se está acelerando basándose en estos saltos de reasoning abstracto”
“Creo que, como 3.1, realmente se siente como un paso adelante, incluso si es solo muy leve”
“Parece superar a Gemini 3.0 Pro cuando probamos exactamente los mismos prompts lado a lado”
“La precisión de codificación en refactorizaciones complejas de Python es la más alta que he visto”
“La confiabilidad de la API ha mejorado significativamente durante el último mes de pruebas”
“El rendimiento en el mundo real finalmente coincide con el hype de las puntuaciones de los benchmarks”
Potencia tu flujo de trabajo con Automatizacion IA
Automatio combina el poder de agentes de IA, automatizacion web e integraciones inteligentes para ayudarte a lograr mas en menos tiempo.
Consejos Pro para Gemini 3.1 Pro
Consejos de expertos para ayudarte a sacar el máximo provecho de Gemini 3.1 Pro.
Selección de nivel de reasoning
Utilice el modo de pensamiento High para matemáticas o lógica compleja, pero cambie a Low para un formateo estándar y así ahorrar compute.
Context Caching
Implemente context caching para documentación estática y así reducir los precios de entrada hasta en un 90% por millón de tokens.
Artifacts estructurados
Aproveche la capacidad del model para generar listas de tareas estructuradas que faciliten la supervisión humana durante ejecuciones agentic.
Prompting multimodal
Combine entradas de video y audio para darle al model un contexto completo de escenarios del mundo real en lugar de descripciones solo en texto.
Testimonios
Lo Que Dicen Nuestros Usuarios
Unete a miles de usuarios satisfechos que han transformado su flujo de trabajo
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Relacionados AI Models
Claude Opus 4.7
Anthropic
Claude Opus 4.7 is Anthropic's flagship model with a 1-million-token context, adaptive reasoning, and 3.3x vision resolution for enterprise-scale agents.
Gemini 3.1 Flash Live Preview
Gemini 3.1 Flash Live Preview is Google's ultra-low-latency, audio-to-audio model featuring a 131K context window, high-fidelity multimodal reasoning, and...
GPT-5.5
OpenAI
GPT-5.5 is OpenAI's flagship frontier model with a 1M context window and five reasoning effort levels, optimized for autonomous agentic workflows and coding.
Grok-3
xAI
Grok-3 is xAI's flagship reasoning model, featuring deep logic deduction, a 128k context window, and real-time integration with X for live research and coding.
Kimi K3
Moonshot
Kimi K3 is Moonshot AI's 2.8T MoE model with a 1M token context window, native multimodal vision, and frontier-tier coding performance for complex agents.
GPT-5.2 Pro
OpenAI
GPT-5.2 Pro is OpenAI's 2025 flagship reasoning model featuring Extended Thinking for SOTA performance in mathematics, coding, and expert knowledge work.
Qwen 3.7 Max
alibaba
Qwen 3.7 Max is Alibaba’s flagship AI model for deep reasoning and autonomous agent tasks, featuring a 256k context window and top-tier coding performance.
Gemini 3 Pro
Google's Gemini 3 Pro is a multimodal powerhouse featuring a 1M token context window, native video processing, and industry-leading reasoning performance.
Preguntas Frecuentes Sobre Gemini 3.1 Pro
Encuentra respuestas a preguntas comunes sobre Gemini 3.1 Pro