Comment scraper les forfaits touristiques et les avis Thrillophilia
Découvrez comment scraper Thrillophilia pour extraire les prix des forfaits, les itinéraires et les avis clients. Données de voyage de haute qualité pour...
Protection Anti-Bot Détectée
- Cloudflare
- WAF et gestion de bots de niveau entreprise. Utilise des défis JavaScript, des CAPTCHAs et l'analyse comportementale. Nécessite l'automatisation du navigateur avec des paramètres furtifs.
- Limitation de débit
- Limite les requêtes par IP/session dans le temps. Peut être contourné avec des proxys rotatifs, des délais de requête et du scraping distribué.
- Blocage IP
- Bloque les IP de centres de données connues et les adresses signalées. Nécessite des proxys résidentiels ou mobiles pour contourner efficacement.
- Empreinte navigateur
- Identifie les bots par les caractéristiques du navigateur : canvas, WebGL, polices, plugins. Nécessite du spoofing ou de vrais profils de navigateur.
À Propos de Thrillophilia
Découvrez ce que Thrillophilia offre et quelles données précieuses peuvent être extraites.
La destination de premier choix pour les expériences de voyage
Thrillophilia est une plateforme de voyage et d'aventure de premier plan basée en Inde, qui propose des forfaits touristiques de bout en bout, dirigés par des experts, à travers le monde. Elle se spécialise dans des expériences de voyage sélectionnées allant des expéditions dans l'Himalaya et des circuits patrimoniaux au Rajasthan aux escapades internationales en Europe, en Asie du Sud-Est et au Moyen-Orient.
Richesse et valeur des données
La plateforme propose des listes détaillées pour des circuits de plusieurs jours, des forfaits lune de miel et des aventures de groupe. Les annonces sur Thrillophilia contiennent une multitude de données structurées, notamment des itinéraires spécifiques, des détails d'hébergement nuit par nuit, des tarifs réduits, des évaluations d'utilisateurs et des avis descriptifs. Ces informations sont extrêmement précieuses pour les agences de voyages et les chargés d'études de marché.
Pourquoi c'est important pour l'analyse de données
Pour les entreprises du secteur du voyage, scraper Thrillophilia offre un avantage concurrentiel. En surveillant les fluctuations de prix et le sentiment des clients à travers les avis, les entreprises peuvent optimiser leurs propres offres et identifier les tendances de voyage émergentes avant qu'elles ne deviennent grand public.
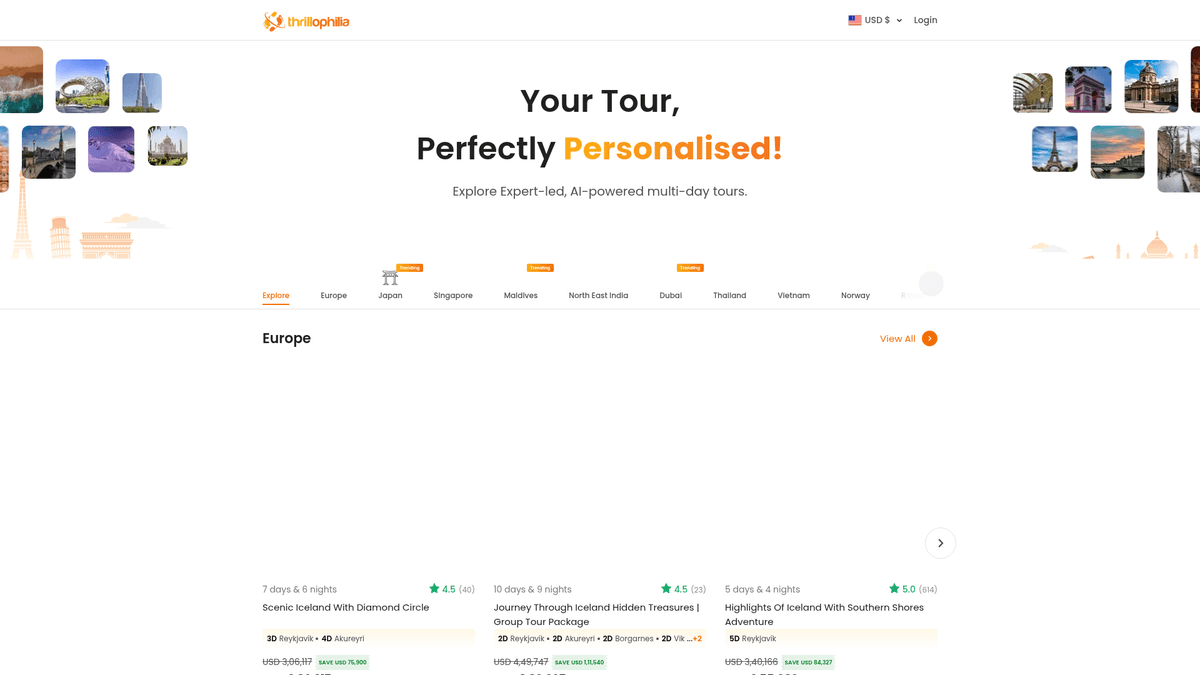
Pourquoi Scraper Thrillophilia?
Découvrez la valeur commerciale et les cas d'utilisation pour l'extraction de données de Thrillophilia.
Veille tarifaire en temps réel
Surveillez les fluctuations dynamiques des prix et les remises saisonnières sur Thrillophilia pour garantir que vos propres offres de voyage restent compétitives sur le marché.
Benchmarking d'itinéraires
Extrayez les plans détaillés jour par jour et les listes d'inclusions pour analyser comment les principaux voyagistes structurent leurs expériences et utilisez ces données pour améliorer vos propres produits.
Analyse de sentiment et des avis
Rassemblez des milliers d'avis d'utilisateurs pour effectuer une analyse de sentiment, en identifiant les points de friction courants des voyageurs et les attractions populaires selon les données démographiques.
Identification des tendances du marché
Suivez la fréquence des nouvelles annonces et les volumes d'avis pour des destinations spécifiques afin d'identifier les zones touristiques émergentes avant qu'elles ne deviennent grand public.
Suivi de la performance des opérateurs
Identifiez et évaluez les prestataires de services locaux et les voyagistes mentionnés dans les annonces pour constituer une base de données de partenaires commerciaux potentiels de haute qualité.
Défis du Scraping
Défis techniques que vous pouvez rencontrer lors du scraping de Thrillophilia.
Gestion des bots par Cloudflare
Thrillophilia utilise une protection Cloudflare agressive qui peut détecter et bloquer les requêtes automatisées standard via le fingerprinting du navigateur et les vérifications de réputation d'IP.
Rendu de contenu dynamique
Le site est construit avec Next.js, ce qui signifie que des données cruciales comme les prix et les itinéraires sont souvent injectées via JavaScript après le chargement initial de la page, nécessitant un navigateur headless.
Pagination interactive
Au lieu des pages numérotées traditionnelles, de nombreuses sections utilisent un bouton « Charger plus de produits » qui nécessite une interaction active du navigateur pour révéler tout le catalogue.
Extraction de données imbriquées
Les itinéraires de voyage sont souvent stockés dans des structures HTML imbriquées complexes (Jour 1, Jour 2, etc.), ce qui rend difficile le maintien d'un mappage de données propre sans sélecteurs avancés.
Scrapez Thrillophilia avec l'IA
Aucun code requis. Extrayez des données en minutes avec l'automatisation par IA.
Comment ça marche
Décrivez ce dont vous avez besoin
Dites à l'IA quelles données vous souhaitez extraire de Thrillophilia. Tapez simplement en langage naturel — pas de code ni de sélecteurs.
L'IA extrait les données
Notre intelligence artificielle navigue sur Thrillophilia, gère le contenu dynamique et extrait exactement ce que vous avez demandé.
Obtenez vos données
Recevez des données propres et structurées, prêtes à exporter en CSV, JSON ou à envoyer directement à vos applications.
Pourquoi utiliser l'IA pour le scraping
L'IA facilite le scraping de Thrillophilia sans écrire de code. Notre plateforme alimentée par l'intelligence artificielle comprend quelles données vous voulez — décrivez-les en langage naturel et l'IA les extrait automatiquement.
How to scrape with AI:
- Décrivez ce dont vous avez besoin: Dites à l'IA quelles données vous souhaitez extraire de Thrillophilia. Tapez simplement en langage naturel — pas de code ni de sélecteurs.
- L'IA extrait les données: Notre intelligence artificielle navigue sur Thrillophilia, gère le contenu dynamique et extrait exactement ce que vous avez demandé.
- Obtenez vos données: Recevez des données propres et structurées, prêtes à exporter en CSV, JSON ou à envoyer directement à vos applications.
Why use AI for scraping:
- Contournement automatique des anti-bots: Automatio gère automatiquement les défis complexes tels que Cloudflare et le fingerprinting du navigateur, garantissant que vos scrapers fonctionnent sans intervention manuelle constante.
- Gestion visuelle de la pagination: Configurez facilement l'outil pour cliquer sur les boutons « Charger plus » ou naviguer à travers des liens imbriqués de manière visuelle, éliminant le besoin de scripts de boucle complexes.
- Extraction compatible JavaScript: Puisqu'Automatio agit comme un vrai navigateur, il attend que les composants Next.js soient totalement chargés, capturant les prix finaux et les détails des itinéraires avec précision à chaque fois.
- Exportation de données structurées: Transformez automatiquement les détails complexes des voyages en formats CSV ou JSON propres et structurés, prêts pour une utilisation immédiate dans vos bases de données internes ou vos model AI.
Scrapers Web No-Code pour Thrillophilia
Alternatives pointer-cliquer au scraping alimenté par l'IA
Plusieurs outils no-code comme Browse.ai, Octoparse, Axiom et ParseHub peuvent vous aider à scraper Thrillophilia sans écrire de code. Ces outils utilisent généralement des interfaces visuelles pour sélectionner les données, bien qu'ils puissent avoir des difficultés avec le contenu dynamique complexe ou les mesures anti-bot.
Workflow Typique avec les Outils No-Code
Défis Courants
Courbe d'apprentissage
Comprendre les sélecteurs et la logique d'extraction prend du temps
Les sélecteurs cassent
Les modifications du site web peuvent casser tout le workflow
Problèmes de contenu dynamique
Les sites riches en JavaScript nécessitent des solutions complexes
Limitations des CAPTCHAs
La plupart des outils nécessitent une intervention manuelle pour les CAPTCHAs
Blocage d'IP
Le scraping agressif peut entraîner le blocage de votre IP
Scrapers Web No-Code pour Thrillophilia
Plusieurs outils no-code comme Browse.ai, Octoparse, Axiom et ParseHub peuvent vous aider à scraper Thrillophilia sans écrire de code. Ces outils utilisent généralement des interfaces visuelles pour sélectionner les données, bien qu'ils puissent avoir des difficultés avec le contenu dynamique complexe ou les mesures anti-bot.
Workflow Typique avec les Outils No-Code
- Installer l'extension de navigateur ou s'inscrire sur la plateforme
- Naviguer vers le site web cible et ouvrir l'outil
- Sélectionner en point-and-click les éléments de données à extraire
- Configurer les sélecteurs CSS pour chaque champ de données
- Configurer les règles de pagination pour scraper plusieurs pages
- Gérer les CAPTCHAs (nécessite souvent une résolution manuelle)
- Configurer la planification pour les exécutions automatiques
- Exporter les données en CSV, JSON ou se connecter via API
Défis Courants
- Courbe d'apprentissage: Comprendre les sélecteurs et la logique d'extraction prend du temps
- Les sélecteurs cassent: Les modifications du site web peuvent casser tout le workflow
- Problèmes de contenu dynamique: Les sites riches en JavaScript nécessitent des solutions complexes
- Limitations des CAPTCHAs: La plupart des outils nécessitent une intervention manuelle pour les CAPTCHAs
- Blocage d'IP: Le scraping agressif peut entraîner le blocage de votre IP
Exemples de Code
import requests
from bs4 import BeautifulSoup
# Thrillophilia utilise Cloudflare, les requêtes standard peuvent donc échouer sans en-têtes appropriés
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
url = 'https://www.thrillophilia.com/destinations/bali/tours'
def scrape_thrill(url):
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Les sélecteurs varient selon les pages de destination spécifiques
tours = soup.select('.tour-card')
for tour in tours:
title = tour.find('h3').text.strip()
price = tour.select_one('.price-value').text.strip() if tour.select_one('.price-value') else 'N/A'
print(f'Tour : {title} | Prix : {price}')
except Exception as e:
print(f'Une erreur est survenue : {e}')
scrape_thrill(url)Quand Utiliser
Idéal pour les pages HTML statiques avec peu de JavaScript. Parfait pour les blogs, sites d'actualités et pages e-commerce simples.
Avantages
- ●Exécution la plus rapide (sans surcharge navigateur)
- ●Consommation de ressources minimale
- ●Facile à paralléliser avec asyncio
- ●Excellent pour les APIs et pages statiques
Limitations
- ●Ne peut pas exécuter JavaScript
- ●Échoue sur les SPAs et contenu dynamique
- ●Peut avoir des difficultés avec les systèmes anti-bot complexes
Comment Scraper Thrillophilia avec du Code
Python + Requests
import requests
from bs4 import BeautifulSoup
# Thrillophilia utilise Cloudflare, les requêtes standard peuvent donc échouer sans en-têtes appropriés
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
url = 'https://www.thrillophilia.com/destinations/bali/tours'
def scrape_thrill(url):
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Les sélecteurs varient selon les pages de destination spécifiques
tours = soup.select('.tour-card')
for tour in tours:
title = tour.find('h3').text.strip()
price = tour.select_one('.price-value').text.strip() if tour.select_one('.price-value') else 'N/A'
print(f'Tour : {title} | Prix : {price}')
except Exception as e:
print(f'Une erreur est survenue : {e}')
scrape_thrill(url)Python + Playwright
from playwright.sync_api import sync_playwright
def run():
with sync_playwright() as p:
# Le lancement avec un profil de navigateur réel aide à contourner les détections de base
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto('https://www.thrillophilia.com/destinations/egypt/tours', wait_until='networkidle')
# Attendre que les cartes de circuit se chargent dynamiquement
page.wait_for_selector('.tour-card')
tours = page.query_selector_all('.tour-card')
for tour in tours:
title = tour.query_selector('h3').inner_text()
print(f'Extrait : {title}')
browser.close()
run()Python + Scrapy
import scrapy
class ThrillSpider(scrapy.Spider):
name = 'thrillophilia'
start_urls = ['https://www.thrillophilia.com/destinations/japan/tours']
def parse(self, response):
for tour in response.css('.tour-card'):
yield {
'title': tour.css('h3::text').get(),
'price': tour.css('.current-price::text').get(),
'rating': tour.css('.rating-value::text').get()
}
# Gestion de la pagination
next_page = response.css('a.next-page::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.thrillophilia.com/destinations/maldives');
// Exécuter le script dans le contexte du navigateur pour extraire les données
const tours = await page.evaluate(() => {
const items = document.querySelectorAll('.tour-card');
return Array.from(items).map(item => ({
title: item.querySelector('h3')?.innerText,
price: item.querySelector('.price')?.innerText
}));
});
console.log(tours);
await browser.close();
})();Que Pouvez-Vous Faire Avec Les Données de Thrillophilia
Explorez les applications pratiques et les insights des données de Thrillophilia.
Suivi dynamique des prix
Surveillez quotidiennement le prix des activités pour ajuster les stratégies de tarification concurrentielle.
Comment implémenter :
- 1Scraper quotidiennement les prix des circuits pour les destinations phares
- 2Stocker les données historiques dans une base de données SQL
- 3Configurer des alertes pour les baisses de prix supérieures à 15 %
- 4Synchroniser avec le CRM interne pour mettre à jour vos propres tarifs
Utilisez Automatio pour extraire des données de Thrillophilia et créer ces applications sans écrire de code.
Que Pouvez-Vous Faire Avec Les Données de Thrillophilia
- Suivi dynamique des prix
Surveillez quotidiennement le prix des activités pour ajuster les stratégies de tarification concurrentielle.
- Scraper quotidiennement les prix des circuits pour les destinations phares
- Stocker les données historiques dans une base de données SQL
- Configurer des alertes pour les baisses de prix supérieures à 15 %
- Synchroniser avec le CRM interne pour mettre à jour vos propres tarifs
- Analyse de sentiment sur les avis
Analysez des milliers d'avis pour comprendre les points de douleur des voyageurs.
- Extraire tous les textes d'avis et les notes
- Appliquer des NLP models pour catégoriser le sentiment
- Identifier des mots-clés spécifiques liés à la 'sécurité' ou aux 'retards'
- Générer des rapports pour l'amélioration du service
- Découverte des tendances d'itinéraires
Utilisez les données d'itinéraires pour concevoir de nouveaux forfaits touristiques qui suivent les tendances du marché.
- Scraper le détail nuit par nuit des circuits les plus vendus
- Identifier les schémas récurrents d'hôtels et d'activités
- Comparer la popularité des destinations entre différentes régions
- Rédiger de nouveaux produits basés sur les structures d'itinéraires performantes
- Génération de leads pour l'équipement de voyage
Identifiez les activités populaires pour cibler les ventes d'équipement vers des segments démographiques spécifiques.
- Suivre les types d'aventures les plus réservés (ex: trekking vs luxe)
- Corréler la popularité des activités avec les tendances saisonnières
- Cibler les campagnes marketing pour l'équipement en fonction des tags d'activité de la destination
- Vérification des tour-opérateurs
Surveillez quels opérateurs sont systématiquement bien notés sur toute la plateforme.
- Extraire les noms des opérateurs et leurs scores d'évaluation moyens
- Suivre le volume de circuits gérés par chaque opérateur
- Évaluer les partenaires potentiels pour votre propre réseau d'agences de voyages
Optimisez votre flux de travail avec l'Automatisation IA
Automatio combine la puissance des agents IA, de l'automatisation web et des integrations intelligentes pour vous aider a accomplir plus en moins de temps.
Conseils Pro pour Scraper Thrillophilia
Conseils d'experts pour extraire avec succès les données de Thrillophilia.
Priorisez les proxies résidentiels
Pour éviter d'être repéré par les systèmes de sécurité de Thrillophilia, utilisez des proxies résidentiels de haute qualité qui imitent le trafic d'utilisateurs réels plutôt que des IPs de centres de données.
Extrayez le script NEXT_DATA
Vérifiez le code source de la page pour une balise script contenant __NEXT_DATA__ ; elle contient souvent un objet JSON complet des données de la page, ce qui peut être beaucoup plus rapide à parsemer.
Implémentez des délais aléatoires
Configurez des temps d'attente aléatoires entre les interactions pour imiter les schémas de navigation humaine et réduire la probabilité de déclencher des rate limits ou des défis de sécurité.
Gérez le Lazy-Loading des images
De nombreuses images ne se chargent que lorsqu'elles entrent dans le viewport ; assurez-vous que votre scraper défile sur la page pour capturer correctement toutes les URLs des photos de voyage.
Normalisez la devise et le prix
Les prix peuvent varier en fonction de la localisation de votre proxy. Extrayez toujours le code de la devise aux côtés de la valeur numérique pour éviter toute incohérence des données.
Témoignages
Ce Que Disent Nos Utilisateurs
Rejoignez des milliers d'utilisateurs satisfaits qui ont transforme leur flux de travail
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Associés Web Scraping
Questions Fréquentes sur Thrillophilia
Trouvez des réponses aux questions courantes sur Thrillophilia