
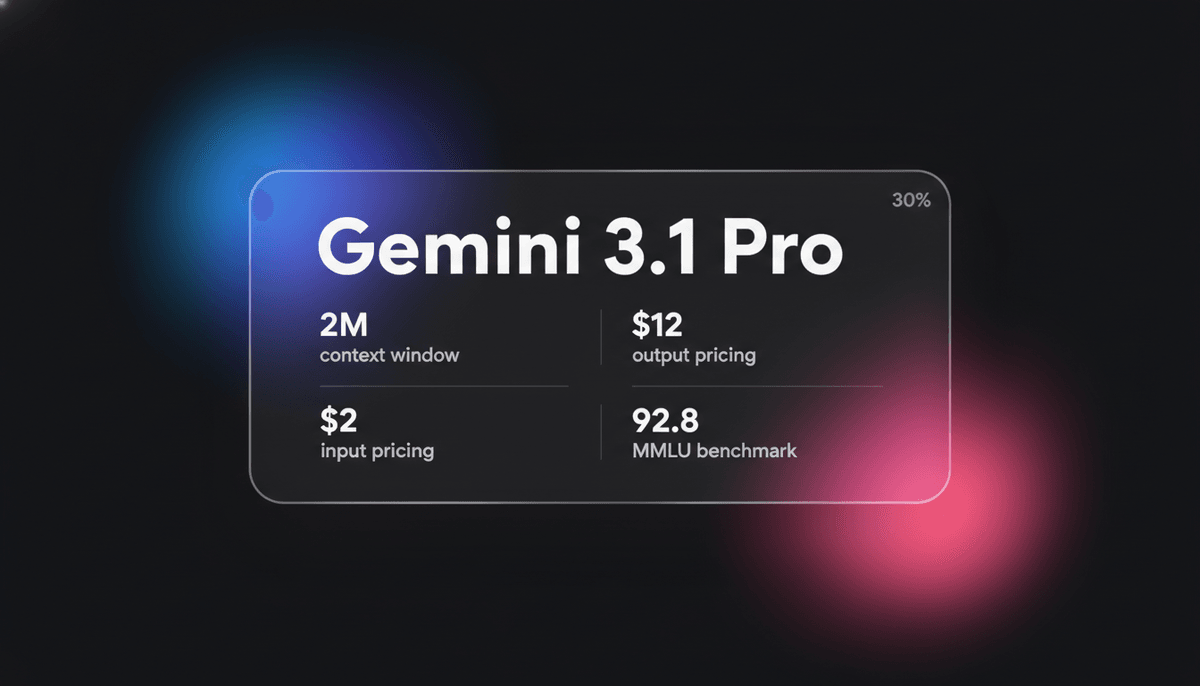
Gemini 3.1 Pro
Gemini 3.1 Pro est le modèle multimodal d'élite de Google, doté du moteur de reasoning DeepThink, d'une context window de plus de 1M et de scores logiques...
À propos de Gemini 3.1 Pro
Découvrez les capacités, fonctionnalités et façons d'utiliser Gemini 3.1 Pro.
Gemini 3.1 Pro représente une exécution mature du framework Sparse Mixture-of-Experts (MoE), couplé nativement à un moteur de traitement multimodal avancé. La caractéristique notable de l'architecture est la démocratisation de la couche DeepThink System 2, qui permet au modèle de délibérer en interne avant de s'engager sur un token de sortie. Ce modèle introduit un système de réflexion unique à trois niveaux, Faible, Moyen et Élevé, permettant aux développeurs de contrôler explicitement le compromis entre latency, coût et profondeur de reasoning.
Avec une context window massive de 1 million de tokens, Gemini 3.1 Pro est hautement optimisé pour les workflows complexes en finance, analyse de données et migrations de code de dépôts entiers. Il démontre une capacité émergente à résoudre des modèles logiques inédits, obtenant un score sans précédent de 77,1 % sur le benchmark ARC-AGI-2. Cela en fait un choix privilégié pour les développeurs qui nécessitent à la fois des interactions multimodal à faible latency et une performance cognitive de haut niveau pour des tâches agentic autonomes.
Cas d'utilisation de Gemini 3.1 Pro
Découvrez les différentes façons d'utiliser Gemini 3.1 Pro pour obtenir d'excellents résultats.
Analyse de code sur l'ensemble d'un dépôt
Utilisation de la context window de 1M pour ingérer des dépôts logiciels entiers afin de procéder à du refactoring et à la cartographie des dépendances.
Comités d'agents autonomes
Pilotage de workflows agentic multi-étapes où des sous-agents internes débattent et vérifient les solutions avant l'exécution.
Synthèse de recherche scientifique
Analyse de milliers d'articles de recherche et de jeux de données complexes pour extraire des renseignements structurés et des insights factuels.
Création de contenu multimodal
Traitement simultané de texte, d'images et d'audio pour générer des supports pédagogiques complexes et des médias interactifs.
Automatisation via terminal
Exécution de commandes bash complexes et manipulation de systèmes de fichiers avec une haute précision via des modes de reasoning avancés.
Audit de données d'entreprise
Analyse de données financières non structurées et de documents juridiques pour identifier les écarts de conformité avec un rappel factuel quasi parfait.
Points forts
Limitations
Démarrage rapide API
google/gemini-3.1-pro-preview
import { GoogleGenAI } from "@google/genai";
const genAI = new GoogleGenAI(process.env.GOOGLE_API_KEY);
const model = genAI.getGenerativeModel({
model: "gemini-3.1-pro-preview",
thinkingConfig: { tier: "high" }
});
const prompt = "Analyze this entire codebase for security vulnerabilities.";
const result = await model.generateContent(prompt);
console.log(result.response.text());Installez le SDK et commencez à faire des appels API en quelques minutes.
Ce que les gens disent de Gemini 3.1 Pro
Voyez ce que la communauté pense de Gemini 3.1 Pro
“Le score de 77,1 % de Gemini 3.1 Pro représente le changement de marché le plus disruptif ; il double plus que le précédent record sur ARC-AGI.”
“Les benchmarks de codage ne mentent pas. Ce modèle a trouvé un bug dans mon repo que 3.5 et GPT-4o ont complètement manqué.”
“Le scandale Gemini 3.1 est vraiment intéressant. Il a écrasé les benchmarks mais les vrais utilisateurs disent que le ton et l'ambiance sont incohérents.”
“Le moteur DeepThink peut entraîner des retards importants, parfois plus de 90 secondes, lors du traitement de tâches nécessitant une logique profonde.”
“La mise en cache de contexte est la fonctionnalité phare ici. Je fais tourner un bot de documentation entier pour des centimes par rapport à GPT-4o.”
“Gemini n'a pas réussi à discuter de Python dans une tâche de planification complexe... une partie de la logique était tout simplement absente de son plan final.”
Vidéos sur Gemini 3.1 Pro
Regardez des tutoriels, critiques et discussions sur Gemini 3.1 Pro
“Gemini 3.1 Pro génère la version la plus détaillée de cette pagode jusqu'à présent”
“Gemini a de loin la plus large fenêtre d'un million de tokens”
“La fidélité multimodal dans le traitement audio est sensiblement meilleure que sur le 3.0”
“Le throughput des tokens reste stable même lorsque la context window se remplit”
“Le rappel à long terme est pratiquement parfait sur l'ensemble du million de tokens”
“Sur des puzzles qui ne devraient pas être dans ses données d'entraînement, la série Gemini 3 surpasse tous les autres modèles”
“3.1 Pro pourrait effectivement réduire le temps d'exécution d'un script de fine-tuning de 300 secondes à 47 secondes”
“Les étapes de logique DeepThink sont clairement visibles dans la trace, montrant une réelle délibération”
“Nous atteignons une saturation des benchmarks où seul ARC-AGI compte vraiment pour le progrès”
“La trajectoire vers l'AGI s'accélère grâce à ces sauts en reasoning abstrait”
“Je pense vraiment que le 3.1 est une avancée, même si elle est très légère”
“Il semble surpasser Gemini 3.0 Pro lorsque nous testons exactement les mêmes prompts côte à côte”
“La précision du codage sur des refactors Python complexes est la meilleure que j'aie vue”
“La fiabilité de l'API s'est considérablement améliorée au cours du dernier mois de test”
“Les performances en situation réelle correspondent enfin au battage médiatique des scores de benchmark”
Optimisez votre flux de travail avec l'Automatisation IA
Automatio combine la puissance des agents IA, de l'automatisation web et des integrations intelligentes pour vous aider a accomplir plus en moins de temps.
Conseils Pro pour Gemini 3.1 Pro
Conseils d'experts pour tirer le meilleur parti de Gemini 3.1 Pro.
Sélection du niveau de reasoning
Utilisez le mode de réflexion Élevé pour les mathématiques ou la logique complexe, mais passez au mode Faible pour la mise en forme standard afin d'économiser du compute.
Mise en cache de contexte
Implémentez la mise en cache de contexte pour la documentation statique afin de réduire les prix d'entrée jusqu'à 90 % par million de tokens.
Artifacts structurés
Tirez parti de la capacité du modèle à générer des listes de tâches structurées pour une supervision humaine facilitée lors des exécutions agentic.
Prompting multimodal
Combinez des entrées vidéo et audio pour donner au modèle un contexte complet de scénarios réels plutôt que de simples descriptions textuelles.
Témoignages
Ce Que Disent Nos Utilisateurs
Rejoignez des milliers d'utilisateurs satisfaits qui ont transforme leur flux de travail
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Associés AI Models
Claude Opus 4.7
Anthropic
Claude Opus 4.7 is Anthropic's flagship model with a 1-million-token context, adaptive reasoning, and 3.3x vision resolution for enterprise-scale agents.
Gemini 3.1 Flash Live Preview
Gemini 3.1 Flash Live Preview is Google's ultra-low-latency, audio-to-audio model featuring a 131K context window, high-fidelity multimodal reasoning, and...
GPT-5.5
OpenAI
GPT-5.5 is OpenAI's flagship frontier model with a 1M context window and five reasoning effort levels, optimized for autonomous agentic workflows and coding.
Grok-3
xAI
Grok-3 is xAI's flagship reasoning model, featuring deep logic deduction, a 128k context window, and real-time integration with X for live research and coding.
Kimi K3
Moonshot
Kimi K3 is Moonshot AI's 2.8T MoE model with a 1M token context window, native multimodal vision, and frontier-tier coding performance for complex agents.
GPT-5.2 Pro
OpenAI
GPT-5.2 Pro is OpenAI's 2025 flagship reasoning model featuring Extended Thinking for SOTA performance in mathematics, coding, and expert knowledge work.
Qwen 3.7 Max
alibaba
Qwen 3.7 Max is Alibaba’s flagship AI model for deep reasoning and autonomous agent tasks, featuring a 256k context window and top-tier coding performance.
Gemini 3 Pro
Google's Gemini 3 Pro is a multimodal powerhouse featuring a 1M token context window, native video processing, and industry-leading reasoning performance.
Questions Fréquentes sur Gemini 3.1 Pro
Trouvez des réponses aux questions courantes sur Gemini 3.1 Pro