Cara Melakukan Scraping Paket Wisata & Ulasan Thrillophilia
Pelajari cara melakukan scraping Thrillophilia untuk mengekstrak harga paket wisata, rencana perjalanan, dan ulasan pelanggan. Data perjalanan berkualitas...
Perlindungan Anti-Bot Terdeteksi
- Cloudflare
- WAF dan manajemen bot tingkat enterprise. Menggunakan tantangan JavaScript, CAPTCHA, dan analisis perilaku. Memerlukan otomatisasi browser dengan pengaturan stealth.
- Pembatasan kecepatan
- Membatasi permintaan per IP/sesi dari waktu ke waktu. Dapat dilewati dengan proxy berputar, penundaan permintaan, dan scraping terdistribusi.
- Pemblokiran IP
- Memblokir IP pusat data yang dikenal dan alamat yang ditandai. Memerlukan proxy residensial atau seluler untuk melewati secara efektif.
- Sidik jari browser
- Mengidentifikasi bot melalui karakteristik browser: canvas, WebGL, font, plugin. Memerlukan spoofing atau profil browser asli.
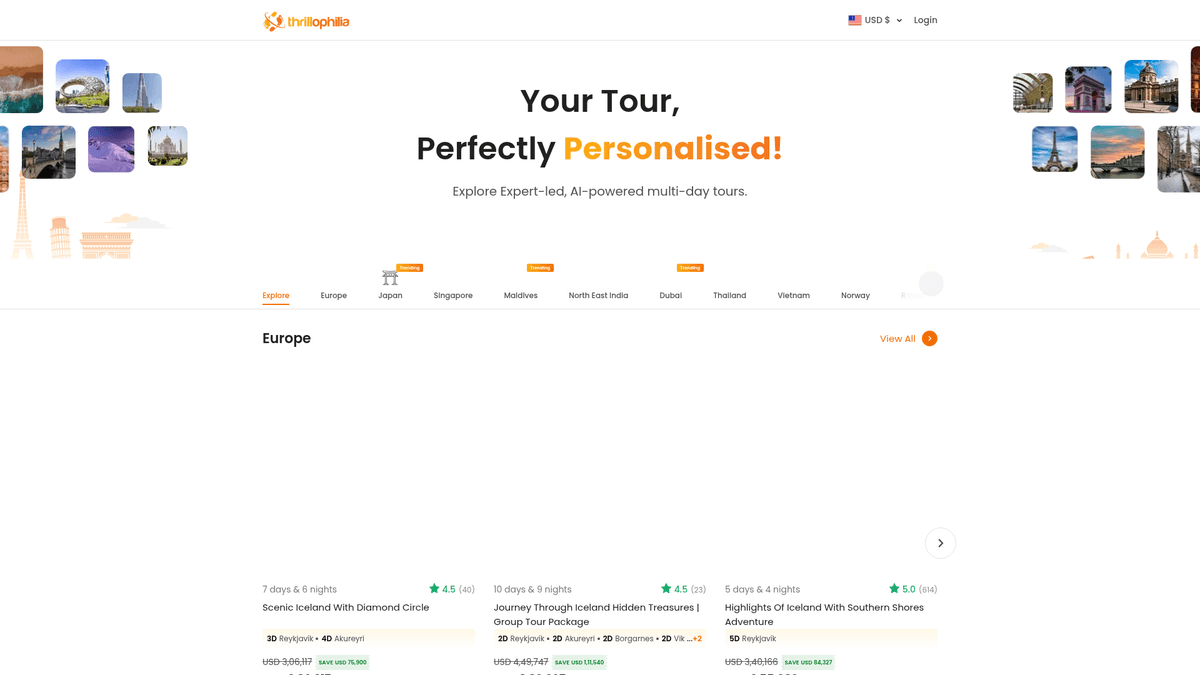
Tentang Thrillophilia
Temukan apa yang ditawarkan Thrillophilia dan data berharga apa yang dapat diekstrak.
Destinasi Utama untuk Pengalaman Perjalanan
Thrillophilia adalah platform perjalanan dan petualangan terkemuka yang berbasis di India yang menyediakan paket wisata menyeluruh yang dipandu oleh ahli ke seluruh dunia. Platform ini berspesialisasi dalam pengalaman perjalanan yang dikurasi, mulai dari ekspedisi Himalaya dan tur warisan Rajasthan hingga perjalanan internasional di Eropa, Asia Tenggara, dan Timur Tengah.
Kekayaan dan Nilai Data
Platform ini menampilkan daftar mendetail untuk tur multi-hari, paket bulan madu, dan petualangan grup. Daftar di Thrillophilia berisi banyak data terstruktur termasuk rencana perjalanan spesifik, rincian menginap malam demi malam, harga diskon, rating pengguna, dan ulasan deskriptif. Informasi ini sangat berharga bagi biro perjalanan dan peneliti pasar.
Mengapa Ini Penting untuk Analisis Data
Bagi bisnis di sektor perjalanan, melakukan scraping Thrillophilia memberikan keunggulan kompetitif. Dengan memantau fluktuasi harga dan sentimen pelanggan melalui ulasan, perusahaan dapat mengoptimalkan penawaran mereka sendiri dan mengidentifikasi tren perjalanan yang muncul sebelum menjadi arus utama.
Mengapa Melakukan Scraping Thrillophilia?
Temukan nilai bisnis dan kasus penggunaan untuk ekstraksi data dari Thrillophilia.
Pantau harga kompetitor untuk paket wisata serupa secara real-time
Analisis sentimen pelanggan dan kualitas layanan melalui ulasan pengguna yang mendetail
Agregasikan rencana perjalanan yang kompleks untuk analisis tren pasar global
Identifikasi destinasi perjalanan yang populer dan sedang berkembang untuk perencanaan strategis
Lacak metrik keandalan dan kinerja operator tur lokal
Beri makan model AI dengan data rencana perjalanan terstruktur untuk perencanaan perjalanan otomatis
Tantangan Scraping
Tantangan teknis yang mungkin Anda hadapi saat melakukan scraping Thrillophilia.
Mekanisme perlindungan bot Cloudflare yang agresif
Pemuatan konten dinamis melalui framework Next.js dan React
Struktur HTML bertingkat yang kompleks untuk rencana perjalanan multi-hari
Kebijakan rate limiting yang ketat pada permintaan frekuensi tinggi
Fingerprinting browser yang mendeteksi headless browser otomatis
Scrape Thrillophilia dengan AI
Tanpa koding. Ekstrak data dalam hitungan menit dengan otomatisasi berbasis AI.
Cara Kerjanya
Jelaskan apa yang Anda butuhkan
Beritahu AI data apa yang ingin Anda ekstrak dari Thrillophilia. Cukup ketik dalam bahasa sehari-hari — tanpa kode atau selektor.
AI mengekstrak data
Kecerdasan buatan kami menjelajahi Thrillophilia, menangani konten dinamis, dan mengekstrak persis apa yang Anda minta.
Dapatkan data Anda
Terima data bersih dan terstruktur siap diekspor sebagai CSV, JSON, atau dikirim langsung ke aplikasi Anda.
Mengapa menggunakan AI untuk scraping
AI memudahkan scraping Thrillophilia tanpa menulis kode. Platform berbasis kecerdasan buatan kami memahami data apa yang Anda inginkan — cukup jelaskan dalam bahasa sehari-hari dan AI akan mengekstraknya secara otomatis.
How to scrape with AI:
- Jelaskan apa yang Anda butuhkan: Beritahu AI data apa yang ingin Anda ekstrak dari Thrillophilia. Cukup ketik dalam bahasa sehari-hari — tanpa kode atau selektor.
- AI mengekstrak data: Kecerdasan buatan kami menjelajahi Thrillophilia, menangani konten dinamis, dan mengekstrak persis apa yang Anda minta.
- Dapatkan data Anda: Terima data bersih dan terstruktur siap diekspor sebagai CSV, JSON, atau dikirim langsung ke aplikasi Anda.
Why use AI for scraping:
- Melewati tindakan anti-bot canggih seperti Cloudflare secara otomatis
- Antarmuka no-code memungkinkan pembuatan scraper perjalanan tanpa sumber daya pengembang
- Menangani rendering JavaScript dan konten dinamis dengan mudah
- Scraping terjadwal memungkinkan pemantauan harga harian secara otomatis
- Integrasi langsung dengan Google Sheets untuk visualisasi data seketika
Web Scraper Tanpa Kode untuk Thrillophilia
Alternatif klik-dan-pilih untuk scraping berbasis AI
Beberapa alat tanpa kode seperti Browse.ai, Octoparse, Axiom, dan ParseHub dapat membantu Anda melakukan scraping Thrillophilia tanpa menulis kode. Alat-alat ini biasanya menggunakan antarmuka visual untuk memilih data, meskipun mungkin kesulitan dengan konten dinamis kompleks atau tindakan anti-bot.
Alur Kerja Umum dengan Alat Tanpa Kode
Tantangan Umum
Kurva pembelajaran
Memahami selector dan logika ekstraksi membutuhkan waktu
Selector rusak
Perubahan situs web dapat merusak seluruh alur kerja
Masalah konten dinamis
Situs berbasis JavaScript memerlukan solusi yang kompleks
Keterbatasan CAPTCHA
Sebagian besar alat memerlukan intervensi manual untuk CAPTCHA
Pemblokiran IP
Scraping agresif dapat menyebabkan IP Anda diblokir
Web Scraper Tanpa Kode untuk Thrillophilia
Beberapa alat tanpa kode seperti Browse.ai, Octoparse, Axiom, dan ParseHub dapat membantu Anda melakukan scraping Thrillophilia tanpa menulis kode. Alat-alat ini biasanya menggunakan antarmuka visual untuk memilih data, meskipun mungkin kesulitan dengan konten dinamis kompleks atau tindakan anti-bot.
Alur Kerja Umum dengan Alat Tanpa Kode
- Instal ekstensi browser atau daftar di platform
- Navigasi ke situs web target dan buka alat
- Pilih elemen data yang ingin diekstrak dengan point-and-click
- Konfigurasikan selector CSS untuk setiap field data
- Atur aturan paginasi untuk scraping beberapa halaman
- Tangani CAPTCHA (sering memerlukan penyelesaian manual)
- Konfigurasikan penjadwalan untuk eksekusi otomatis
- Ekspor data ke CSV, JSON atau hubungkan melalui API
Tantangan Umum
- Kurva pembelajaran: Memahami selector dan logika ekstraksi membutuhkan waktu
- Selector rusak: Perubahan situs web dapat merusak seluruh alur kerja
- Masalah konten dinamis: Situs berbasis JavaScript memerlukan solusi yang kompleks
- Keterbatasan CAPTCHA: Sebagian besar alat memerlukan intervensi manual untuk CAPTCHA
- Pemblokiran IP: Scraping agresif dapat menyebabkan IP Anda diblokir
Contoh Kode
import requests
from bs4 import BeautifulSoup
# Thrillophilia menggunakan Cloudflare, sehingga permintaan standar mungkin gagal tanpa header atau manajemen sesi yang tepat
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
url = 'https://www.thrillophilia.com/destinations/bali/tours'
def scrape_thrill(url):
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Selektor bervariasi berdasarkan halaman destinasi spesifik
tours = soup.select('.tour-card')
for tour in tours:
title = tour.find('h3').text.strip()
price = tour.select_one('.price-value').text.strip() if tour.select_one('.price-value') else 'N/A'
print(f'Tur: {title} | Harga: {price}')
except Exception as e:
print(f'Terjadi kesalahan: {e}')
scrape_thrill(url)Kapan Digunakan
Terbaik untuk halaman HTML statis di mana konten dimuat di sisi server. Pendekatan tercepat dan paling sederhana ketika rendering JavaScript tidak diperlukan.
Kelebihan
- ●Eksekusi tercepat (tanpa overhead browser)
- ●Konsumsi sumber daya terendah
- ●Mudah diparalelkan dengan asyncio
- ●Bagus untuk API dan halaman statis
Keterbatasan
- ●Tidak dapat mengeksekusi JavaScript
- ●Gagal pada SPA dan konten dinamis
- ●Mungkin kesulitan dengan sistem anti-bot kompleks
How to Scrape Thrillophilia with Code
Python + Requests
import requests
from bs4 import BeautifulSoup
# Thrillophilia menggunakan Cloudflare, sehingga permintaan standar mungkin gagal tanpa header atau manajemen sesi yang tepat
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
url = 'https://www.thrillophilia.com/destinations/bali/tours'
def scrape_thrill(url):
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Selektor bervariasi berdasarkan halaman destinasi spesifik
tours = soup.select('.tour-card')
for tour in tours:
title = tour.find('h3').text.strip()
price = tour.select_one('.price-value').text.strip() if tour.select_one('.price-value') else 'N/A'
print(f'Tur: {title} | Harga: {price}')
except Exception as e:
print(f'Terjadi kesalahan: {e}')
scrape_thrill(url)Python + Playwright
from playwright.sync_api import sync_playwright
def run():
with sync_playwright() as p:
# Meluncurkan dengan profil browser asli membantu melewati deteksi dasar
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto('https://www.thrillophilia.com/destinations/egypt/tours', wait_until='networkidle')
# Tunggu kartu tur dimuat secara dinamis
page.wait_for_selector('.tour-card')
tours = page.query_selector_all('.tour-card')
for tour in tours:
title = tour.query_selector('h3').inner_text()
print(f'Terekstrak: {title}')
browser.close()
run()Python + Scrapy
import scrapy
class ThrillSpider(scrapy.Spider):
name = 'thrillophilia'
start_urls = ['https://www.thrillophilia.com/destinations/japan/tours']
def parse(self, response):
for tour in response.css('.tour-card'):
yield {
'title': tour.css('h3::text').get(),
'price': tour.css('.current-price::text').get(),
'rating': tour.css('.rating-value::text').get()
}
# Menangani paginasi
next_page = response.css('a.next-page::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.thrillophilia.com/destinations/maldives');
// Jalankan skrip di konteks browser untuk mengekstrak data
const tours = await page.evaluate(() => {
const items = document.querySelectorAll('.tour-card');
return Array.from(items).map(item => ({
title: item.querySelector('h3')?.innerText,
price: item.querySelector('.price')?.innerText
}));
});
console.log(tours);
await browser.close();
})();Apa yang Dapat Anda Lakukan Dengan Data Thrillophilia
Jelajahi aplikasi praktis dan wawasan dari data Thrillophilia.
Pemantauan Harga Dinamis
Pantau harga aktivitas setiap hari untuk menyesuaikan strategi penetapan harga yang kompetitif.
Cara mengimplementasikan:
- 1Lakukan scraping harga tur setiap hari untuk destinasi populer
- 2Simpan data historis dalam database SQL
- 3Siapkan peringatan untuk penurunan harga di atas 15%
- 4Sinkronkan dengan CRM internal untuk memperbarui harga Anda sendiri
Gunakan Automatio untuk mengekstrak data dari Thrillophilia dan membangun aplikasi ini tanpa menulis kode.
Apa yang Dapat Anda Lakukan Dengan Data Thrillophilia
- Pemantauan Harga Dinamis
Pantau harga aktivitas setiap hari untuk menyesuaikan strategi penetapan harga yang kompetitif.
- Lakukan scraping harga tur setiap hari untuk destinasi populer
- Simpan data historis dalam database SQL
- Siapkan peringatan untuk penurunan harga di atas 15%
- Sinkronkan dengan CRM internal untuk memperbarui harga Anda sendiri
- Analisis Sentimen pada Ulasan
Analisis ribuan ulasan untuk memahami keluhan para pelancong.
- Ekstrak semua teks ulasan dan rating
- Terapkan model NLP untuk mengategorikan sentimen
- Identifikasi kata kunci spesifik terkait 'keamanan' atau 'keterlambatan'
- Hasilkan laporan untuk peningkatan layanan
- Penemuan Tren Rencana Perjalanan
Gunakan data rencana perjalanan untuk merancang paket wisata baru yang mengikuti tren pasar.
- Lakukan scraping rincian malam demi malam dari tur terlaris
- Identifikasi pola hotel dan aktivitas yang umum
- Bandingkan popularitas destinasi di berbagai wilayah
- Rancang produk baru berdasarkan struktur rencana perjalanan yang berkinerja tinggi
- Lead Gen untuk Perlengkapan Perjalanan
Identifikasi aktivitas populer untuk menargetkan penjualan peralatan ke demografi tertentu.
- Lacak jenis petualangan yang paling banyak dipesan (misalnya, trekking vs. mewah)
- Korelasikan popularitas aktivitas dengan tren musiman
- Targetkan kampanye pemasaran untuk perlengkapan berdasarkan tag aktivitas destinasi
- Verifikasi Operator Tur
Pantau operator mana yang secara konsisten mendapatkan rating tinggi di seluruh platform.
- Ekstrak nama operator dan skor rating rata-rata mereka
- Lacak volume tur yang ditangani oleh setiap operator
- Verifikasi calon mitra untuk jaringan biro perjalanan Anda sendiri
Tingkatkan alur kerja Anda dengan Otomatisasi AI
Automatio menggabungkan kekuatan agen AI, otomatisasi web, dan integrasi cerdas untuk membantu Anda mencapai lebih banyak dalam waktu lebih singkat.
Tips Pro untuk Scraping Thrillophilia
Saran ahli untuk ekstraksi data yang sukses dari Thrillophilia.
Gunakan proxy residensial berkualitas tinggi untuk melewati perlindungan Cloudflare dengan lebih efektif
Terapkan interval sleep acak antara 5 hingga 15 detik untuk meniru perilaku browsing manusia
Rotasi string User-Agent Anda secara berkala untuk mencegah fingerprinting berbasis perangkat
Periksa tag skrip __NEXT_DATA__ yang sering kali berisi struktur JSON dari halaman tersebut
Jadwalkan scraping pada jam tidak sibuk untuk menghindari rate limiting yang ketat
Bersihkan data rencana perjalanan dengan menghapus tag HTML dan menormalkan spasi kosong
Testimoni
Apa Kata Pengguna Kami
Bergabunglah dengan ribuan pengguna puas yang telah mengubah alur kerja mereka
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Terkait Web Scraping
Pertanyaan yang Sering Diajukan tentang Thrillophilia
Temukan jawaban untuk pertanyaan umum tentang Thrillophilia