Come estrarre pacchetti tour e recensioni da Thrillophilia
Scopri come fare lo scraping di Thrillophilia per estrarre prezzi dei pacchetti tour, itinerari e recensioni dei clienti. Dati di viaggio di alta qualità per...
Protezione Anti-Bot Rilevata
- Cloudflare
- WAF e gestione bot di livello enterprise. Usa sfide JavaScript, CAPTCHA e analisi comportamentale. Richiede automazione del browser con impostazioni stealth.
- Rate Limiting
- Limita le richieste per IP/sessione nel tempo. Può essere aggirato con proxy rotanti, ritardi nelle richieste e scraping distribuito.
- Blocco IP
- Blocca IP di data center noti e indirizzi segnalati. Richiede proxy residenziali o mobili per aggirare efficacemente.
- Fingerprinting del browser
- Identifica i bot tramite caratteristiche del browser: canvas, WebGL, font, plugin. Richiede spoofing o profili browser reali.
Informazioni Su Thrillophilia
Scopri cosa offre Thrillophilia e quali dati preziosi possono essere estratti.
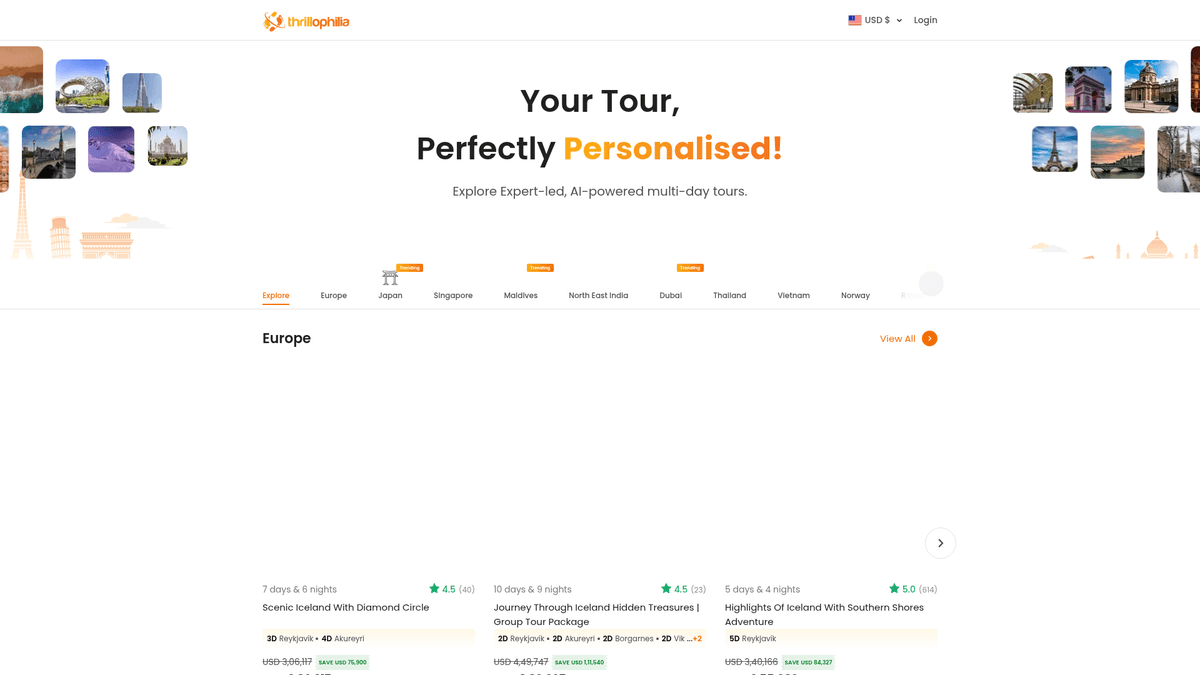
La Destinazione Principale per le Esperienze di Viaggio
Thrillophilia è una rinomata piattaforma di viaggi e avventura con sede in India che fornisce pacchetti tour completi guidati da esperti in tutto il mondo. È specializzata in esperienze di viaggio selezionate che spaziano dalle spedizioni sull'Himalaya e i tour del patrimonio del Rajasthan a fughe internazionali in Europa, Sud-est asiatico e Medio Oriente.
Ricchezza e Valore dei Dati
La piattaforma presenta elenchi dettagliati per tour di più giorni, pacchetti per lune di miele e avventure di gruppo. Gli annunci su Thrillophilia contengono una vasta gamma di dati strutturati, tra cui itinerari specifici, dettagli dei soggiorni notte per notte, prezzi scontati, valutazioni degli utenti e recensioni descrittive. Queste informazioni sono di alto valore per le agenzie di viaggio e i ricercatori di mercato.
Perché è Importante per l'Analisi dei Dati
Per le aziende del settore travel, fare scraping su Thrillophilia offre un vantaggio competitivo. Monitorando le fluttuazioni dei prezzi e il sentiment dei clienti attraverso le recensioni, le aziende possono ottimizzare le proprie offerte e identificare i trend di viaggio emergenti prima che diventino mainstream.
Perché Fare Scraping di Thrillophilia?
Scopri il valore commerciale e i casi d'uso per l'estrazione dati da Thrillophilia.
Intelligence sui prezzi in tempo reale
Monitora le fluttuazioni dinamiche dei prezzi e gli sconti stagionali su Thrillophilia per garantire che le tue offerte di viaggio rimangano competitive sul mercato.
Benchmarking degli itinerari
Estrai piani dettagliati giorno per giorno ed elenchi di inclusioni per analizzare come i principali tour operator strutturano le loro esperienze e utilizza questi dati per migliorare i tuoi prodotti.
Analisi del sentiment e delle recensioni
Raccogli migliaia di recensioni degli utenti per eseguire analisi del sentiment, identificando i punti critici comuni dei viaggiatori e le attrazioni popolari tra diverse fasce demografiche.
Identificazione dei trend di mercato
Monitora la frequenza di nuovi annunci e i volumi di recensioni per destinazioni specifiche per identificare le località emergenti prima che diventino mainstream.
Monitoraggio delle performance degli operatori
Identifica e valuta i fornitori di servizi locali e i tour operator menzionati negli annunci per costruire un database di potenziali partner commerciali di alta qualità.
Sfide dello Scraping
Sfide tecniche che potresti incontrare durante lo scraping di Thrillophilia.
Gestione bot di Cloudflare
Thrillophilia utilizza una protezione Cloudflare aggressiva in grado di rilevare e bloccare le richieste automatizzate standard attraverso il fingerprinting del browser e il controllo della reputazione dell'IP.
Rendering di contenuti dinamici
Il sito web è costruito utilizzando Next.js, il che significa che dati cruciali come prezzi e itinerari vengono spesso inseriti tramite JavaScript dopo il caricamento iniziale della pagina, richiedendo un browser headless.
Paginazione interattiva
Invece delle tradizionali pagine numerate, molte sezioni di annunci utilizzano un pulsante 'Load More Products' che richiede un'interazione attiva del browser per rivelare il catalogo completo dei tour.
Estrazione di dati annidati
Gli itinerari dei tour sono spesso memorizzati in strutture HTML annidate complesse (Giorno 1, Giorno 2, ecc.), rendendo difficile mantenere una mappatura pulita dei dati senza selettori avanzati.
Scraping di Thrillophilia con l'IA
Nessun codice richiesto. Estrai dati in minuti con l'automazione basata sull'IA.
Come Funziona
Descrivi ciò di cui hai bisogno
Di' all'IA quali dati vuoi estrarre da Thrillophilia. Scrivi semplicemente in linguaggio naturale — nessun codice o selettore necessario.
L'IA estrae i dati
La nostra intelligenza artificiale naviga Thrillophilia, gestisce contenuti dinamici ed estrae esattamente ciò che hai richiesto.
Ottieni i tuoi dati
Ricevi dati puliti e strutturati pronti per l'esportazione in CSV, JSON o da inviare direttamente alle tue applicazioni.
Perché Usare l'IA per lo Scraping
L'IA rende facile lo scraping di Thrillophilia senza scrivere codice. La nostra piattaforma basata sull'intelligenza artificiale capisce quali dati vuoi — descrivili in linguaggio naturale e l'IA li estrae automaticamente.
How to scrape with AI:
- Descrivi ciò di cui hai bisogno: Di' all'IA quali dati vuoi estrarre da Thrillophilia. Scrivi semplicemente in linguaggio naturale — nessun codice o selettore necessario.
- L'IA estrae i dati: La nostra intelligenza artificiale naviga Thrillophilia, gestisce contenuti dinamici ed estrae esattamente ciò che hai richiesto.
- Ottieni i tuoi dati: Ricevi dati puliti e strutturati pronti per l'esportazione in CSV, JSON o da inviare direttamente alle tue applicazioni.
Why use AI for scraping:
- Bypass automatico degli anti-bot: Automatio gestisce automaticamente sfide complesse come Cloudflare e il fingerprinting del browser, garantendo che i tuoi scraper funzionino senza costanti interventi manuali.
- Gestione visiva della paginazione: Configura facilmente lo strumento per cliccare sui pulsanti 'Load More' o navigare attraverso link annidati in modo visivo, eliminando la necessità di complessi script di looping.
- Estrazione pronta per JavaScript: Poiché Automatio agisce come un vero browser, attende che i componenti di Next.js si idratino completamente, catturando prezzi finali e dettagli dell'itinerario con precisione ogni volta.
- Esportazione di dati strutturati: Trasforma automaticamente i dettagli complessi dei tour in formati CSV o JSON puliti e strutturati, pronti per l'uso immediato nei tuoi database interni o modelli AI.
Scraper Web No-Code per Thrillophilia
Alternative point-and-click allo scraping alimentato da IA
Diversi strumenti no-code come Browse.ai, Octoparse, Axiom e ParseHub possono aiutarti a fare scraping di Thrillophilia senza scrivere codice. Questi strumenti usano interfacce visive per selezionare i dati, anche se possono avere difficoltà con contenuti dinamici complessi o misure anti-bot.
Workflow Tipico con Strumenti No-Code
Sfide Comuni
Curva di apprendimento
Comprendere selettori e logica di estrazione richiede tempo
I selettori si rompono
Le modifiche al sito web possono rompere l'intero flusso di lavoro
Problemi con contenuti dinamici
I siti con molto JavaScript richiedono soluzioni complesse
Limitazioni CAPTCHA
La maggior parte degli strumenti richiede intervento manuale per i CAPTCHA
Blocco IP
Lo scraping aggressivo può portare al blocco del tuo IP
Scraper Web No-Code per Thrillophilia
Diversi strumenti no-code come Browse.ai, Octoparse, Axiom e ParseHub possono aiutarti a fare scraping di Thrillophilia senza scrivere codice. Questi strumenti usano interfacce visive per selezionare i dati, anche se possono avere difficoltà con contenuti dinamici complessi o misure anti-bot.
Workflow Tipico con Strumenti No-Code
- Installare l'estensione del browser o registrarsi sulla piattaforma
- Navigare verso il sito web target e aprire lo strumento
- Selezionare con point-and-click gli elementi dati da estrarre
- Configurare i selettori CSS per ogni campo dati
- Impostare le regole di paginazione per lo scraping di più pagine
- Gestire i CAPTCHA (spesso richiede risoluzione manuale)
- Configurare la pianificazione per le esecuzioni automatiche
- Esportare i dati in CSV, JSON o collegare tramite API
Sfide Comuni
- Curva di apprendimento: Comprendere selettori e logica di estrazione richiede tempo
- I selettori si rompono: Le modifiche al sito web possono rompere l'intero flusso di lavoro
- Problemi con contenuti dinamici: I siti con molto JavaScript richiedono soluzioni complesse
- Limitazioni CAPTCHA: La maggior parte degli strumenti richiede intervento manuale per i CAPTCHA
- Blocco IP: Lo scraping aggressivo può portare al blocco del tuo IP
Esempi di Codice
import requests
from bs4 import BeautifulSoup
# Thrillophilia usa Cloudflare, quindi le richieste standard potrebbero fallire senza intestazioni corrette
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
url = 'https://www.thrillophilia.com/destinations/bali/tours'
def scrape_thrill(url):
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# I selettori variano in base alle pagine di destinazione specifiche
tours = soup.select('.tour-card')
for tour in tours:
title = tour.find('h3').text.strip()
price = tour.select_one('.price-value').text.strip() if tour.select_one('.price-value') else 'N/D'
print(f'Tour: {title} | Prezzo: {price}')
except Exception as e:
print(f'Si è verificato un errore: {e}')
scrape_thrill(url)Quando Usare
Ideale per pagine HTML statiche con JavaScript minimo. Perfetto per blog, siti di notizie e pagine prodotto e-commerce semplici.
Vantaggi
- ●Esecuzione più veloce (senza overhead del browser)
- ●Consumo risorse minimo
- ●Facile da parallelizzare con asyncio
- ●Ottimo per API e pagine statiche
Limitazioni
- ●Non può eseguire JavaScript
- ●Fallisce su SPA e contenuti dinamici
- ●Può avere difficoltà con sistemi anti-bot complessi
Come Fare Scraping di Thrillophilia con Codice
Python + Requests
import requests
from bs4 import BeautifulSoup
# Thrillophilia usa Cloudflare, quindi le richieste standard potrebbero fallire senza intestazioni corrette
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
url = 'https://www.thrillophilia.com/destinations/bali/tours'
def scrape_thrill(url):
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# I selettori variano in base alle pagine di destinazione specifiche
tours = soup.select('.tour-card')
for tour in tours:
title = tour.find('h3').text.strip()
price = tour.select_one('.price-value').text.strip() if tour.select_one('.price-value') else 'N/D'
print(f'Tour: {title} | Prezzo: {price}')
except Exception as e:
print(f'Si è verificato un errore: {e}')
scrape_thrill(url)Python + Playwright
from playwright.sync_api import sync_playwright
def run():
with sync_playwright() as p:
# Lanciare con un profilo browser reale aiuta a bypassare i rilevamenti di base
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto('https://www.thrillophilia.com/destinations/egypt/tours', wait_until='networkidle')
# Attendi il caricamento dinamico delle schede dei tour
page.wait_for_selector('.tour-card')
tours = page.query_selector_all('.tour-card')
for tour in tours:
title = tour.query_selector('h3').inner_text()
print(f'Estratto: {title}')
browser.close()
run()Python + Scrapy
import scrapy
class ThrillSpider(scrapy.Spider):
name = 'thrillophilia'
start_urls = ['https://www.thrillophilia.com/destinations/japan/tours']
def parse(self, response):
for tour in response.css('.tour-card'):
yield {
'title': tour.css('h3::text').get(),
'price': tour.css('.current-price::text').get(),
'rating': tour.css('.rating-value::text').get()
}
# Gestione della paginazione
next_page = response.css('a.next-page::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.thrillophilia.com/destinations/maldives');
// Esegue lo script nel contesto del browser per estrarre i dati
const tours = await page.evaluate(() => {
const items = document.querySelectorAll('.tour-card');
return Array.from(items).map(item => ({
title: item.querySelector('h3')?.innerText,
price: item.querySelector('.price')?.innerText
}));
});
console.log(tours);
await browser.close();
})();Cosa Puoi Fare Con I Dati di Thrillophilia
Esplora applicazioni pratiche e insight dai dati di Thrillophilia.
Monitoraggio Dinamico dei Prezzi
Monitora i prezzi delle attività quotidianamente per adattare le strategie di prezzo competitive.
Come implementare:
- 1Estrai i prezzi dei tour quotidianamente per le destinazioni principali
- 2Memorizza i dati storici in un database SQL
- 3Imposta avvisi per cali di prezzo superiori al 15%
- 4Sincronizza con il CRM interno per aggiornare i tuoi prezzi
Usa Automatio per estrarre dati da Thrillophilia e costruire queste applicazioni senza scrivere codice.
Cosa Puoi Fare Con I Dati di Thrillophilia
- Monitoraggio Dinamico dei Prezzi
Monitora i prezzi delle attività quotidianamente per adattare le strategie di prezzo competitive.
- Estrai i prezzi dei tour quotidianamente per le destinazioni principali
- Memorizza i dati storici in un database SQL
- Imposta avvisi per cali di prezzo superiori al 15%
- Sincronizza con il CRM interno per aggiornare i tuoi prezzi
- Sentiment Analysis sulle Recensioni
Analizza migliaia di recensioni per comprendere i punti critici dei viaggiatori.
- Estrai tutti i testi delle recensioni e le valutazioni
- Applica model NLP per categorizzare il sentiment
- Identifica parole chiave specifiche relative a 'sicurezza' o 'ritardi'
- Genera report per il miglioramento del servizio
- Scoperta dei Trend negli Itinerari
Utilizza i dati degli itinerari per progettare nuovi pacchetti tour che seguano i trend del mercato.
- Estrai la suddivisione notte per notte dei tour più venduti
- Identifica i pattern comuni di hotel e attività
- Confronta la popolarità delle destinazioni in diverse regioni
- Crea nuovi prodotti basati su strutture di itinerari ad alte prestazioni
- Lead Gen per Attrezzatura da Viaggio
Identifica le attività popolari per indirizzare le vendite di attrezzatura a segmenti demografici specifici.
- Traccia i tipi di avventura più prenotati (es. trekking vs. lusso)
- Correla la popolarità delle attività con i trend stagionali
- Indirizza campagne di marketing per attrezzatura basandoti sui tag delle attività delle destinazioni
- Verifica degli Operatori Turistici
Monitora quali operatori ricevono costantemente valutazioni elevate sulla piattaforma.
- Estrai i nomi degli operatori e i loro punteggi medi di valutazione
- Traccia il volume di tour gestiti da ciascun operatore
- Valuta potenziali partner per la tua rete di agenzie di viaggio
Potenzia il tuo workflow con l'automazione AI
Automatio combina la potenza degli agenti AI, dell'automazione web e delle integrazioni intelligenti per aiutarti a fare di piu in meno tempo.
Consigli Pro per lo Scraping di Thrillophilia
Consigli esperti per estrarre con successo i dati da Thrillophilia.
Dare priorità ai proxy residenziali
Per evitare di essere segnalati dai sistemi di sicurezza di Thrillophilia, utilizza proxy residenziali di alta qualità che imitano il traffico reale degli utenti domestici piuttosto che IP di data center.
Estrarre lo script NEXT_DATA
Controlla il codice sorgente della pagina per un tag script contenente __NEXT_DATA__; spesso contiene un oggetto JSON completo con i dati della pagina, il cui parsing può essere molto più veloce.
Implementare ritardi casuali
Imposta tempi di attesa casuali tra le interazioni per simulare il comportamento di navigazione umano e ridurre la probabilità di attivare rate limits o sfide di sicurezza.
Gestire il lazy-load delle immagini
Molte immagini vengono caricate solo quando entrano nella viewport; assicurati che il tuo scraper scorra la pagina per catturare correttamente tutti gli URL delle foto dei tour.
Normalizzare valuta e prezzi
I prezzi possono variare in base alla posizione del tuo proxy. Estrai sempre il codice della valuta insieme al valore numerico per evitare incongruenze nei dati.
Testimonianze
Cosa dicono i nostri utenti
Unisciti a migliaia di utenti soddisfatti che hanno trasformato il loro workflow
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Correlati Web Scraping
Domande frequenti su Thrillophilia
Trova risposte alle domande comuni su Thrillophilia