Jak scrapować pakiety wycieczkowe i recenzje z Thrillophilia
Dowiedz się, jak scrapować Thrillophilia, aby wyodrębnić ceny pakietów wycieczkowych, plany podróży i recenzje klientów. Wysokiej jakości dane turystyczne do...
Wykryto ochronę przed botami
- Cloudflare
- Korporacyjny WAF i zarządzanie botami. Używa wyzwań JavaScript, CAPTCHA i analizy behawioralnej. Wymaga automatyzacji przeglądarki z ustawieniami stealth.
- Ograniczanie szybkości
- Ogranicza liczbę żądań na IP/sesję w czasie. Można obejść za pomocą rotacyjnych proxy, opóźnień żądań i rozproszonego scrapingu.
- Blokowanie IP
- Blokuje znane IP centrów danych i oznaczone adresy. Wymaga rezydencjalnych lub mobilnych proxy do skutecznego obejścia.
- Fingerprinting przeglądarki
- Identyfikuje boty po cechach przeglądarki: canvas, WebGL, czcionki, wtyczki. Wymaga spoofingu lub prawdziwych profili przeglądarki.
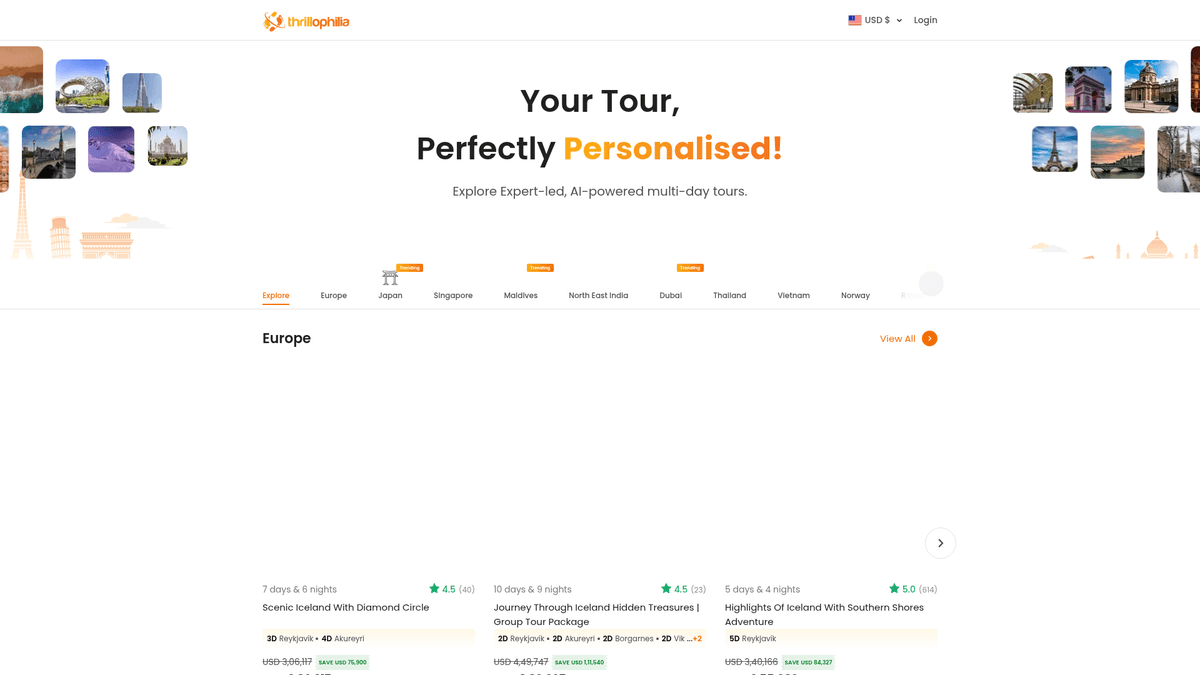
O Thrillophilia
Odkryj, co oferuje Thrillophilia i jakie cenne dane można wyodrębnić.
Wiodące miejsce dla doświadczeń podróżniczych
Thrillophilia to znacząca platforma podróżnicza i przygodowa z siedzibą w Indiach, która zapewnia prowadzone przez ekspertów, kompleksowe pakiety wycieczkowe na całym świecie. Specjalizuje się w kuratowanych doświadczeniach podróżniczych, od wypraw w Himalaje i wycieczek po dziedzictwie Radżastanu, po międzynarodowe wypady do Europy, Azji Południowo-Wschodniej i na Bliski Wschód.
Bogactwo danych i ich wartość
Platforma oferuje szczegółowe listy wielodniowych wycieczek, pakietów poślubnych i przygód grupowych. Oferty na Thrillophilia zawierają bogactwo ustrukturyzowanych danych, w tym konkretne plany podróży, szczegóły noclegów, ceny z rabatami, oceny użytkowników i opisowe recenzje. Informacje te są niezwykle cenne dla biur podróży i badaczy rynku.
Dlaczego jest to ważne dla analizy danych
Dla firm z sektora turystycznego scraping Thrillophilia zapewnia przewagę konkurencyjną. Monitorując wahania cen i nastroje klientów poprzez recenzje, firmy mogą optymalizować własne oferty i identyfikować pojawiające się trendy podróżnicze, zanim staną się one powszechne.
Dlaczego Scrapować Thrillophilia?
Odkryj wartość biznesową i przypadki użycia ekstrakcji danych z Thrillophilia.
Monitorowanie cen konkurencji dla podobnych pakietów wycieczkowych w czasie rzeczywistym
Analiza sentymentu klientów i jakości usług poprzez szczegółowe recenzje użytkowników
Agregowanie złożonych planów podróży do analizy globalnych trendów rynkowych
Identyfikacja popularnych i wschodzących kierunków podróży do planowania strategicznego
Śledzenie wiarygodności i wskaźników wydajności lokalnych organizatorów wycieczek
Zasilanie AI ustrukturyzowanymi danymi o planach podróży do automatycznego planowania wyjazdów
Wyzwania Scrapowania
Wyzwania techniczne, które możesz napotkać podczas scrapowania Thrillophilia.
Agresywne mechanizmy ochrony przed botami Cloudflare
Dynamiczne ładowanie treści przez frameworki Next.js i React
Złożone zagnieżdżone struktury HTML dla wielodniowych planów podróży
Rygorystyczne polityki rate limitingu przy zapytaniach o wysokiej częstotliwości
Fingerprinting przeglądarki wykrywający zautomatyzowane przeglądarki headless
Scrapuj Thrillophilia z AI
Bez kodowania. Wyodrębnij dane w kilka minut dzięki automatyzacji opartej na AI.
Jak to działa
Opisz, czego potrzebujesz
Powiedz AI, jakie dane chcesz wyodrębnić z Thrillophilia. Po prostu wpisz to w języku naturalnym — bez kodu czy selektorów.
AI wyodrębnia dane
Nasza sztuczna inteligencja nawiguje po Thrillophilia, obsługuje dynamiczną treść i wyodrębnia dokładnie to, o co prosiłeś.
Otrzymaj swoje dane
Otrzymaj czyste, ustrukturyzowane dane gotowe do eksportu jako CSV, JSON lub do bezpośredniego przesłania do twoich aplikacji.
Dlaczego warto używać AI do scrapowania
AI ułatwia scrapowanie Thrillophilia bez pisania kodu. Nasza platforma oparta na sztucznej inteligencji rozumie, jakich danych potrzebujesz — po prostu opisz je w języku naturalnym, a AI wyodrębni je automatycznie.
How to scrape with AI:
- Opisz, czego potrzebujesz: Powiedz AI, jakie dane chcesz wyodrębnić z Thrillophilia. Po prostu wpisz to w języku naturalnym — bez kodu czy selektorów.
- AI wyodrębnia dane: Nasza sztuczna inteligencja nawiguje po Thrillophilia, obsługuje dynamiczną treść i wyodrębnia dokładnie to, o co prosiłeś.
- Otrzymaj swoje dane: Otrzymaj czyste, ustrukturyzowane dane gotowe do eksportu jako CSV, JSON lub do bezpośredniego przesłania do twoich aplikacji.
Why use AI for scraping:
- Automatycznie omija wyrafinowane środki anti-bot, takie jak Cloudflare
- Interfejs no-code pozwala na budowanie scraperów turystycznych bez zasobów programistycznych
- Bez wysiłku obsługuje renderowanie JavaScript i dynamiczną treść
- Zaplanowane uruchomienia scrapingu umożliwiają automatyczne codzienne monitorowanie cen
- Bezpośrednia integracja z Google Sheets dla natychmiastowej wizualizacji danych
Scrapery No-Code dla Thrillophilia
Alternatywy point-and-click dla scrapingu opartego na AI
Różne narzędzia no-code jak Browse.ai, Octoparse, Axiom i ParseHub mogą pomóc w scrapowaniu Thrillophilia bez pisania kodu. Te narzędzia używają wizualnych interfejsów do wyboru danych, choć mogą mieć problemy ze złożoną dynamiczną zawartością lub zabezpieczeniami anti-bot.
Typowy Workflow z Narzędziami No-Code
Częste Wyzwania
Krzywa uczenia
Zrozumienie selektorów i logiki ekstrakcji wymaga czasu
Selektory się psują
Zmiany na stronie mogą zepsuć cały przepływ pracy
Problemy z dynamiczną treścią
Strony bogate w JavaScript wymagają złożonych obejść
Ograniczenia CAPTCHA
Większość narzędzi wymaga ręcznej interwencji przy CAPTCHA
Blokowanie IP
Agresywne scrapowanie może prowadzić do zablokowania IP
Scrapery No-Code dla Thrillophilia
Różne narzędzia no-code jak Browse.ai, Octoparse, Axiom i ParseHub mogą pomóc w scrapowaniu Thrillophilia bez pisania kodu. Te narzędzia używają wizualnych interfejsów do wyboru danych, choć mogą mieć problemy ze złożoną dynamiczną zawartością lub zabezpieczeniami anti-bot.
Typowy Workflow z Narzędziami No-Code
- Zainstaluj rozszerzenie przeglądarki lub zarejestruj się na platformie
- Przejdź do docelowej strony i otwórz narzędzie
- Wybierz elementy danych do wyodrębnienia metodą point-and-click
- Skonfiguruj selektory CSS dla każdego pola danych
- Ustaw reguły paginacji do scrapowania wielu stron
- Obsłuż CAPTCHA (często wymaga ręcznego rozwiązywania)
- Skonfiguruj harmonogram automatycznych uruchomień
- Eksportuj dane do CSV, JSON lub połącz przez API
Częste Wyzwania
- Krzywa uczenia: Zrozumienie selektorów i logiki ekstrakcji wymaga czasu
- Selektory się psują: Zmiany na stronie mogą zepsuć cały przepływ pracy
- Problemy z dynamiczną treścią: Strony bogate w JavaScript wymagają złożonych obejść
- Ograniczenia CAPTCHA: Większość narzędzi wymaga ręcznej interwencji przy CAPTCHA
- Blokowanie IP: Agresywne scrapowanie może prowadzić do zablokowania IP
Przykłady kodu
import requests
from bs4 import BeautifulSoup
# Thrillophilia używa Cloudflare, więc standardowe żądania mogą zawieść bez nagłówków lub zarządzania sesją
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
url = 'https://www.thrillophilia.com/destinations/bali/tours'
def scrape_thrill(url):
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Selektory różnią się w zależności od konkretnych stron docelowych
tours = soup.select('.tour-card')
for tour in tours:
title = tour.find('h3').text.strip()
price = tour.select_one('.price-value').text.strip() if tour.select_one('.price-value') else 'N/A'
print(f'Wycieczka: {title} | Cena: {price}')
except Exception as e:
print(f'Wystąpił błąd: {e}')
scrape_thrill(url)Kiedy Używać
Najlepsze dla statycznych stron HTML z minimalnym JavaScript. Idealne dla blogów, serwisów informacyjnych i prostych stron produktowych e-commerce.
Zalety
- ●Najszybsze wykonanie (bez narzutu przeglądarki)
- ●Najniższe zużycie zasobów
- ●Łatwe do zrównoleglenia z asyncio
- ●Świetne dla API i stron statycznych
Ograniczenia
- ●Nie może wykonywać JavaScript
- ●Zawodzi na SPA i dynamicznej zawartości
- ●Może mieć problemy ze złożonymi systemami anti-bot
Jak scrapować Thrillophilia za pomocą kodu
Python + Requests
import requests
from bs4 import BeautifulSoup
# Thrillophilia używa Cloudflare, więc standardowe żądania mogą zawieść bez nagłówków lub zarządzania sesją
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
url = 'https://www.thrillophilia.com/destinations/bali/tours'
def scrape_thrill(url):
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Selektory różnią się w zależności od konkretnych stron docelowych
tours = soup.select('.tour-card')
for tour in tours:
title = tour.find('h3').text.strip()
price = tour.select_one('.price-value').text.strip() if tour.select_one('.price-value') else 'N/A'
print(f'Wycieczka: {title} | Cena: {price}')
except Exception as e:
print(f'Wystąpił błąd: {e}')
scrape_thrill(url)Python + Playwright
from playwright.sync_api import sync_playwright
def run():
with sync_playwright() as p:
# Uruchomienie z realnym profilem przeglądarki pomaga ominąć podstawowe wykrywanie
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto('https://www.thrillophilia.com/destinations/egypt/tours', wait_until='networkidle')
# Czekaj na dynamiczne załadowanie kart wycieczek
page.wait_for_selector('.tour-card')
tours = page.query_selector_all('.tour-card')
for tour in tours:
title = tour.query_selector('h3').inner_text()
print(f'Wyodrębniono: {title}')
browser.close()
run()Python + Scrapy
import scrapy
class ThrillSpider(scrapy.Spider):
name = 'thrillophilia'
start_urls = ['https://www.thrillophilia.com/destinations/japan/tours']
def parse(self, response):
for tour in response.css('.tour-card'):
yield {
'title': tour.css('h3::text').get(),
'price': tour.css('.current-price::text').get(),
'rating': tour.css('.rating-value::text').get()
}
# Obsługa paginacji
next_page = response.css('a.next-page::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.thrillophilia.com/destinations/maldives');
// Wykonaj skrypt w kontekście przeglądarki, aby wyodrębnić dane
const tours = await page.evaluate(() => {
const items = document.querySelectorAll('.tour-card');
return Array.from(items).map(item => ({
title: item.querySelector('h3')?.innerText,
price: item.querySelector('.price')?.innerText
}));
});
console.log(tours);
await browser.close();
})();Co Możesz Zrobić Z Danymi Thrillophilia
Poznaj praktyczne zastosowania i wnioski z danych Thrillophilia.
Dynamiczne monitorowanie cen
Monitoruj ceny aktywności codziennie, aby dostosowywać konkurencyjne strategie cenowe.
Jak wdrożyć:
- 1Codziennie scrapuj ceny wycieczek dla najpopularniejszych kierunków
- 2Przechowuj dane historyczne w bazie danych SQL
- 3Ustaw alerty dla spadków cen powyżej 15%
- 4Synchronizuj z wewnętrznym systemem CRM, aby aktualizować własne ceny
Użyj Automatio do wyodrębnienia danych z Thrillophilia i budowania tych aplikacji bez pisania kodu.
Co Możesz Zrobić Z Danymi Thrillophilia
- Dynamiczne monitorowanie cen
Monitoruj ceny aktywności codziennie, aby dostosowywać konkurencyjne strategie cenowe.
- Codziennie scrapuj ceny wycieczek dla najpopularniejszych kierunków
- Przechowuj dane historyczne w bazie danych SQL
- Ustaw alerty dla spadków cen powyżej 15%
- Synchronizuj z wewnętrznym systemem CRM, aby aktualizować własne ceny
- Analiza sentymentu recenzji
Analizuj tysiące recenzji, aby zrozumieć bolączki podróżnych.
- Wyodrębnij wszystkie teksty recenzji i oceny
- Zastosuj modele NLP, aby skategoryzować sentyment
- Zidentyfikuj konkretne słowa kluczowe związane z „bezpieczeństwem” lub „opóźnieniami”
- Generuj raporty w celu poprawy jakości usług
- Odkrywanie trendów w planach podróży
Wykorzystuj dane o planach podróży do projektowania nowych pakietów wycieczkowych zgodnych z trendami rynkowymi.
- Scrapuj szczegółowe plany najpopularniejszych wycieczek dzień po dniu
- Zidentyfikuj powszechne wzorce hoteli i aktywności
- Porównaj popularność kierunków w różnych regionach
- Projektuj nowe produkty w oparciu o wysokowydajne struktury planów podróży
- Generowanie leadów dla sprzętu turystycznego
Identyfikuj popularne aktywności, aby kierować sprzedaż sprzętu do konkretnych grup demograficznych.
- Śledź najczęściej rezerwowane rodzaje przygód (np. trekking vs. luksus)
- Koreluj popularność aktywności z trendami sezonowymi
- Kieruj kampanie marketingowe sprzętu na podstawie tagów aktywności w danym miejscu
- Weryfikacja organizatorów wycieczek
Monitoruj, którzy operatorzy są stale wysoko oceniani na platformie.
- Wyodrębnij nazwy operatorów i ich średnie oceny
- Śledź wolumen wycieczek obsługiwanych przez każdego operatora
- Weryfikuj potencjalnych partnerów dla własnej sieci biur podróży
Przyspiesz swoj workflow z automatyzacja AI
Automatio laczy moc agentow AI, automatyzacji web i inteligentnych integracji, aby pomoc Ci osiagnac wiecej w krotszym czasie.
Profesjonalne Porady dla Scrapowania Thrillophilia
Porady ekspertów dotyczące skutecznej ekstrakcji danych z Thrillophilia.
Używaj wysokiej jakości mieszkaniowych serwerów proxy, aby skuteczniej omijać ochronę Cloudflare
Implementuj losowe interwały uśpienia (sleep) między 5 a 15 sekund, aby naśladować zachowanie człowieka
Regularnie rotuj ciągi User-Agent, aby zapobiec wykrywaniu na podstawie fingerprintingu urządzenia
Zbadaj tag skryptu __NEXT_DATA__, który często zawiera ustrukturyzowany JSON strony
Planuj scraping poza godzinami szczytu, aby uniknąć restrykcyjnego limitowania zapytań (rate limiting)
Oczyszczaj dane o planach podróży, usuwając tagi HTML i normalizując białe znaki
Opinie
Co mowia nasi uzytkownicy
Dolacz do tysiecy zadowolonych uzytkownikow, ktorzy przeksztalcili swoj workflow
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Powiazane Web Scraping
Często Zadawane Pytania o Thrillophilia
Znajdź odpowiedzi na częste pytania o Thrillophilia