Как парсить туры и отзывы Thrillophilia
Узнайте, как парсить Thrillophilia для извлечения цен на туры, маршрутов и отзывов клиентов. Качественные данные о путешествиях для анализа рынка.
Обнаружена защита от ботов
- Cloudflare
- Корпоративный WAF и управление ботами. Использует JavaScript-проверки, CAPTCHA и анализ поведения. Требует автоматизации браузера со скрытыми настройками.
- Ограничение частоты запросов
- Ограничивает количество запросов на IP/сессию за определённое время. Можно обойти с помощью ротации прокси, задержек запросов и распределённого скрапинга.
- Блокировка IP
- Блокирует известные IP дата-центров и отмеченные адреса. Требует резидентных или мобильных прокси для эффективного обхода.
- Цифровой отпечаток браузера
- Идентифицирует ботов по характеристикам браузера: canvas, WebGL, шрифты, плагины. Требует подмены или реальных профилей браузера.
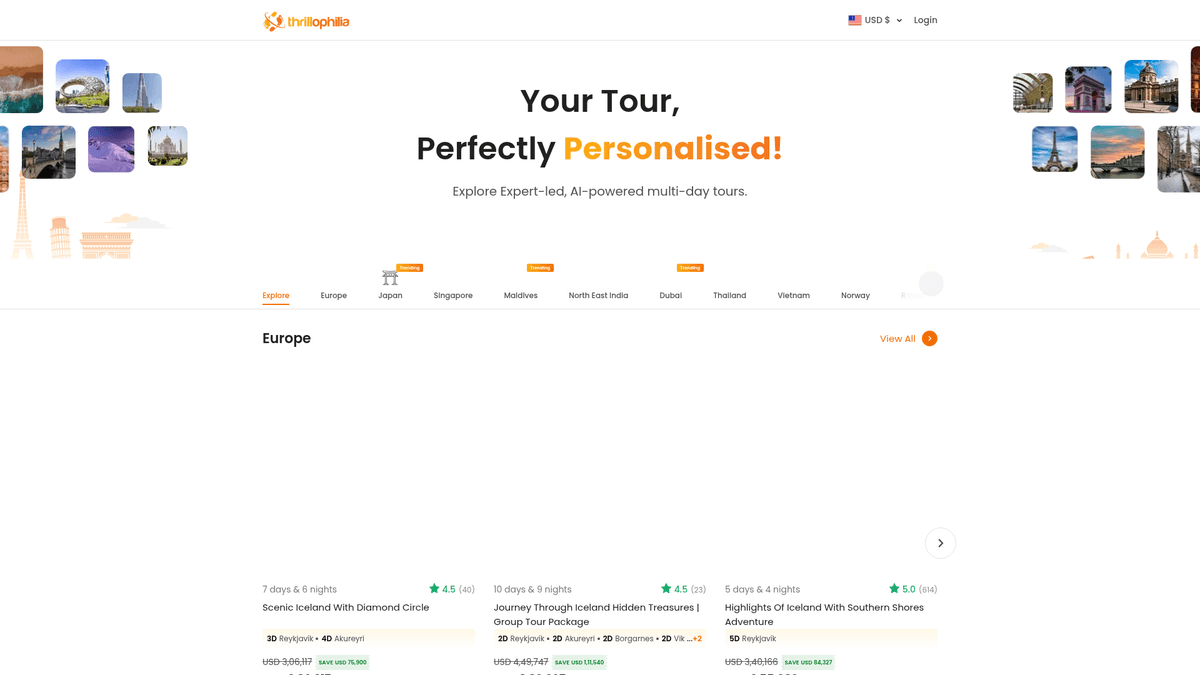
О Thrillophilia
Узнайте, что предлагает Thrillophilia и какие ценные данные можно извлечь.
Ведущая платформа для планирования путешествий
Thrillophilia — это крупнейшая индийская платформа для путешествий и приключений, предлагающая комплексные туры под руководством экспертов по всему миру. Она специализируется на кураторских программах: от гималайских экспедиций и культурных туров по Раджастану до международных поездок в Европу, Юго-Восточную Азию и на Ближний Восток.
Полнота и ценность данных
Платформа содержит подробные списки многодневных туров, свадебных пакетов и групповых приключений. Объявления на Thrillophilia богаты структурированной информацией, включая конкретные маршруты, детали проживания по ночам, цены со скидками, пользовательские рейтинги и подробные отзывы. Эта информация представляет огромную ценность для турагентств и исследователей рынка.
Почему это важно для анализа данных
Для компаний в сфере туризма парсинг Thrillophilia обеспечивает конкурентное преимущество. Отслеживая колебания цен и настроения клиентов через отзывы, компании могут оптимизировать собственные предложения и выявлять новые тренды в путешествиях еще до того, как они станут массовыми.
Зачем Парсить Thrillophilia?
Узнайте о бизнес-ценности и сценариях использования извлечения данных из Thrillophilia.
Мониторинг цен конкурентов на аналогичные турпакеты в режиме реального времени
Анализ удовлетворенности клиентов и качества обслуживания через детальные отзывы
Агрегация сложных маршрутов для анализа глобальных рыночных трендов
Выявление популярных и развивающихся туристических направлений для стратегического планирования
Отслеживание показателей надежности и эффективности работы локальных туроператоров
Наполнение AI-моделей структурированными данными о маршрутах для автоматизированного планирования путешествий
Проблемы При Парсинге
Технические проблемы, с которыми вы можете столкнуться при парсинге Thrillophilia.
Агрессивные механизмы защиты от ботов Cloudflare
Динамическая загрузка контента через Next.js и фреймворк React
Сложные вложенные структуры HTML для многодневных маршрутов
Строгая политика rate limiting при высокой частоте запросов
Идентификация браузера (fingerprinting), определяющая автоматизированные headless browsers
Скрапинг Thrillophilia с помощью ИИ
Код не нужен. Извлекайте данные за минуты с автоматизацией на базе ИИ.
Как это работает
Опишите, что вам нужно
Расскажите ИИ, какие данные вы хотите извлечь из Thrillophilia. Просто напишите на обычном языке — без кода и селекторов.
ИИ извлекает данные
Наш искусственный интеллект навигирует по Thrillophilia, обрабатывает динамический контент и извлекает именно то, что вы запросили.
Получите ваши данные
Получите чистые, структурированные данные, готовые к экспорту в CSV, JSON или отправке напрямую в ваши приложения.
Почему стоит использовать ИИ для скрапинга
ИИ упрощает скрапинг Thrillophilia без написания кода. Наша платформа на базе искусственного интеллекта понимает, какие данные вам нужны — просто опишите их на обычном языке, и ИИ извлечёт их автоматически.
How to scrape with AI:
- Опишите, что вам нужно: Расскажите ИИ, какие данные вы хотите извлечь из Thrillophilia. Просто напишите на обычном языке — без кода и селекторов.
- ИИ извлекает данные: Наш искусственный интеллект навигирует по Thrillophilia, обрабатывает динамический контент и извлекает именно то, что вы запросили.
- Получите ваши данные: Получите чистые, структурированные данные, готовые к экспорту в CSV, JSON или отправке напрямую в ваши приложения.
Why use AI for scraping:
- Автоматически обходит сложные системы защиты, такие как Cloudflare
- Интерфейс No-code позволяет создавать скрейперы без привлечения разработчиков
- Легко справляется с рендерингом JavaScript и динамическим контентом
- Запуск парсинга по расписанию позволяет автоматизировать ежедневный мониторинг цен
- Прямая интеграция с Google Sheets для мгновенной визуализации данных
No-Code Парсеры для Thrillophilia
Point-and-click альтернативы AI-парсингу
Несколько no-code инструментов, таких как Browse.ai, Octoparse, Axiom и ParseHub, могут помочь парсить Thrillophilia без написания кода. Эти инструменты используют визуальные интерфейсы для выбора данных, хотя могут иметь проблемы со сложным динамическим контентом или антибот-защитой.
Типичный Рабочий Процесс с No-Code Инструментами
Частые Проблемы
Кривая обучения
Понимание селекторов и логики извлечения требует времени
Селекторы ломаются
Изменения на сайте могут сломать весь рабочий процесс
Проблемы с динамическим контентом
Сайты с большим количеством JavaScript требуют сложных обходных путей
Ограничения CAPTCHA
Большинство инструментов требуют ручного вмешательства для CAPTCHA
Блокировка IP
Агрессивный парсинг может привести к блокировке вашего IP
No-Code Парсеры для Thrillophilia
Несколько no-code инструментов, таких как Browse.ai, Octoparse, Axiom и ParseHub, могут помочь парсить Thrillophilia без написания кода. Эти инструменты используют визуальные интерфейсы для выбора данных, хотя могут иметь проблемы со сложным динамическим контентом или антибот-защитой.
Типичный Рабочий Процесс с No-Code Инструментами
- Установить расширение браузера или зарегистрироваться на платформе
- Перейти на целевой сайт и открыть инструмент
- Выбрать элементы данных для извлечения методом point-and-click
- Настроить CSS-селекторы для каждого поля данных
- Настроить правила пагинации для парсинга нескольких страниц
- Обработать CAPTCHA (часто требуется ручное решение)
- Настроить расписание для автоматических запусков
- Экспортировать данные в CSV, JSON или подключить через API
Частые Проблемы
- Кривая обучения: Понимание селекторов и логики извлечения требует времени
- Селекторы ломаются: Изменения на сайте могут сломать весь рабочий процесс
- Проблемы с динамическим контентом: Сайты с большим количеством JavaScript требуют сложных обходных путей
- Ограничения CAPTCHA: Большинство инструментов требуют ручного вмешательства для CAPTCHA
- Блокировка IP: Агрессивный парсинг может привести к блокировке вашего IP
Примеры кода
import requests
from bs4 import BeautifulSoup
# Thrillophilia использует Cloudflare, поэтому стандартные requests могут не сработать без правильных заголовков
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
url = 'https://www.thrillophilia.com/destinations/bali/tours'
def scrape_thrill(url):
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Селекторы могут меняться в зависимости от страницы направления
tours = soup.select('.tour-card')
for tour in tours:
title = tour.find('h3').text.strip()
price = tour.select_one('.price-value').text.strip() if tour.select_one('.price-value') else 'N/A'
print(f'Тур: {title} | Цена: {price}')
except Exception as e:
print(f'Произошла ошибка: {e}')
scrape_thrill(url)Когда Использовать
Лучше всего для статических HTML-страниц с минимальным JavaScript. Идеально для блогов, новостных сайтов и простых страниц товаров электронной коммерции.
Преимущества
- ●Самое быстрое выполнение (без нагрузки браузера)
- ●Минимальное потребление ресурсов
- ●Легко распараллелить с asyncio
- ●Отлично для API и статических страниц
Ограничения
- ●Не может выполнять JavaScript
- ●Не работает на SPA и динамическом контенте
- ●Может иметь проблемы со сложными антибот-системами
Как парсить Thrillophilia с помощью кода
Python + Requests
import requests
from bs4 import BeautifulSoup
# Thrillophilia использует Cloudflare, поэтому стандартные requests могут не сработать без правильных заголовков
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
url = 'https://www.thrillophilia.com/destinations/bali/tours'
def scrape_thrill(url):
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Селекторы могут меняться в зависимости от страницы направления
tours = soup.select('.tour-card')
for tour in tours:
title = tour.find('h3').text.strip()
price = tour.select_one('.price-value').text.strip() if tour.select_one('.price-value') else 'N/A'
print(f'Тур: {title} | Цена: {price}')
except Exception as e:
print(f'Произошла ошибка: {e}')
scrape_thrill(url)Python + Playwright
from playwright.sync_api import sync_playwright
def run():
with sync_playwright() as p:
# Запуск с профилем реального браузера помогает обойти базовое обнаружение
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto('https://www.thrillophilia.com/destinations/egypt/tours', wait_until='networkidle')
# Ожидание динамической загрузки карточек туров
page.wait_for_selector('.tour-card')
tours = page.query_selector_all('.tour-card')
for tour in tours:
title = tour.query_selector('h3').inner_text()
print(f'Извлечено: {title}')
browser.close()
run()Python + Scrapy
import scrapy
class ThrillSpider(scrapy.Spider):
name = 'thrillophilia'
start_urls = ['https://www.thrillophilia.com/destinations/japan/tours']
def parse(self, response):
# Извлечение данных из карточек туров
for tour in response.css('.tour-card'):
yield {
'title': tour.css('h3::text').get(),
'price': tour.css('.current-price::text').get(),
'rating': tour.css('.rating-value::text').get()
}
# Обработка пагинации
next_page = response.css('a.next-page::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.thrillophilia.com/destinations/maldives');
// Выполнение скрипта в контексте браузера для извлечения данных
const tours = await page.evaluate(() => {
const items = document.querySelectorAll('.tour-card');
return Array.from(items).map(item => ({
title: item.querySelector('h3')?.innerText,
price: item.querySelector('.price')?.innerText
}));
});
console.log(tours);
await browser.close();
})();Что Можно Делать С Данными Thrillophilia
Изучите практические применения и инсайты из данных Thrillophilia.
Динамический мониторинг цен
Ежедневно отслеживайте цены на активности для корректировки конкурентных стратегий ценообразования.
Как реализовать:
- 1Ежедневно парсить цены на туры по популярным направлениям
- 2Сохранять исторические данные в SQL базу данных
- 3Настроить оповещения о падении цен более чем на 15%
- 4Синхронизировать данные с внутренней CRM для обновления собственного ценообразования
Используйте Automatio для извлечения данных из Thrillophilia и создания этих приложений без написания кода.
Что Можно Делать С Данными Thrillophilia
- Динамический мониторинг цен
Ежедневно отслеживайте цены на активности для корректировки конкурентных стратегий ценообразования.
- Ежедневно парсить цены на туры по популярным направлениям
- Сохранять исторические данные в SQL базу данных
- Настроить оповещения о падении цен более чем на 15%
- Синхронизировать данные с внутренней CRM для обновления собственного ценообразования
- Анализ тональности отзывов
Анализируйте тысячи отзывов, чтобы понять болевые точки путешественников.
- Извлечь все тексты отзывов и рейтинги
- Использовать NLP модели для категоризации тональности
- Выявить ключевые слова, связанные с «безопасностью» или «задержками»
- Генерировать отчеты для улучшения качества обслуживания
- Поиск трендов в маршрутах
Используйте данные о маршрутах для проектирования новых турпакетов, соответствующих рыночным трендам.
- Парсить детальные маршруты (по дням) самых продаваемых туров
- Выявить общие закономерности в выборе отелей и активностей
- Сравнить популярность направлений в разных регионах
- Разрабатывать новые продукты на основе успешных структур маршрутов
- Лидогенерация для туристического снаряжения
Определяйте популярные активности для таргетированных продаж оборудования конкретным демографическим группам.
- Отслеживать наиболее бронируемые типы приключений (например, треккинг против люкса)
- Сопоставлять популярность активностей с сезонными трендами
- Таргетировать маркетинговые кампании снаряжения на основе тегов активностей дестинации
- Верификация туроператоров
Контролируйте, какие операторы стабильно получают высокие оценки на платформе.
- Извлекать имена операторов и их средние рейтинги
- Отслеживать объем туров, обрабатываемых каждым оператором
- Проверять потенциальных партнеров для собственной сети турагентств
Улучшите свой рабочий процесс с ИИ-Автоматизацией
Automatio объединяет мощь ИИ-агентов, веб-автоматизации и умных интеграций, чтобы помочь вам достигать большего за меньшее время.
Советы Профессионала По Парсингу Thrillophilia
Экспертные советы для успешного извлечения данных из Thrillophilia.
Используйте качественные резидентные прокси для более эффективного обхода защиты Cloudflare
Настройте случайные интервалы ожидания (sleep) от 5 до 15 секунд для имитации действий реального пользователя
Регулярно меняйте строку User-Agent, чтобы предотвратить идентификацию по отпечатку устройства (fingerprinting)
Изучайте тег скрипта __NEXT_DATA__, который часто содержит структурированный JSON всей страницы
Планируйте парсинг в часы минимальной нагрузки, чтобы избежать жесткого ограничения частоты запросов (rate limiting)
Очищайте данные о маршрутах, удаляя HTML-теги и нормализуя пробелы
Отзывы
Что Говорят Наши Пользователи
Присоединяйтесь к тысячам довольных пользователей, которые трансформировали свой рабочий процесс
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Похожие Web Scraping
Часто задаваемые вопросы о Thrillophilia
Найдите ответы на частые вопросы о Thrillophilia