Як скрейпити GOV.UK | Посібник із веб-скрейпінгу уряду Великої Британії
Вичерпний посібник зі скрейпінгу GOV.UK для урядових інструкцій, оновлень політики та офіційної статистики. Навчіться витягувати цінні дані публічного сектору.
Виявлено захист від ботів
- Обмеження частоти запитів
- Обмежує кількість запитів на IP/сесію за час. Можна обійти за допомогою ротації проксі, затримок запитів та розподіленого скрапінгу.
- User-Agent Filtering
- Блокування IP
- Блокує відомі IP дата-центрів та позначені адреси. Потребує резидентних або мобільних проксі для ефективного обходу.
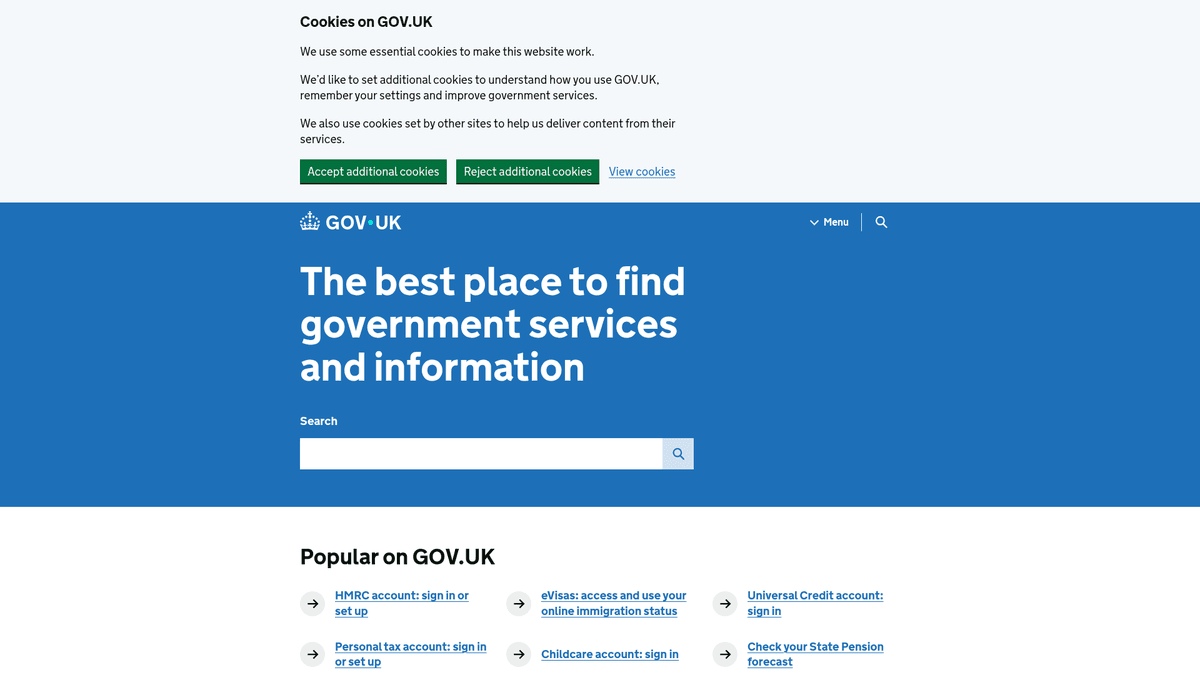
Про GOV.UK
Дізнайтеся, що пропонує GOV.UK та які цінні дані можна витягнути.
GOV.UK — це центральний цифровий портал уряду Сполученого Королівства, що забезпечує єдину точку доступу до послуг та інформації всіх міністерств і відомств. Створений Government Digital Service (GDS), він замінив сотні окремих сайтів відомств єдиним, зручним інтерфейсом, розробленим для прозорості та ефективності.
Платформа містить величезне сховище даних, включаючи законодавчі інструкції, офіційну статистику, стратегічні документи та повідомлення про закупівлі. Оскільки уряд Великої Британії дотримується політики «відкритих даних за замовчуванням», більшість інформації на GOV.UK публікується під ліцензією Open Government Licence, що робить її скарбницею для дослідників, юридичних фірм та бізнесу.
Скрейпінг GOV.UK є надзвичайно цінним для моніторингу регуляторних змін, відстеження економічних показників та збору конкурентної розвідки з оголошень про публічні тендери. Організації використовують ці дані для автоматизації процесів compliance та випередження політичних подій, що впливають на їхні галузі.
Чому Варто Парсити GOV.UK?
Дізнайтеся про бізнес-цінність та сценарії використання для витягування даних з GOV.UK.
Моніторинг оновлень регуляторної відповідності
Відстеження змін у політиці в режимі реального часу
Агрегація економічних та статистичних даних
Пошук можливостей для публічних тендерів та контрактів
Архівування юридичних та історичних документів
Проведення академічних соціально-економічних досліджень
Виклики Парсингу
Технічні виклики, з якими ви можете зіткнутися при парсингу GOV.UK.
Глибоко вкладена ієрархічна структура сторінок
Великий обсяг документів та PDF-вкладень
Суворий rate limiting
3000 запитів на 5 хвилин
Незначні відмінності в макетах різних відомств
Скрапінг GOV.UK за допомогою ШІ
Без коду. Витягуйте дані за лічені хвилини з автоматизацією на базі ШІ.
Як це працює
Опишіть, що вам потрібно
Скажіть ШІ, які дані ви хочете витягнути з GOV.UK. Просто напишіть звичайною мовою — без коду чи селекторів.
ШІ витягує дані
Наш штучний інтелект навігує по GOV.UK, обробляє динамічний контент і витягує саме те, що ви запросили.
Отримайте свої дані
Отримайте чисті, структуровані дані, готові до експорту в CSV, JSON або відправки безпосередньо у ваші додатки.
Чому варто використовувати ШІ для скрапінгу
ШІ спрощує скрапінг GOV.UK без написання коду. Наша платформа на базі штучного інтелекту розуміє, які дані вам потрібні — просто опишіть їх звичайною мовою, і ШІ витягне їх автоматично.
How to scrape with AI:
- Опишіть, що вам потрібно: Скажіть ШІ, які дані ви хочете витягнути з GOV.UK. Просто напишіть звичайною мовою — без коду чи селекторів.
- ШІ витягує дані: Наш штучний інтелект навігує по GOV.UK, обробляє динамічний контент і витягує саме те, що ви запросили.
- Отримайте свої дані: Отримайте чисті, структуровані дані, готові до експорту в CSV, JSON або відправки безпосередньо у ваші додатки.
Why use AI for scraping:
- Конфігурація без коду для складної навігації
- Заплановані запуски для моніторингу змін у політиці
- Прямий експорт у Google Sheets або CSV
- Автоматичне витягування прихованих посилань на документи
No-code веб-парсери для GOV.UK
Альтернативи point-and-click до AI-парсингу
Кілька no-code інструментів, таких як Browse.ai, Octoparse, Axiom та ParseHub, можуть допомогти вам парсити GOV.UK без написання коду. Ці інструменти зазвичай використовують візуальні інтерфейси для вибору даних, хоча можуть мати проблеми зі складним динамічним контентом чи anti-bot заходами.
Типовий робочий процес з no-code інструментами
Типові виклики
Крива навчання
Розуміння селекторів та логіки вилучення потребує часу
Селектори ламаються
Зміни на вебсайті можуть зламати весь робочий процес
Проблеми з динамічним контентом
Сайти з великою кількістю JavaScript потребують складних рішень
Обмеження CAPTCHA
Більшість інструментів потребує ручного втручання для CAPTCHA
Блокування IP
Агресивний парсинг може призвести до блокування вашої IP
No-code веб-парсери для GOV.UK
Кілька no-code інструментів, таких як Browse.ai, Octoparse, Axiom та ParseHub, можуть допомогти вам парсити GOV.UK без написання коду. Ці інструменти зазвичай використовують візуальні інтерфейси для вибору даних, хоча можуть мати проблеми зі складним динамічним контентом чи anti-bot заходами.
Типовий робочий процес з no-code інструментами
- Встановіть розширення браузера або зареєструйтесь на платформі
- Перейдіть на цільовий вебсайт і відкрийте інструмент
- Виберіть елементи даних для вилучення методом point-and-click
- Налаштуйте CSS-селектори для кожного поля даних
- Налаштуйте правила пагінації для парсингу кількох сторінок
- Обробіть CAPTCHA (часто потрібне ручне розв'язання)
- Налаштуйте розклад для автоматичних запусків
- Експортуйте дані в CSV, JSON або підключіть через API
Типові виклики
- Крива навчання: Розуміння селекторів та логіки вилучення потребує часу
- Селектори ламаються: Зміни на вебсайті можуть зламати весь робочий процес
- Проблеми з динамічним контентом: Сайти з великою кількістю JavaScript потребують складних рішень
- Обмеження CAPTCHA: Більшість інструментів потребує ручного втручання для CAPTCHA
- Блокування IP: Агресивний парсинг може призвести до блокування вашої IP
Приклади коду
import requests
from bs4 import BeautifulSoup
# PRO TIP: Додайте .json до багатьох URL GOV.UK для отримання вихідних даних
url = 'https://www.gov.uk/search/news-and-communications'
headers = {'User-Agent': 'ResearchBot/1.0 (contact@example.com)'}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
for item in soup.select('.gem-c-document-list__item'):
title = item.select_one('.gem-c-document-list__item-title').text.strip()
link = item.select_one('a')['href']
print(f'Update: {title} | https://www.gov.uk{link}')
except Exception as e:
print(f'Error: {e}')Коли використовувати
Найкраще для статичних HTML-сторінок з мінімумом JavaScript. Ідеально для блогів, новинних сайтів та простих сторінок товарів e-commerce.
Переваги
- ●Найшвидше виконання (без навантаження браузера)
- ●Найменше споживання ресурсів
- ●Легко розпаралелити з asyncio
- ●Чудово для API та статичних сторінок
Обмеження
- ●Не може виконувати JavaScript
- ●Не працює на SPA та динамічному контенті
- ●Може мати проблеми зі складними anti-bot системами
Як парсити GOV.UK за допомогою коду
Python + Requests
import requests
from bs4 import BeautifulSoup
# PRO TIP: Додайте .json до багатьох URL GOV.UK для отримання вихідних даних
url = 'https://www.gov.uk/search/news-and-communications'
headers = {'User-Agent': 'ResearchBot/1.0 (contact@example.com)'}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
for item in soup.select('.gem-c-document-list__item'):
title = item.select_one('.gem-c-document-list__item-title').text.strip()
link = item.select_one('a')['href']
print(f'Update: {title} | https://www.gov.uk{link}')
except Exception as e:
print(f'Error: {e}')Python + Playwright
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
try:
page.goto('https://www.gov.uk/search/all?keywords=data+protection')
page.wait_for_selector('.gem-c-document-list__item')
titles = page.locator('.gem-c-document-list__item-title').all_text_contents()
for t in titles:
print(f'Extracted: {t.strip()}')
finally:
browser.close()Python + Scrapy
import scrapy
class GovSpider(scrapy.Spider):
name = 'gov_spider'
start_urls = ['https://www.gov.uk/search/news-and-communications']
def parse(self, response):
for article in response.css('.gem-c-document-list__item'):
yield {
'title': article.css('.gem-c-document-list__item-title::text').get().strip(),
'link': response.urljoin(article.css('a::attr(href)').get())
}
next_page = response.css('a[rel="next"]::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
try {
await page.goto('https://www.gov.uk/search/news-and-communications', { waitUntil: 'networkidle2' });
const results = await page.evaluate(() =>
Array.from(document.querySelectorAll('.gem-c-document-list__item-title'))
.map(el => el.innerText.trim())
);
console.log(results);
} finally {
await browser.close();
}
})();Що Можна Робити З Даними GOV.UK
Досліджуйте практичні застосування та інсайти з даних GOV.UK.
Система регуляторних сповіщень
Юридичні відділи та команди з compliance можуть моніторити конкретні категорії інструкцій, щоб негайно виявляти зміни в законодавстві.
Як реалізувати:
- 1Щоденно скрейпити розділ 'Guidance and Regulation'.
- 2Витягувати текст документів та мітки часу останнього оновлення.
- 3Порівнювати контент із попередніми версіями для виявлення відмінностей.
- 4Надсилати автоматичні сповіщення відповідним внутрішнім стейкхолдерам.
Використовуйте Automatio для витягування даних з GOV.UK та створення цих додатків без написання коду.
Що Можна Робити З Даними GOV.UK
- Система регуляторних сповіщень
Юридичні відділи та команди з compliance можуть моніторити конкретні категорії інструкцій, щоб негайно виявляти зміни в законодавстві.
- Щоденно скрейпити розділ 'Guidance and Regulation'.
- Витягувати текст документів та мітки часу останнього оновлення.
- Порівнювати контент із попередніми версіями для виявлення відмінностей.
- Надсилати автоматичні сповіщення відповідним внутрішнім стейкхолдерам.
- Трекер тендерних можливостей
Команди з продажу можуть скрейпити повідомлення про закупівлі, щоб знаходити нові можливості для державних контрактів.
- Націлитися на категорію пошуку 'Procurement' на GOV.UK.
- Скрейпити дедлайни, контактні email та вартості контрактів.
- Фільтрувати результати за ключовими словами галузі, що стосуються вашого бізнесу.
- Імпортувати ліди безпосередньо в CRM для подальшої роботи.
- Аналіз економічних трендів
Економісти можуть агрегувати статистичні випуски для лонгітюдних досліджень показників Великої Британії.
- Ідентифікувати URL серій статистичних даних.
- Скрейпити прямі посилання на файли CSV або Excel.
- Завантажувати та очищувати набори даних за допомогою автоматизованих скриптів.
- Об'єднувати дані в централізовану базу даних для візуалізації.
- Архів державної політики
Журналісти та дослідники можуть створити архів офіційних урядових оголошень із можливістю пошуку.
- Безперервно скрейпити розділ 'News and Communications'.
- Витягувати заголовки, основний текст і теги відомств.
- Індексувати дані в пошуковій платформі, такій як Elasticsearch.
- Аналізувати тональність та частоту використання специфічних політичних ключових слів.
- Автоматизовані боти-консультанти
Некомерційні організації можуть використовувати офіційні інструкції для створення чат-ботів, які допомагають громадянам знайти інформацію про пільги.
- Скрейпити сторінки з інструкціями щодо пільг та житла.
- Перетворювати витягнутий текст у vector базу даних для RAG (Retrieval-Augmented Generation).
- Налаштувати тригер для оновлення бази даних при зміні контенту на GOV.UK.
- Надавати точні відповіді на запити користувачів у режимі реального часу.
- Пошуковик грантів
Освітні установи можуть знаходити гранти та можливості фінансування для дослідницьких проектів.
- Скрейпити категорію фінансування 'Education, Training and Skills'.
- Витягувати критерії відповідності та терміни подачі заявок.
- Категоризувати гранти за відомствами та обсягами фінансування.
- Автоматизувати щотижневі email-звіти для викладачів.
Прискорте вашу роботу з AI-автоматизацією
Automatio поєднує силу AI-агентів, веб-автоматизації та розумних інтеграцій, щоб допомогти вам досягти більшого за менший час.
Професійні Поради Щодо Парсингу GOV.UK
Експертні поради для успішного витягування даних з GOV.UK.
Додавайте '.json' майже до будь-якої URL-адреси GOV.UK, щоб отримати вихідні метадані без HTML-парсингу.
Ідентифікуйте елементи за допомогою CSS-класів, що починаються з 'gem-c-', оскільки вони є частиною стандартної GDS Design System.
Встановіть описовий рядок User-Agent, що містить вашу адресу електронної пошти, щоб GDS міг зв'язатися з вами, якщо ваш бот спричинить проблеми.
Дотримуйтеся ліміту швидкості (rate limit) у 3000 запитів на 5 хвилин, щоб уникнути тимчасових IP-блокувань.
Зосередьтеся на сторінках 'Search' для масштабного збору даних, оскільки вони містять чисті пагіновані списки документів.
Перевіряйте мітку часу 'Last Updated', щоб уникнути повторного скрейпінгу незміненого контенту.
Відгуки
Що кажуть наші користувачі
Приєднуйтесь до тисяч задоволених користувачів, які трансформували свою роботу
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Пов'язані Web Scraping
Часті запитання про GOV.UK
Знайдіть відповіді на поширені запитання про GOV.UK