Jak scrapovat StubHub: Kompletní průvodce web scrapingem
Zjistěte, jak scrapovat StubHub pro získání cen vstupenek v reálném čase, dostupnosti akcí a dat o sedadlech. Naučte se, jak obejít Akamai a extrahovat tržní...
Detekována anti-bot ochrana
- Akamai Bot Manager
- Pokročilá detekce botů pomocí otisku zařízení, analýzy chování a strojového učení. Jeden z nejsofistikovanějších anti-bot systémů.
- PerimeterX (HUMAN)
- Behaviorální biometrie a prediktivní analýza. Detekuje automatizaci prostřednictvím pohybů myši, vzorů psaní a interakce se stránkou.
- Cloudflare
- Podnikový WAF a správa botů. Používá JavaScript výzvy, CAPTCHA a analýzu chování. Vyžaduje automatizaci prohlížeče se stealth nastavením.
- Omezení rychlosti
- Omezuje požadavky na IP/relaci v čase. Lze obejít rotujícími proxy, zpožděním požadavků a distribuovaným scrapingem.
- Blokování IP
- Blokuje známé IP datových center a označené adresy. Vyžaduje rezidenční nebo mobilní proxy pro efektivní obejití.
- Otisk prohlížeče
- Identifikuje boty pomocí vlastností prohlížeče: canvas, WebGL, písma, pluginy. Vyžaduje spoofing nebo skutečné profily prohlížeče.
O StubHub
Objevte, co StubHub nabízí a jaká cenná data lze extrahovat.
StubHub je největší sekundární tržiště se vstupenkami na světě, které poskytuje masivní platformu pro fanoušky k nákupu a prodeji vstupenek na sportovní utkání, koncerty, divadlo a další živé zábavní akce. Vlastněn společností Viagogo, funguje jako bezpečný prostředník, který zajišťuje pravost vstupenek a zpracovává miliony transakcí po celém světě. Stránka je pokladnicí dynamických dat, včetně map míst konání, kolísání cen v reálném čase a úrovní zásob.
Pro firmy a analytiky jsou data ze StubHub neocenitelná pro pochopení tržní poptávky a cenových trendů v zábavním průmyslu. Protože platforma odráží skutečnou tržní hodnotu vstupenek (často odlišnou od původní nominální hodnoty), slouží jako primární zdroj pro konkurenční zpravodajství, ekonomický výzkum a správu zásob pro prodejce vstupenek a promotéry akcí.
Scrapování této platformy umožňuje extrakci vysoce granulárních dat, od konkrétních čísel sedadel až po historické změny cen. Tato data pomáhají organizacím optimalizovat vlastní cenové strategie, předpovídat popularitu nadcházejících turné a vytvářet komplexní nástroje pro porovnávání cen pro spotřebitele.
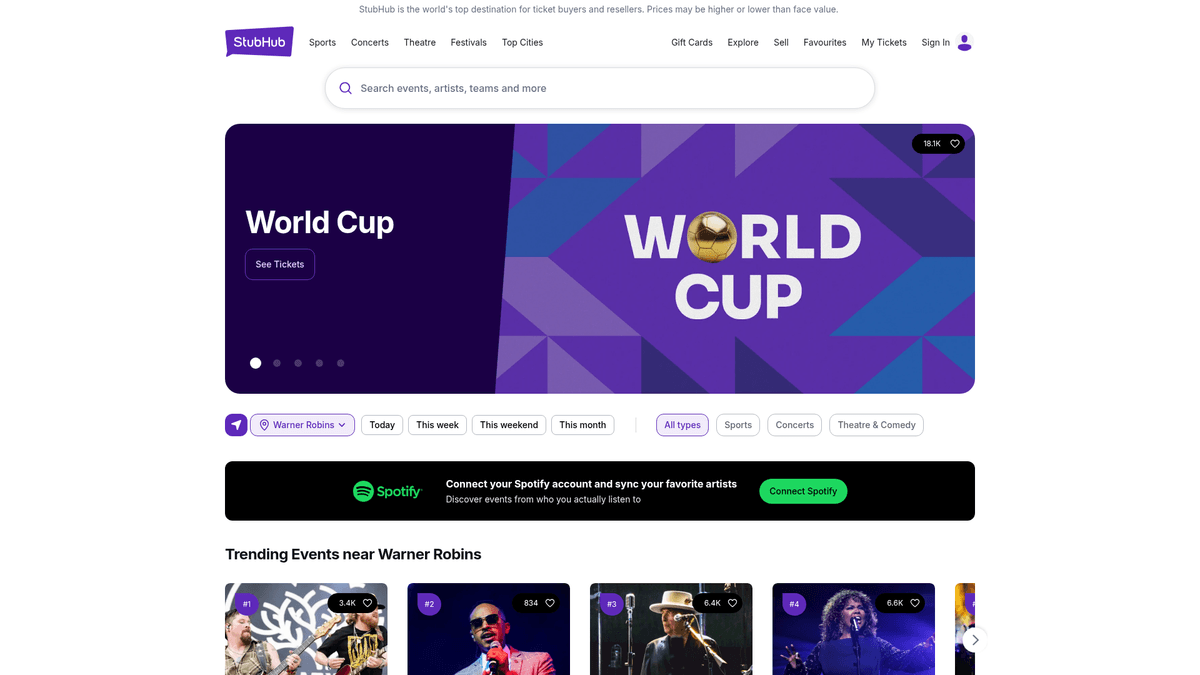
Proč Scrapovat StubHub?
Objevte obchodní hodnotu a případy použití pro extrakci dat z StubHub.
Sledování kolísání cen vstupenek v reálném čase v různých místech konání
Sledování úrovně zásob sedadel pro určení míry vyprodanosti akce
Konkurenční analýza vůči ostatním sekundárním trhům jako SeatGeek nebo Vivid Seats
Shromažďování historických údajů o cenách pro hlavní sportovní ligy a koncertní turné
Identifikace arbitrážních příležitostí mezi primárními a sekundárními trhy
Průzkum trhu pro organizátory akcí k posouzení poptávky fanoušků v konkrétních regionech
Výzvy Scrapování
Technické výzvy, se kterými se můžete setkat při scrapování StubHub.
Agresivní ochrana proti botům (Akamai), která identifikuje a blokuje automatizované vzorce prohlížeče
Rozsáhlé používání JavaScript a React pro vykreslování dynamických komponent výpisů a map
Časté změny ve struktuře HTML a CSS selektorech s cílem narušit statické scrapery
Přísné omezování rychlosti na základě IP, které vyžaduje použití vysoce kvalitních rezidenčních proxy
Složité interakce s mapou sedadel vyžadující pokročilou automatizaci prohlížeče
Scrapujte StubHub pomocí AI
Žádný kód není potřeba. Extrahujte data během minut s automatizací poháněnou AI.
Jak to funguje
Popište, co potřebujete
Řekněte AI, jaká data chcete extrahovat z StubHub. Stačí to napsat přirozeným jazykem — žádný kód ani selektory.
AI extrahuje data
Naše umělá inteligence prochází StubHub, zpracovává dynamický obsah a extrahuje přesně to, co jste požadovali.
Získejte svá data
Získejte čistá, strukturovaná data připravená k exportu jako CSV, JSON nebo k odeslání přímo do vašich aplikací.
Proč používat AI pro scrapování
AI usnadňuje scrapování StubHub bez psaní kódu. Naše platforma poháněná umělou inteligencí rozumí, jaká data chcete — stačí je popsat přirozeným jazykem a AI je automaticky extrahuje.
How to scrape with AI:
- Popište, co potřebujete: Řekněte AI, jaká data chcete extrahovat z StubHub. Stačí to napsat přirozeným jazykem — žádný kód ani selektory.
- AI extrahuje data: Naše umělá inteligence prochází StubHub, zpracovává dynamický obsah a extrahuje přesně to, co jste požadovali.
- Získejte svá data: Získejte čistá, strukturovaná data připravená k exportu jako CSV, JSON nebo k odeslání přímo do vašich aplikací.
Why use AI for scraping:
- Snadno obchází pokročilá opatření proti botům, jako jsou Akamai a PerimeterX
- Zvládá složité vykreslování JavaScript a dynamický obsah bez psaní kódu
- Automatizuje plánovaný sběr dat pro nepřetržité sledování cen a zásob 24/7
- Využívá vestavěnou rotaci proxy pro udržení vysoké úspěšnosti a zamezení zákazům IP
No-code webové scrapery pro StubHub
Alternativy point-and-click k AI scrapingu
Několik no-code nástrojů jako Browse.ai, Octoparse, Axiom a ParseHub vám může pomoci scrapovat StubHub bez psaní kódu. Tyto nástroje obvykle používají vizuální rozhraní pro výběr dat, i když mohou mít problémy se složitým dynamickým obsahem nebo anti-bot opatřeními.
Typický workflow s no-code nástroji
Běžné výzvy
Křivka učení
Pochopení selektorů a logiky extrakce vyžaduje čas
Selektory se rozbijí
Změny webu mohou rozbít celý pracovní postup
Problémy s dynamickým obsahem
Weby s hodně JavaScriptem vyžadují složitá řešení
Omezení CAPTCHA
Většina nástrojů vyžaduje ruční zásah u CAPTCHA
Blokování IP
Agresivní scrapování může vést k zablokování vaší IP
No-code webové scrapery pro StubHub
Několik no-code nástrojů jako Browse.ai, Octoparse, Axiom a ParseHub vám může pomoci scrapovat StubHub bez psaní kódu. Tyto nástroje obvykle používají vizuální rozhraní pro výběr dat, i když mohou mít problémy se složitým dynamickým obsahem nebo anti-bot opatřeními.
Typický workflow s no-code nástroji
- Nainstalujte rozšíření prohlížeče nebo se zaregistrujte na platformě
- Přejděte na cílový web a otevřete nástroj
- Vyberte datové prvky k extrakci kliknutím
- Nakonfigurujte CSS selektory pro každé datové pole
- Nastavte pravidla stránkování pro scrapování více stránek
- Vyřešte CAPTCHA (často vyžaduje ruční řešení)
- Nakonfigurujte plánování automatických spuštění
- Exportujte data do CSV, JSON nebo připojte přes API
Běžné výzvy
- Křivka učení: Pochopení selektorů a logiky extrakce vyžaduje čas
- Selektory se rozbijí: Změny webu mohou rozbít celý pracovní postup
- Problémy s dynamickým obsahem: Weby s hodně JavaScriptem vyžadují složitá řešení
- Omezení CAPTCHA: Většina nástrojů vyžaduje ruční zásah u CAPTCHA
- Blokování IP: Agresivní scrapování může vést k zablokování vaší IP
Příklady kódu
import requests
from bs4 import BeautifulSoup
# StubHub používá Akamai; jednoduchý požadavek bude pravděpodobně zablokován bez pokročilých hlaviček nebo proxy.
url = 'https://www.stubhub.com/find/s/?q=concerts'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36',
'Accept-Language': 'cs-CZ,cs;q=0.9'
}
try:
# Odeslání požadavku s hlavičkami pro simulaci skutečného prohlížeče
response = requests.get(url, headers=headers, timeout=10)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Příklad: Pokus o nalezení názvů událostí (selektory se často mění)
events = soup.select('.event-card-title')
for event in events:
print(f'Nalezena událost: {event.get_text(strip=True)}')
except requests.exceptions.RequestException as e:
print(f'Požadavek selhal: {e}')Kdy použít
Nejlepší pro statické HTML stránky s minimem JavaScriptu. Ideální pro blogy, zpravodajské weby a jednoduché e-commerce produktové stránky.
Výhody
- ●Nejrychlejší provedení (bez režie prohlížeče)
- ●Nejnižší spotřeba zdrojů
- ●Snadná paralelizace s asyncio
- ●Skvělé pro API a statické stránky
Omezení
- ●Nemůže spustit JavaScript
- ●Selhává na SPA a dynamickém obsahu
- ●Může mít problémy se složitými anti-bot systémy
Jak scrapovat StubHub pomocí kódu
Python + Requests
import requests
from bs4 import BeautifulSoup
# StubHub používá Akamai; jednoduchý požadavek bude pravděpodobně zablokován bez pokročilých hlaviček nebo proxy.
url = 'https://www.stubhub.com/find/s/?q=concerts'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36',
'Accept-Language': 'cs-CZ,cs;q=0.9'
}
try:
# Odeslání požadavku s hlavičkami pro simulaci skutečného prohlížeče
response = requests.get(url, headers=headers, timeout=10)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Příklad: Pokus o nalezení názvů událostí (selektory se často mění)
events = soup.select('.event-card-title')
for event in events:
print(f'Nalezena událost: {event.get_text(strip=True)}')
except requests.exceptions.RequestException as e:
print(f'Požadavek selhal: {e}')Python + Playwright
from playwright.sync_api import sync_playwright
def scrape_stubhub():
with sync_playwright() as p:
# Spuštění prohlížeče v headless nebo headed režimu
browser = p.chromium.launch(headless=True)
context = browser.new_context(user_agent='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36')
page = context.new_page()
# Navigace na stránku konkrétní události
page.goto('https://www.stubhub.com/concert-tickets/')
# Počkání na načtení dynamických výpisů vstupenek do DOM
page.wait_for_selector('.event-card', timeout=10000)
# Extrakce dat pomocí locatoru
titles = page.locator('.event-card-title').all_inner_texts()
for title in titles:
print(title)
browser.close()
if __name__ == '__main__':
scrape_stubhub()Python + Scrapy
import scrapy
class StubHubSpider(scrapy.Spider):
name = 'stubhub_spider'
start_urls = ['https://www.stubhub.com/search']
def parse(self, response):
# Data StubHubu jsou často uvnitř JSON script tagů nebo vykreslována přes JS
# Tento příklad používá pro demonstraci standardní CSS selektory
for event in response.css('.event-item-container'):
yield {
'name': event.css('.event-title::text').get(),
'price': event.css('.price-amount::text').get(),
'location': event.css('.venue-info::text').get()
}
# Zpracování stránkování nalezením tlačítka 'Next'
next_page = response.css('a.pagination-next::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
// Nastavení realistického User Agent
await page.setUserAgent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36');
try {
await page.goto('https://www.stubhub.com', { waitUntil: 'networkidle2' });
// Počkání na vykreslení výpisů pomocí Reactu
await page.waitForSelector('.event-card');
const data = await page.evaluate(() => {
const items = Array.from(document.querySelectorAll('.event-card'));
return items.map(item => ({
title: item.querySelector('.event-title-class')?.innerText,
price: item.querySelector('.price-class')?.innerText
}));
});
console.log(data);
} catch (err) {
console.error('Chyba během scrapování:', err);
} finally {
await browser.close();
}
})();Co Můžete Dělat S Daty StubHub
Prozkoumejte praktické aplikace a poznatky z dat StubHub.
Analýza dynamické tvorby cen vstupenek
Prodejci vstupenek mohou upravovat své ceny v reálném čase na základě aktuální tržní nabídky a poptávky pozorované na StubHub.
Jak implementovat:
- 1Každou hodinu extrahujte ceny konkurence pro konkrétní sekce k sezení.
- 2Identifikujte cenové trendy vedoucí k datu konání události.
- 3Automaticky upravujte ceny nabídek na sekundárních trzích, abyste zůstali nejkonkurenceschopnější.
Použijte Automatio k extrakci dat z StubHub a vytvoření těchto aplikací bez psaní kódu.
Co Můžete Dělat S Daty StubHub
- Analýza dynamické tvorby cen vstupenek
Prodejci vstupenek mohou upravovat své ceny v reálném čase na základě aktuální tržní nabídky a poptávky pozorované na StubHub.
- Každou hodinu extrahujte ceny konkurence pro konkrétní sekce k sezení.
- Identifikujte cenové trendy vedoucí k datu konání události.
- Automaticky upravujte ceny nabídek na sekundárních trzích, abyste zůstali nejkonkurenceschopnější.
- Bot pro arbitráž na sekundárním trhu
Najděte vstupenky, které jsou oceněny výrazně pod tržním průměrem pro rychlý zisk z přeprodeje.
- Scrapujte více platforem pro vstupenky (StubHub, SeatGeek, Vivid Seats) současně.
- Porovnejte ceny pro přesně stejnou řadu a sekci.
- Odesílejte okamžitá upozornění, když je vstupenka na jedné platformě oceněna dostatečně nízko pro ziskový přeprodej.
- Předpovídání popularity událostí
Promotéři využívají data o zásobách k rozhodování, zda přidat další termíny k turné nebo změnit místo konání.
- Sledujte pole „Quantity Available“ u konkrétního umělce v několika městech.
- Vypočítejte rychlost, s jakou ubývá inventář (velocity).
- Generujte reporty poptávky pro odůvodnění přidání dalších představení v oblastech s vysokou poptávkou.
- Analýza míst konání pro pohostinství
Hotely a restaurace v okolí mohou předpovídat rušné noci sledováním vyprodaných událostí a objemu vstupenek.
- Scrapujte plány nadcházejících událostí pro místní stadiony a divadla.
- Sledujte nedostatek vstupenek pro identifikaci dnů s vysokým dopadem.
- Upravte stav personálu a marketingové kampaně na večery s špičkovými událostmi.
Zrychlete svuj workflow s AI automatizaci
Automatio kombinuje silu AI agentu, webove automatizace a chytrych integraci, aby vam pomohl dosahnout vice za kratsi cas.
Profesionální Tipy Pro Scrapování StubHub
Odborné rady pro úspěšnou extrakci dat z StubHub.
Používejte kvalitní rezidenční proxy. IP adresy datových center jsou systémem Akamai téměř okamžitě identifikovány a zablokovány.
Sledujte požadavky XHR/Fetch na kartě Network (Sít) ve vašem prohlížeči. StubHub často načítá data o vstupenkách ve formátu JSON, který se parsuje snadněji než HTML.
Implementujte náhodné prodlevy a interakce podobné lidskému chování (pohyby myši, rolování), abyste snížili riziko detekce.
Zaměřte se na scrapování konkrétních ID událostí. Struktura URL obvykle obsahuje unikátní ID, které lze použít k vytváření přímých odkazů na nabídky vstupenek.
Scrapujte mimo špičku, kdy je zatížení serveru nižší, abyste minimalizovali pravděpodobnost aktivace agresivních rate limits.
Střídejte různé profily prohlížeče a User-Agents, abyste napodobili různorodou skupinu reálných uživatelů.
Reference
Co rikaji nasi uzivatele
Pridejte se k tisicum spokojenych uzivatelu, kteri transformovali svuj workflow
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Souvisejici Web Scraping
How to Scrape Tata 1mg | 1mg.com Medicine Data Scraper
How to Scrape Carwow: Extract Used Car Data and Prices

How to Scrape Kalodata: TikTok Shop Data Extraction Guide
How to Scrape HP.com: A Technical Guide to Product & Price Data
How to Scrape eBay | eBay Web Scraper Guide
How to Scrape The Range UK | Product Data & Prices Scraper
How to Scrape ThemeForest Web Data
How to Scrape AliExpress: The Ultimate 2025 Data Extraction Guide
Casto kladene dotazy o StubHub
Najdete odpovedi na bezne otazky o StubHub