Jak scrapovat Web Designer News
Naučte se, jak scrapovat Web Designer News pro extrakci trendových designových zpráv, zdrojových URL a časových razítek. Ideální pro sledování trendů v designu...
O Web Designer News
Objevte, co Web Designer News nabízí a jaká cenná data lze extrahovat.
Přehled Web Designer News
Web Designer News je přední komunitní agregátor zpráv speciálně kurátorovaný pro ekosystém webového designu a vývoje. Od svého založení funguje platforma jako centrální uzel, kde profesionálové objevují ručně vybraný výběr nejrelevantnějších zpráv, tutoriálů, nástrojů a zdrojů z celého internetu. Pokrývá široké spektrum témat včetně UX designu, obchodní strategie, technologických novinek a grafického designu, prezentovaných v čistém, chronologickém feedu.
Architektura webu a potenciál dat
Architektura webu je postavena na WordPressu a vyznačuje se vysoce strukturovaným rozvržením, které organizuje obsah do specifických kategorií jako 'Web Design', 'Web Dev', 'UX' a 'Resources'. Protože agreguje data z tisíců jednotlivých blogů a časopisů do jediného prohledávatelného rozhraní, slouží jako vysoce kvalitní filtr pro oborové informace. Tato struktura z něj činí ideální cíl pro web scraping, protože poskytuje přístup k předem prověřenému toku vysoce hodnotných oborových dat bez nutnosti procházet stovky samostatných domén.
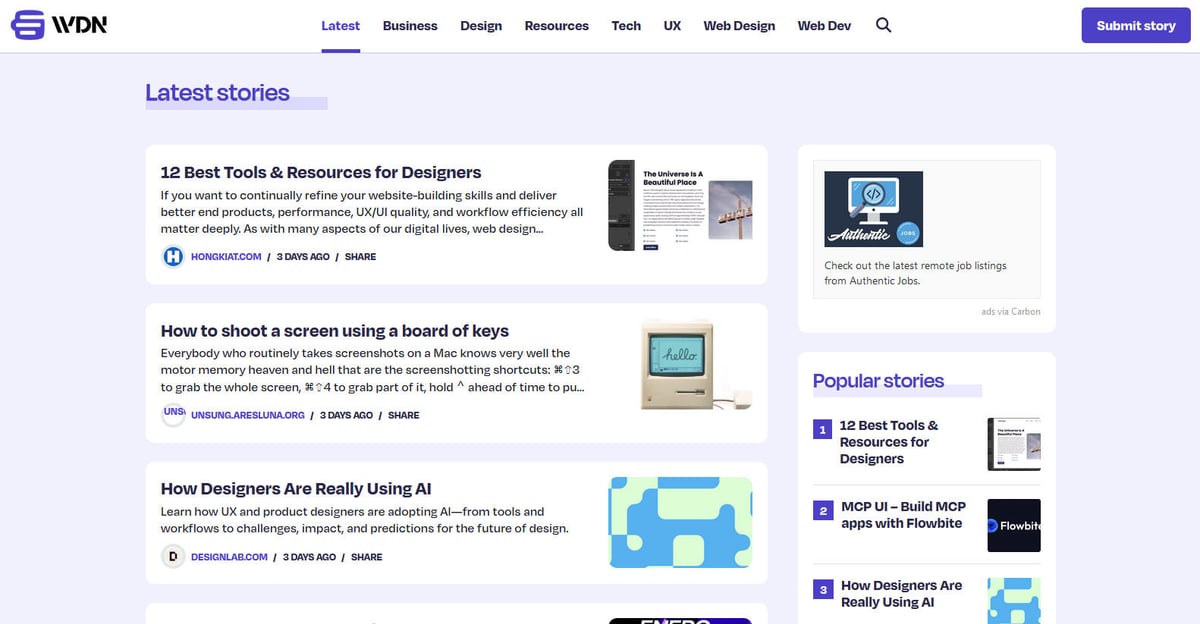
Proč Scrapovat Web Designer News?
Objevte obchodní hodnotu a případy použití pro extrakci dat z Web Designer News.
Identifikace vznikajících trendů a nástrojů v designu v reálném čase.
Automatizace kurátorství oborových zpráv pro newslettery a sociální sítě.
Provádění konkurenční analýzy sledováním obsahu od konkurentů.
Generování vysoce kvalitních datasetů pro trénování Natural Language Processing (NLP).
Budování centralizované knihovny designových zdrojů pro interní znalostní báze týmů.
Výzvy Scrapování
Technické výzvy, se kterými se můžete setkat při scrapování Web Designer News.
Zpracování technických přesměrování přes interní systém 'go' odkazů webu.
Nekonzistentní dostupnost obrázků miniatur u starších archivovaných příspěvků.
Server-side rate limiting u vysoce frekventovaných požadavků díky ochraně Nginx.
Scrapujte Web Designer News pomocí AI
Žádný kód není potřeba. Extrahujte data během minut s automatizací poháněnou AI.
Jak to funguje
Popište, co potřebujete
Řekněte AI, jaká data chcete extrahovat z Web Designer News. Stačí to napsat přirozeným jazykem — žádný kód ani selektory.
AI extrahuje data
Naše umělá inteligence prochází Web Designer News, zpracovává dynamický obsah a extrahuje přesně to, co jste požadovali.
Získejte svá data
Získejte čistá, strukturovaná data připravená k exportu jako CSV, JSON nebo k odeslání přímo do vašich aplikací.
Proč používat AI pro scrapování
AI usnadňuje scrapování Web Designer News bez psaní kódu. Naše platforma poháněná umělou inteligencí rozumí, jaká data chcete — stačí je popsat přirozeným jazykem a AI je automaticky extrahuje.
How to scrape with AI:
- Popište, co potřebujete: Řekněte AI, jaká data chcete extrahovat z Web Designer News. Stačí to napsat přirozeným jazykem — žádný kód ani selektory.
- AI extrahuje data: Naše umělá inteligence prochází Web Designer News, zpracovává dynamický obsah a extrahuje přesně to, co jste požadovali.
- Získejte svá data: Získejte čistá, strukturovaná data připravená k exportu jako CSV, JSON nebo k odeslání přímo do vašich aplikací.
Why use AI for scraping:
- Kompletní no-code workflow pro netechnické designéry a marketéry.
- Cloudové plánování umožňuje automatickou denní extrakci zpráv.
- Vestavěné zpracování stránkování a detekce strukturovaných prvků.
- Přímá integrace s Google Sheets pro okamžitou distribuci dat.
No-code webové scrapery pro Web Designer News
Alternativy point-and-click k AI scrapingu
Několik no-code nástrojů jako Browse.ai, Octoparse, Axiom a ParseHub vám může pomoci scrapovat Web Designer News bez psaní kódu. Tyto nástroje obvykle používají vizuální rozhraní pro výběr dat, i když mohou mít problémy se složitým dynamickým obsahem nebo anti-bot opatřeními.
Typický workflow s no-code nástroji
Běžné výzvy
Křivka učení
Pochopení selektorů a logiky extrakce vyžaduje čas
Selektory se rozbijí
Změny webu mohou rozbít celý pracovní postup
Problémy s dynamickým obsahem
Weby s hodně JavaScriptem vyžadují složitá řešení
Omezení CAPTCHA
Většina nástrojů vyžaduje ruční zásah u CAPTCHA
Blokování IP
Agresivní scrapování může vést k zablokování vaší IP
No-code webové scrapery pro Web Designer News
Několik no-code nástrojů jako Browse.ai, Octoparse, Axiom a ParseHub vám může pomoci scrapovat Web Designer News bez psaní kódu. Tyto nástroje obvykle používají vizuální rozhraní pro výběr dat, i když mohou mít problémy se složitým dynamickým obsahem nebo anti-bot opatřeními.
Typický workflow s no-code nástroji
- Nainstalujte rozšíření prohlížeče nebo se zaregistrujte na platformě
- Přejděte na cílový web a otevřete nástroj
- Vyberte datové prvky k extrakci kliknutím
- Nakonfigurujte CSS selektory pro každé datové pole
- Nastavte pravidla stránkování pro scrapování více stránek
- Vyřešte CAPTCHA (často vyžaduje ruční řešení)
- Nakonfigurujte plánování automatických spuštění
- Exportujte data do CSV, JSON nebo připojte přes API
Běžné výzvy
- Křivka učení: Pochopení selektorů a logiky extrakce vyžaduje čas
- Selektory se rozbijí: Změny webu mohou rozbít celý pracovní postup
- Problémy s dynamickým obsahem: Weby s hodně JavaScriptem vyžadují složitá řešení
- Omezení CAPTCHA: Většina nástrojů vyžaduje ruční zásah u CAPTCHA
- Blokování IP: Agresivní scrapování může vést k zablokování vaší IP
Příklady kódu
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
url = 'https://webdesignernews.com/'
try:
# Odeslat požadavek na hlavní stránku
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Najít kontejnery příspěvků
posts = soup.find_all('div', class_='single-post')
for post in posts:
title = post.find('h3').get_text(strip=True)
# Zkontrolovat, zda existuje název zdrojového webu
source = post.find('span', class_='site_name').get_text(strip=True) if post.find('span', class_='site_name') else 'Unknown'
link = post.find('h3').find('a')['href']
print(f'Title: {title} | Source: {source} | Link: {link}')
except Exception as e:
print(f'Došlo k chybě: {e}')Kdy použít
Nejlepší pro statické HTML stránky s minimem JavaScriptu. Ideální pro blogy, zpravodajské weby a jednoduché e-commerce produktové stránky.
Výhody
- ●Nejrychlejší provedení (bez režie prohlížeče)
- ●Nejnižší spotřeba zdrojů
- ●Snadná paralelizace s asyncio
- ●Skvělé pro API a statické stránky
Omezení
- ●Nemůže spustit JavaScript
- ●Selhává na SPA a dynamickém obsahu
- ●Může mít problémy se složitými anti-bot systémy
Jak scrapovat Web Designer News pomocí kódu
Python + Requests
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
url = 'https://webdesignernews.com/'
try:
# Odeslat požadavek na hlavní stránku
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Najít kontejnery příspěvků
posts = soup.find_all('div', class_='single-post')
for post in posts:
title = post.find('h3').get_text(strip=True)
# Zkontrolovat, zda existuje název zdrojového webu
source = post.find('span', class_='site_name').get_text(strip=True) if post.find('span', class_='site_name') else 'Unknown'
link = post.find('h3').find('a')['href']
print(f'Title: {title} | Source: {source} | Link: {link}')
except Exception as e:
print(f'Došlo k chybě: {e}')Python + Playwright
from playwright.sync_api import sync_playwright
def scrape_wdn():
with sync_playwright() as p:
# Spusťte headless browser
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto('https://webdesignernews.com/')
# Počkejte na načtení selektorů příspěvků
page.wait_for_selector('.single-post')
posts = page.query_selector_all('.single-post')
for post in posts:
title_el = post.query_selector('h3 a')
if title_el:
title = title_el.inner_text()
link = title_el.get_attribute('href')
print(f'Scraped: {title} - {link}')
browser.close()
scrape_wdn()Python + Scrapy
import scrapy
class WdnSpider(scrapy.Spider):
name = 'wdn_spider'
start_urls = ['https://webdesignernews.com/']
def parse(self, response):
# Extrahujte každý příspěvek ve feedu
for post in response.css('.single-post'):
yield {
'title': post.css('h3 a::text').get(),
'source': post.css('.site_name::text').get(),
'link': post.css('h3 a::attr(href)').get()
}
# Řešení stránkování vyhledáním odkazu 'Next'
next_page = response.css('a.next::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://webdesignernews.com/', { waitUntil: 'domcontentloaded' });
// Vyhodnoťte stránku pro extrakci datových polí
const results = await page.evaluate(() => {
const items = Array.from(document.querySelectorAll('.single-post'));
return items.map(item => ({
title: item.querySelector('h3 a') ? item.querySelector('h3 a').innerText : null,
source: item.querySelector('.site_name') ? item.querySelector('.site_name').innerText : null,
link: item.querySelector('h3 a') ? item.querySelector('h3 a').href : null
}));
});
console.log(results);
await browser.close();
})();Co Můžete Dělat S Daty Web Designer News
Prozkoumejte praktické aplikace a poznatky z dat Web Designer News.
Automatizovaný feed designových novinek
Vytvořte živý, kurátorovaný kanál novinek pro profesionální designérské týmy přes Slack nebo Discord.
Jak implementovat:
- 1Scrapujte nejlépe hodnocené příběhy každé 4 hodiny.
- 2Filtrujte výsledky podle relevantních kategorií jako 'UX' nebo 'Web Dev'.
- 3Odesílejte extrahované titulky a shrnutí na messaging webhook.
- 4Archivujte data pro sledování dlouhodobé popularity nástrojů v oboru.
Použijte Automatio k extrakci dat z Web Designer News a vytvoření těchto aplikací bez psaní kódu.
Co Můžete Dělat S Daty Web Designer News
- Automatizovaný feed designových novinek
Vytvořte živý, kurátorovaný kanál novinek pro profesionální designérské týmy přes Slack nebo Discord.
- Scrapujte nejlépe hodnocené příběhy každé 4 hodiny.
- Filtrujte výsledky podle relevantních kategorií jako 'UX' nebo 'Web Dev'.
- Odesílejte extrahované titulky a shrnutí na messaging webhook.
- Archivujte data pro sledování dlouhodobé popularity nástrojů v oboru.
- Sledování trendů v designových nástrojích
Identifikujte, který designový software nebo knihovny získávají největší pozornost komunity.
- Extrahujte titulky a úryvky z archivu kategorie 'Resources'.
- Proveďte analýzu frekvence klíčových slov pro konkrétní termíny (např. 'Figma', 'React').
- Porovnejte nárůst zmínek měsíc po měsíci pro identifikaci vycházejících hvězd.
- Exportujte vizuální reporty pro marketingové nebo produktové týmy.
- Monitorování zpětných odkazů konkurence
Identifikujte, které blogy nebo agentury úspěšně umisťují obsah na hlavní informační uzly.
- Scrapujte pole 'Source Website Name' pro všechny historické záznamy.
- Agregujte počty zmínek na externí doménu, abyste viděli, kdo je nejčastěji uváděn.
- Analyzujte typy obsahu, které jsou přijímány, pro lepší outreach.
- Identifikujte potenciální partnery pro spolupráci v oblasti designu.
- Trénovací dataset pro machine learning
Použijte kurátorované úryvky a shrnutí k trénování modelů pro technickou sumarizaci.
- Scrapujte více než 10 000 titulků příběhů a odpovídajících shrnutí.
- Očistěte textová data od interních sledovacích parametrů a HTML.
- Použijte titulek jako cíl a úryvek jako vstup pro fine-tuning.
- Otestujte model na nových, nezařazených článcích o designu pro ověření výkonu.
Zrychlete svuj workflow s AI automatizaci
Automatio kombinuje silu AI agentu, webove automatizace a chytrych integraci, aby vam pomohl dosahnout vice za kratsi cas.
Profesionální Tipy Pro Scrapování Web Designer News
Odborné rady pro úspěšnou extrakci dat z Web Designer News.
Zaměřte se na WordPress REST API endpoint (/wp-json/wp/v2/posts) pro rychlejší a spolehlivější získávání strukturovaných dat než při parsování HTML.
Sledujte RSS feed webu na adrese webdesignernews.com/feed/, abyste zachytili nové příběhy v okamžiku, kdy jsou publikovány.
Plánujte své scraping úlohy na 9
00 AM EST, což odpovídá denní špičce obsahu zasílaného komunitou.
Střídejte řetězce User-Agent a implementujte 2sekundovou prodlevu mezi požadavky, abyste předešli aktivaci Nginx rate limits.
Vždy vyhodnocujte interní odkazy '/go/' sledováním přesměrování, abyste získali finální kanonickou URL zdroje.
Očistěte textová data úryvků (excerpt) odstraněním HTML tagů a koncových výpustek pro lepší výsledky analýzy.
Reference
Co rikaji nasi uzivatele
Pridejte se k tisicum spokojenych uzivatelu, kteri transformovali svuj workflow
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Souvisejici Web Scraping




Casto kladene dotazy o Web Designer News
Najdete odpovedi na bezne otazky o Web Designer News