Sådan scraper du Web Designer News
Lær hvordan du scraper Web Designer News for at udtrække populære designhistorier, kilde-URL'er og tidsstempler. Perfekt til trend-overvågning og...
Om Web Designer News
Opdag hvad Web Designer News tilbyder og hvilke værdifulde data der kan udtrækkes.
Oversigt over Web Designer News
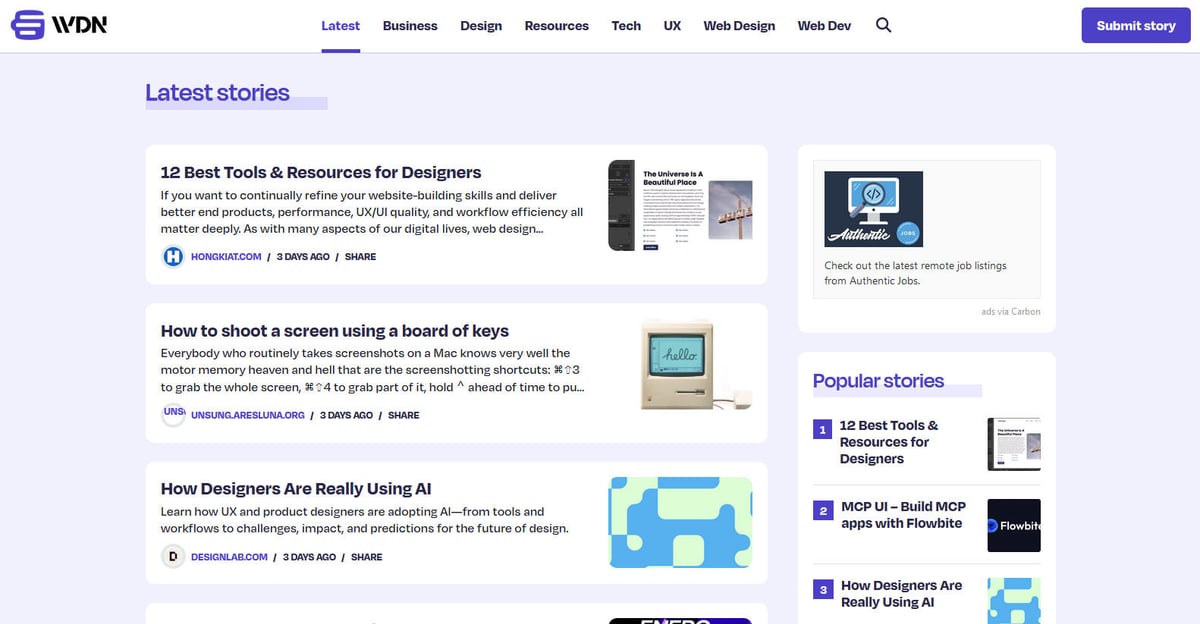
Web Designer News er en førende community-drevet nyhedsaggregator, der er specifikt kurateret til webdesign- og udviklingsøkosystemet. Siden opstarten har platformen fungeret som et centralt knudepunkt, hvor professionelle opdager et håndplukket udvalg af de mest relevante nyhedshistorier, tutorials, værktøjer og ressourcer fra hele internettet. Den dækker et bredt spektrum af emner, herunder UX design, forretningsstrategi, teknologiopdateringer og grafisk design, præsenteret i et rent, kronologisk feed.
Webside-arkitektur og datapotentiale
Hjemmesidens arkitektur er bygget på WordPress og har et meget struktureret layout, der organiserer indhold i specifikke kategorier som 'Web Design', 'Web Dev', 'UX' og 'Resources'. Da den samler data fra tusindvis af individuelle blogs og tidsskrifter i ét søgbart interface, fungerer den som et filter af høj kvalitet til brancheindsigt. Denne struktur gør den til et ideelt mål for web scraping, da den giver adgang til en forhåndsgodkendt strøm af værdifulde branchedata uden behov for at crawle hundredvis af separate domæner.
Hvorfor Skrabe Web Designer News?
Opdag forretningsværdien og brugsscenarier for dataudtrækning fra Web Designer News.
Identificer nye designtrends og værktøjer i realtid.
Automatiser kuratering af branchenyheder til nyhedsbreve og feeds på sociale medier.
Udfør konkurrentanalyse ved at overvåge udvalgt indhold fra rivaler.
Generer datasæt af høj kvalitet til træning af Natural Language Processing (NLP).
Byg et centraliseret designressourcebibliotek til interne vidensbaser.
Skrabningsudfordringer
Tekniske udfordringer du kan støde på når du skraber Web Designer News.
Håndtering af tekniske redirections gennem sidens interne 'go'-link-system.
Inkonsekvent tilgængelighed af thumbnails på tværs af ældre arkiverede indlæg.
Server-side rate limiting på anmodninger med høj frekvens via Nginx-beskyttelse.
Skrab Web Designer News med AI
Ingen kode nødvendig. Udtræk data på minutter med AI-drevet automatisering.
Sådan fungerer det
Beskriv hvad du har brug for
Fortæl AI'en hvilke data du vil udtrække fra Web Designer News. Skriv det bare på almindeligt sprog — ingen kode eller selektorer nødvendige.
AI udtrækker dataene
Vores kunstige intelligens navigerer Web Designer News, håndterer dynamisk indhold og udtrækker præcis det du bad om.
Få dine data
Modtag rene, strukturerede data klar til eksport som CSV, JSON eller send direkte til dine apps og workflows.
Hvorfor bruge AI til skrabning
AI gør det nemt at skrabe Web Designer News uden at skrive kode. Vores AI-drevne platform bruger kunstig intelligens til at forstå hvilke data du ønsker — beskriv det på almindeligt sprog, og AI udtrækker dem automatisk.
How to scrape with AI:
- Beskriv hvad du har brug for: Fortæl AI'en hvilke data du vil udtrække fra Web Designer News. Skriv det bare på almindeligt sprog — ingen kode eller selektorer nødvendige.
- AI udtrækker dataene: Vores kunstige intelligens navigerer Web Designer News, håndterer dynamisk indhold og udtrækker præcis det du bad om.
- Få dine data: Modtag rene, strukturerede data klar til eksport som CSV, JSON eller send direkte til dine apps og workflows.
Why use AI for scraping:
- Komplet no-code workflow for ikke-tekniske designere og marketingfolk.
- Cloud-baseret planlægning giver mulighed for automatiseret daglig nyheds-extraction.
- Indbygget håndtering af paginering og detektering af strukturerede elementer.
- Direkte integration med Google Sheets for øjeblikkelig datadistribution.
No-code webscrapere til Web Designer News
Point-and-click alternativer til AI-drevet scraping
Flere no-code værktøjer som Browse.ai, Octoparse, Axiom og ParseHub kan hjælpe dig med at scrape Web Designer News uden at skrive kode. Disse værktøjer bruger typisk visuelle interfaces til at vælge data, selvom de kan have problemer med komplekst dynamisk indhold eller anti-bot foranstaltninger.
Typisk workflow med no-code værktøjer
Almindelige udfordringer
Indlæringskurve
At forstå selektorer og ekstraktionslogik tager tid
Selektorer går i stykker
Webstedsændringer kan ødelægge hele din arbejdsgang
Problemer med dynamisk indhold
JavaScript-tunge sider kræver komplekse løsninger
CAPTCHA-begrænsninger
De fleste værktøjer kræver manuel indgriben for CAPTCHAs
IP-blokering
Aggressiv scraping kan føre til blokering af din IP
No-code webscrapere til Web Designer News
Flere no-code værktøjer som Browse.ai, Octoparse, Axiom og ParseHub kan hjælpe dig med at scrape Web Designer News uden at skrive kode. Disse værktøjer bruger typisk visuelle interfaces til at vælge data, selvom de kan have problemer med komplekst dynamisk indhold eller anti-bot foranstaltninger.
Typisk workflow med no-code værktøjer
- Installer browserudvidelse eller tilmeld dig platformen
- Naviger til målwebstedet og åbn værktøjet
- Vælg dataelementer med point-and-click
- Konfigurer CSS-selektorer for hvert datafelt
- Opsæt pagineringsregler til at scrape flere sider
- Håndter CAPTCHAs (kræver ofte manuel løsning)
- Konfigurer planlægning for automatiske kørsler
- Eksporter data til CSV, JSON eller forbind via API
Almindelige udfordringer
- Indlæringskurve: At forstå selektorer og ekstraktionslogik tager tid
- Selektorer går i stykker: Webstedsændringer kan ødelægge hele din arbejdsgang
- Problemer med dynamisk indhold: JavaScript-tunge sider kræver komplekse løsninger
- CAPTCHA-begrænsninger: De fleste værktøjer kræver manuel indgriben for CAPTCHAs
- IP-blokering: Aggressiv scraping kan føre til blokering af din IP
Kodeeksempler
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
url = 'https://webdesignernews.com/'
try:
# Send anmodning til forsiden
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Find beholdere til indlæg
posts = soup.find_all('div', class_='single-post')
for post in posts:
title = post.find('h3').get_text(strip=True)
# Tjek om kildewebsitets navn eksisterer
source = post.find('span', class_='site_name').get_text(strip=True) if post.find('span', class_='site_name') else 'Unknown'
link = post.find('h3').find('a')['href']
print(f'Titel: {title} | Kilde: {source} | Link: {link}')
except Exception as e:
print(f'Der opstod en fejl: {e}')Hvornår skal det bruges
Bedst til statiske HTML-sider med minimal JavaScript. Ideel til blogs, nyhedssider og simple e-handelsprodukt sider.
Fordele
- ●Hurtigste udførelse (ingen browser overhead)
- ●Laveste ressourceforbrug
- ●Let at parallelisere med asyncio
- ●Fremragende til API'er og statiske sider
Begrænsninger
- ●Kan ikke køre JavaScript
- ●Fejler på SPA'er og dynamisk indhold
- ●Kan have problemer med komplekse anti-bot systemer
Sådan scraper du Web Designer News med kode
Python + Requests
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
url = 'https://webdesignernews.com/'
try:
# Send anmodning til forsiden
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Find beholdere til indlæg
posts = soup.find_all('div', class_='single-post')
for post in posts:
title = post.find('h3').get_text(strip=True)
# Tjek om kildewebsitets navn eksisterer
source = post.find('span', class_='site_name').get_text(strip=True) if post.find('span', class_='site_name') else 'Unknown'
link = post.find('h3').find('a')['href']
print(f'Titel: {title} | Kilde: {source} | Link: {link}')
except Exception as e:
print(f'Der opstod en fejl: {e}')Python + Playwright
from playwright.sync_api import sync_playwright
def scrape_wdn():
with sync_playwright() as p:
# Start headless browser
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto('https://webdesignernews.com/')
# Vent på at post-elementerne indlæses
page.wait_for_selector('.single-post')
posts = page.query_selector_all('.single-post')
for post in posts:
title_el = post.query_selector('h3 a')
if title_el:
title = title_el.inner_text()
link = title_el.get_attribute('href')
print(f'Scraped: {title} - {link}')
browser.close()
scrape_wdn()Python + Scrapy
import scrapy
class WdnSpider(scrapy.Spider):
name = 'wdn_spider'
start_urls = ['https://webdesignernews.com/']
def parse(self, response):
# Udtræk hvert indlæg i feedet
for post in response.css('.single-post'):
yield {
'title': post.css('h3 a::text').get(),
'source': post.css('.site_name::text').get(),
'link': post.css('h3 a::attr(href)').get()
}
# Håndter paginering ved at finde 'Næste'-linket
next_page = response.css('a.next::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://webdesignernews.com/', { waitUntil: 'domcontentloaded' });
// Evaluer siden for at udtrække datafelter
const results = await page.evaluate(() => {
const items = Array.from(document.querySelectorAll('.single-post'));
return items.map(item => ({
title: item.querySelector('h3 a') ? item.querySelector('h3 a').innerText : null,
source: item.querySelector('.site_name') ? item.querySelector('.site_name').innerText : null,
link: item.querySelector('h3 a') ? item.querySelector('h3 a').href : null
}));
});
console.log(results);
await browser.close();
})();Hvad Du Kan Gøre Med Web Designer News-Data
Udforsk praktiske anvendelser og indsigter fra Web Designer News-data.
Automatiseret design-nyhedsfeed
Opret en live, kurateret nyhedskanal til professionelle designteams via Slack eller Discord.
Sådan implementeres:
- 1Scrape de bedst bedømte historier hver 4. time.
- 2Filtrer resultater efter relevante kategoritags som 'UX' eller 'Web Dev'.
- 3Send udtrukne titler og resuméer til en messaging-webhook.
- 4Arkiver data for at spore populariteten af brancheværktøjer over tid.
Brug Automatio til at udtrække data fra Web Designer News og bygge disse applikationer uden at skrive kode.
Hvad Du Kan Gøre Med Web Designer News-Data
- Automatiseret design-nyhedsfeed
Opret en live, kurateret nyhedskanal til professionelle designteams via Slack eller Discord.
- Scrape de bedst bedømte historier hver 4. time.
- Filtrer resultater efter relevante kategoritags som 'UX' eller 'Web Dev'.
- Send udtrukne titler og resuméer til en messaging-webhook.
- Arkiver data for at spore populariteten af brancheværktøjer over tid.
- Trend-tracker til designværktøjer
Identificer hvilken designsoftware eller hvilke biblioteker, der vinder mest fremgang i community'et.
- Udtræk titler og uddrag fra arkivet i kategorien 'Resources'.
- Udfør søgeordsfrekvensanalyse på specifikke termer (f.eks. 'Figma', 'React').
- Sammenlign væksten i omtaler måned for måned for at identificere nye trends.
- Eksporter visuelle rapporter til marketing- eller produktstrategiteams.
- Overvågning af konkurrent-backlinks
Identificer hvilke blogs eller bureauer, der har succes med at få deres indhold placeret på store knudepunkter.
- Scrape feltet 'Source Website Name' for alle historiske opslag.
- Aggreger antallet af omtaler pr. eksternt domæne for at se, hvem der bliver fremhævet mest.
- Analyser hvilke typer indhold der bliver accepteret for at opnå bedre outreach.
- Identificer potentielle samarbejdspartnere inden for designfeltet.
- Datasæt til træning af machine learning
Brug de kuraterede uddrag og resuméer til at træne tekniske modeller til opsummering.
- Scrape 10.000+ historietitler og tilhørende uddragsresuméer.
- Rens tekstdata for at fjerne interne sporingsparametre og HTML.
- Brug titlen som mål og uddraget som input til fine-tuning.
- Test modellen på nye designartikler for at vurdere ydeevnen.
Supercharg din arbejdsgang med AI-automatisering
Automatio kombinerer kraften fra AI-agenter, webautomatisering og smarte integrationer for at hjælpe dig med at udrette mere på kortere tid.
Professionelle Tips til Skrabning af Web Designer News
Ekspertråd til succesfuld dataudtrækning fra Web Designer News.
Målret din scraping mod WordPress REST API-endpointet (/wp-json/wp/v2/posts) for hurtigere og mere pålidelige strukturerede data end ved HTML-parsing.
Overvåg sidens RSS-feed på webdesignernews.com/feed/ for at fange nye historier i det øjeblik, de bliver udgivet.
Planlæg dine scraping-opgaver til kl. 09
00 EST for at matche det daglige højdepunkt for community-indsendt indhold.
Roter User-Agent-strenge og implementer en 2-sekunders forsinkelse mellem anmodninger for at undgå at udløse Nginx rate limits.
Opløs altid de interne '/go/'-links ved at følge redirects for at udtrække den endelige kanoniske kilde-URL.
Rens uddragstekstdata ved at fjerne HTML-tags og efterfølgende ellipser for bedre analyseresultater.
Anmeldelser
Hvad vores brugere siger
Slut dig til tusindvis af tilfredse brugere, der har transformeret deres arbejdsgang
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Relateret Web Scraping




Ofte stillede spørgsmål om Web Designer News
Find svar på almindelige spørgsmål om Web Designer News