Πώς να κάνετε Scrape το Web Designer News
Μάθετε πώς να κάνετε scrape το Web Designer News για να εξαγάγετε δημοφιλείς ιστορίες design, URL πηγών και timestamps. Ιδανικό για παρακολούθηση τάσεων design...
Σχετικά Με Web Designer News
Ανακαλύψτε τι προσφέρει το Web Designer News και ποια πολύτιμα δεδομένα μπορούν να εξαχθούν.
Επισκόπηση του Web Designer News
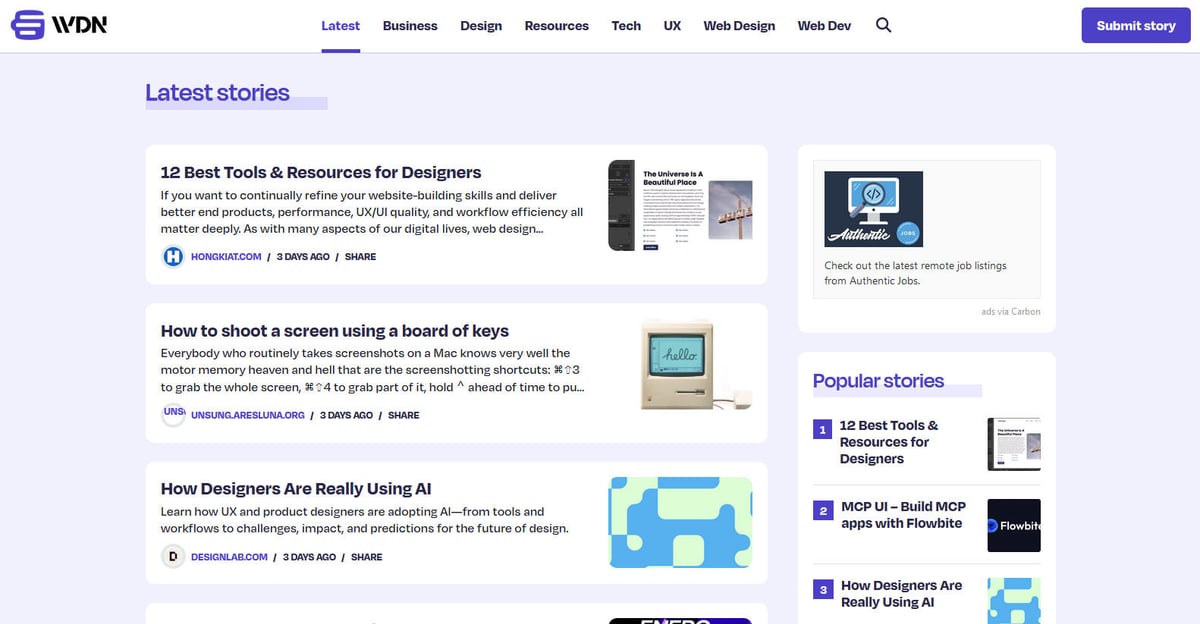
Το Web Designer News είναι ένας κορυφαίος aggregator ειδήσεων που βασίζεται στην κοινότητα, ειδικά σχεδιασμένος για το οικοσύστημα του web design και development. Από την ίδρυσή του, η πλατφόρμα λειτουργεί ως κεντρικός κόμβος όπου οι επαγγελματίες ανακαλύπτουν μια επιλεγμένη συλλογή από τις πιο σχετικές ειδήσεις, tutorials, εργαλεία και πόρους από όλο το διαδίκτυο. Καλύπτει ένα ευρύ φάσμα θεμάτων, συμπεριλαμβανομένων του UX design, της επιχειρηματικής στρατηγικής, των τεχνολογικών ενημερώσεων και του graphic design, παρουσιασμένα σε ένα καθαρό, χρονολογικό feed.
Αρχιτεκτονική Ιστότοπου και Δυνατότητες Δεδομένων
Η αρχιτεκτονική του ιστότοπου βασίζεται στο WordPress, διαθέτοντας μια εξαιρετικά δομημένη διάταξη που οργανώνει το περιεχόμενο σε συγκεκριμένες κατηγορίες όπως 'Web Design', 'Web Dev', 'UX' και 'Resources'. Επειδή συγκεντρώνει δεδομένα από χιλιάδες μεμονωμένα blogs και περιοδικά σε ένα ενιαίο, αναζητήσιμο περιβάλλον, λειτουργεί ως φίλτρο υψηλής ποιότητας για την πληροφόρηση του κλάδου. Αυτή η δομή τον καθιστά ιδανικό στόχο για web scraping, καθώς παρέχει πρόσβαση σε μια προ-ελεγμένη ροή δεδομένων υψηλής αξίας χωρίς την ανάγκη για crawl σε εκατοντάδες ξεχωριστά domains.
Γιατί Να Κάνετε Scraping Το Web Designer News;
Ανακαλύψτε την επιχειρηματική αξία και τις περιπτώσεις χρήσης για την εξαγωγή δεδομένων από το Web Designer News.
Εντοπισμός αναδυόμενων τάσεων και εργαλείων design σε πραγματικό χρόνο.
Αυτοματοποίηση της επιμέλειας ειδήσεων του κλάδου για newsletters και social media feeds.
Διεξαγωγή ανταγωνιστικής ανάλυσης μέσω της παρακολούθησης περιεχομένου από ανταγωνιστές.
Δημιουργία υψηλής ποιότητας datasets για εκπαίδευση Natural Language Processing (NLP).
Δημιουργία μιας κεντρικής βιβλιοθήκης πόρων design για εσωτερικές βάσεις γνώσης ομάδων.
Προκλήσεις Scraping
Τεχνικές προκλήσεις που μπορεί να αντιμετωπίσετε κατά το scraping του Web Designer News.
Χειρισμός τεχνικών ανακατευθύνσεων μέσω του εσωτερικού συστήματος συνδέσμων 'go' του ιστότοπου.
Ασυνεπής διαθεσιμότητα εικόνων thumbnail σε παλαιότερες αρχειοθετημένες αναρτήσεις.
Server-side rate limiting σε αιτήματα υψηλής συχνότητας μέσω προστασίας Nginx.
Κάντε scrape το Web Designer News με AI
Δεν απαιτείται κώδικας. Εξαγάγετε δεδομένα σε λίγα λεπτά με αυτοματισμό AI.
Πώς λειτουργεί
Περιγράψτε τι χρειάζεστε
Πείτε στην AI ποια δεδομένα θέλετε να εξαγάγετε από το Web Designer News. Απλά γράψτε σε φυσική γλώσσα — χωρίς κώδικα ή selectors.
Η AI εξάγει τα δεδομένα
Η τεχνητή νοημοσύνη μας πλοηγείται στο Web Designer News, διαχειρίζεται δυναμικό περιεχόμενο και εξάγει ακριβώς αυτό που ζητήσατε.
Λάβετε τα δεδομένα σας
Λάβετε καθαρά, δομημένα δεδομένα έτοιμα για εξαγωγή ως CSV, JSON ή αποστολή απευθείας στις εφαρμογές σας.
Γιατί να χρησιμοποιήσετε AI για scraping
Η AI καθιστά εύκολο το scraping του Web Designer News χωρίς να γράψετε κώδικα. Η πλατφόρμα μας με τεχνητή νοημοσύνη κατανοεί ποια δεδομένα θέλετε — απλά περιγράψτε τα σε φυσική γλώσσα και η AI τα εξάγει αυτόματα.
How to scrape with AI:
- Περιγράψτε τι χρειάζεστε: Πείτε στην AI ποια δεδομένα θέλετε να εξαγάγετε από το Web Designer News. Απλά γράψτε σε φυσική γλώσσα — χωρίς κώδικα ή selectors.
- Η AI εξάγει τα δεδομένα: Η τεχνητή νοημοσύνη μας πλοηγείται στο Web Designer News, διαχειρίζεται δυναμικό περιεχόμενο και εξάγει ακριβώς αυτό που ζητήσατε.
- Λάβετε τα δεδομένα σας: Λάβετε καθαρά, δομημένα δεδομένα έτοιμα για εξαγωγή ως CSV, JSON ή αποστολή απευθείας στις εφαρμογές σας.
Why use AI for scraping:
- Πλήρης no-code ροή εργασίας για μη τεχνικούς designers και marketers.
- Ο προγραμματισμός στο cloud επιτρέπει την αυτόματη καθημερινή εξαγωγή ειδήσεων.
- Ενσωματωμένος χειρισμός σελιδοποίησης και ανίχνευση δομημένων στοιχείων.
- Άμεση σύνδεση με το Google Sheets για άμεση διανομή δεδομένων.
No-code web scrapers για το Web Designer News
Εναλλακτικές point-and-click στο AI-powered scraping
Διάφορα no-code εργαλεία όπως Browse.ai, Octoparse, Axiom και ParseHub μπορούν να σας βοηθήσουν να κάνετε scraping στο Web Designer News χωρίς να γράψετε κώδικα. Αυτά τα εργαλεία συνήθως χρησιμοποιούν οπτικές διεπαφές για επιλογή δεδομένων, αν και μπορεί να δυσκολευτούν με σύνθετο δυναμικό περιεχόμενο ή μέτρα anti-bot.
Τυπική ροή εργασίας με no-code εργαλεία
Συνήθεις προκλήσεις
Καμπύλη μάθησης
Η κατανόηση επιλογέων και λογικής εξαγωγής απαιτεί χρόνο
Οι επιλογείς χαλάνε
Οι αλλαγές στον ιστότοπο μπορούν να χαλάσουν ολόκληρη τη ροή εργασίας
Προβλήματα δυναμικού περιεχομένου
Ιστότοποι με πολύ JavaScript απαιτούν σύνθετες λύσεις
Περιορισμοί CAPTCHA
Τα περισσότερα εργαλεία απαιτούν χειροκίνητη παρέμβαση για CAPTCHA
Αποκλεισμός IP
Το επιθετικό scraping μπορεί να οδηγήσει σε αποκλεισμό της IP σας
No-code web scrapers για το Web Designer News
Διάφορα no-code εργαλεία όπως Browse.ai, Octoparse, Axiom και ParseHub μπορούν να σας βοηθήσουν να κάνετε scraping στο Web Designer News χωρίς να γράψετε κώδικα. Αυτά τα εργαλεία συνήθως χρησιμοποιούν οπτικές διεπαφές για επιλογή δεδομένων, αν και μπορεί να δυσκολευτούν με σύνθετο δυναμικό περιεχόμενο ή μέτρα anti-bot.
Τυπική ροή εργασίας με no-code εργαλεία
- Εγκαταστήστε την επέκταση του προγράμματος περιήγησης ή εγγραφείτε στην πλατφόρμα
- Πλοηγηθείτε στον ιστότοπο-στόχο και ανοίξτε το εργαλείο
- Επιλέξτε στοιχεία δεδομένων για εξαγωγή με point-and-click
- Διαμορφώστε επιλογείς CSS για κάθε πεδίο δεδομένων
- Ρυθμίστε κανόνες σελιδοποίησης για scraping πολλών σελίδων
- Διαχειριστείτε CAPTCHA (συχνά απαιτεί χειροκίνητη επίλυση)
- Διαμορφώστε προγραμματισμό για αυτόματες εκτελέσεις
- Εξαγωγή δεδομένων σε CSV, JSON ή σύνδεση μέσω API
Συνήθεις προκλήσεις
- Καμπύλη μάθησης: Η κατανόηση επιλογέων και λογικής εξαγωγής απαιτεί χρόνο
- Οι επιλογείς χαλάνε: Οι αλλαγές στον ιστότοπο μπορούν να χαλάσουν ολόκληρη τη ροή εργασίας
- Προβλήματα δυναμικού περιεχομένου: Ιστότοποι με πολύ JavaScript απαιτούν σύνθετες λύσεις
- Περιορισμοί CAPTCHA: Τα περισσότερα εργαλεία απαιτούν χειροκίνητη παρέμβαση για CAPTCHA
- Αποκλεισμός IP: Το επιθετικό scraping μπορεί να οδηγήσει σε αποκλεισμό της IP σας
Παραδείγματα κώδικα
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
url = 'https://webdesignernews.com/'
try:
# Αποστολή αιτήματος στην κύρια σελίδα
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Εντοπισμός containers αναρτήσεων
posts = soup.find_all('div', class_='single-post')
for post in posts:
title = post.find('h3').get_text(strip=True)
# Έλεγχος αν υπάρχει το όνομα του ιστότοπου πηγής
source = post.find('span', class_='site_name').get_text(strip=True) if post.find('span', class_='site_name') else 'Unknown'
link = post.find('h3').find('a')['href']
print(f'Title: {title} | Source: {source} | Link: {link}')
except Exception as e:
print(f'Παρουσιάστηκε σφάλμα: {e}')Πότε να χρησιμοποιήσετε
Ιδανικό για στατικές HTML σελίδες με ελάχιστη JavaScript. Τέλειο για blogs, ειδησεογραφικά sites και απλές σελίδες προϊόντων e-commerce.
Πλεονεκτήματα
- ●Ταχύτερη εκτέλεση (χωρίς overhead browser)
- ●Χαμηλότερη κατανάλωση πόρων
- ●Εύκολη παραλληλοποίηση με asyncio
- ●Εξαιρετικό για APIs και στατικές σελίδες
Περιορισμοί
- ●Δεν μπορεί να εκτελέσει JavaScript
- ●Αποτυγχάνει σε SPAs και δυναμικό περιεχόμενο
- ●Μπορεί να δυσκολευτεί με σύνθετα συστήματα anti-bot
Πώς να κάνετε scraping στο Web Designer News με κώδικα
Python + Requests
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
url = 'https://webdesignernews.com/'
try:
# Αποστολή αιτήματος στην κύρια σελίδα
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Εντοπισμός containers αναρτήσεων
posts = soup.find_all('div', class_='single-post')
for post in posts:
title = post.find('h3').get_text(strip=True)
# Έλεγχος αν υπάρχει το όνομα του ιστότοπου πηγής
source = post.find('span', class_='site_name').get_text(strip=True) if post.find('span', class_='site_name') else 'Unknown'
link = post.find('h3').find('a')['href']
print(f'Title: {title} | Source: {source} | Link: {link}')
except Exception as e:
print(f'Παρουσιάστηκε σφάλμα: {e}')Python + Playwright
from playwright.sync_api import sync_playwright
def scrape_wdn():
with sync_playwright() as p:
# Εκκίνηση headless browser
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto('https://webdesignernews.com/')
# Αναμονή για τη φόρτωση των στοιχείων της ανάρτησης
page.wait_for_selector('.single-post')
posts = page.query_selector_all('.single-post')
for post in posts:
title_el = post.query_selector('h3 a')
if title_el:
title = title_el.inner_text()
link = title_el.get_attribute('href')
print(f'Scraped: {title} - {link}')
browser.close()
scrape_wdn()Python + Scrapy
import scrapy
class WdnSpider(scrapy.Spider):
name = 'wdn_spider'
start_urls = ['https://webdesignernews.com/']
def parse(self, response):
# Εξαγωγή κάθε ανάρτησης από το feed
for post in response.css('.single-post'):
yield {
'title': post.css('h3 a::text').get(),
'source': post.css('.site_name::text').get(),
'link': post.css('h3 a::attr(href)').get()
}
# Χειρισμός σελιδοποίησης βρίσκοντας τον σύνδεσμο 'Next'
next_page = response.css('a.next::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://webdesignernews.com/', { waitUntil: 'domcontentloaded' });
// Αξιολόγηση της σελίδας για την εξαγωγή πεδίων δεδομένων
const results = await page.evaluate(() => {
const items = Array.from(document.querySelectorAll('.single-post'));
return items.map(item => ({
title: item.querySelector('h3 a') ? item.querySelector('h3 a').innerText : null,
source: item.querySelector('.site_name') ? item.querySelector('.site_name').innerText : null,
link: item.querySelector('h3 a') ? item.querySelector('h3 a').href : null
}));
});
console.log(results);
await browser.close();
})();Τι Μπορείτε Να Κάνετε Με Τα Δεδομένα Του Web Designer News
Εξερευνήστε πρακτικές εφαρμογές και πληροφορίες από τα δεδομένα του Web Designer News.
Αυτοματοποιημένο Feed Ειδήσεων Design
Δημιουργήστε ένα ζωντανό, επιμελημένο κανάλι ειδήσεων για επαγγελματικές ομάδες design μέσω Slack ή Discord.
Πώς να υλοποιήσετε:
- 1Κάντε scrape τις κορυφαίες ιστορίες κάθε 4 ώρες.
- 2Φιλτράρετε τα αποτελέσματα με βάση σχετικά tags κατηγοριών όπως 'UX' ή 'Web Dev'.
- 3Στείλτε τους εξαγόμενους τίτλους και περιλήψεις σε ένα messaging webhook.
- 4Αρχειοθετήστε τα δεδομένα για να παρακολουθείτε τη μακροπρόθεσμη δημοτικότητα των εργαλείων του κλάδου.
Χρησιμοποιήστε το Automatio για να εξάγετε δεδομένα από το Web Designer News και να δημιουργήσετε αυτές τις εφαρμογές χωρίς να γράψετε κώδικα.
Τι Μπορείτε Να Κάνετε Με Τα Δεδομένα Του Web Designer News
- Αυτοματοποιημένο Feed Ειδήσεων Design
Δημιουργήστε ένα ζωντανό, επιμελημένο κανάλι ειδήσεων για επαγγελματικές ομάδες design μέσω Slack ή Discord.
- Κάντε scrape τις κορυφαίες ιστορίες κάθε 4 ώρες.
- Φιλτράρετε τα αποτελέσματα με βάση σχετικά tags κατηγοριών όπως 'UX' ή 'Web Dev'.
- Στείλτε τους εξαγόμενους τίτλους και περιλήψεις σε ένα messaging webhook.
- Αρχειοθετήστε τα δεδομένα για να παρακολουθείτε τη μακροπρόθεσμη δημοτικότητα των εργαλείων του κλάδου.
- Tracker Τάσεων Εργαλείων Design
Εντοπίστε ποια λογισμικά design ή βιβλιοθήκες αποκτούν τη μεγαλύτερη απήχηση στην κοινότητα.
- Εξαγάγετε τίτλους και αποσπάσματα από το αρχείο της κατηγορίας 'Resources'.
- Πραγματοποιήστε ανάλυση συχνότητας λέξεων-κλειδιών σε συγκεκριμένους όρους (π.χ. 'Figma', 'React').
- Συγκρίνετε την αύξηση των αναφορών μήνα με το μήνα για να εντοπίσετε τις ανερχόμενες τάσεις.
- Εξαγάγετε οπτικές αναφορές για ομάδες marketing ή στρατηγικής προϊόντων.
- Παρακολούθηση Backlink Ανταγωνιστών
Εντοπίστε ποια blogs ή agencies τοποθετούν με επιτυχία περιεχόμενο σε μεγάλους κόμβους.
- Κάντε scrape το πεδίο 'Source Website Name' για όλες τις ιστορικές καταχωρίσεις.
- Συγκεντρώστε τον αριθμό αναφορών ανά εξωτερικό domain για να δείτε ποιο εμφανίζεται συχνότερα.
- Αναλύστε τους τύπους περιεχομένου που γίνονται αποδεκτοί για καλύτερη προσέγγιση (outreach).
- Εντοπίστε πιθανούς συνεργάτες στον χώρο του design.
- Dataset Εκπαίδευσης Machine learning
Χρησιμοποιήστε τα επιμελημένα αποσπάσματα και τις περιλήψεις για να εκπαιδεύσετε τεχνικά summarization model.
- Κάντε scrape 10.000+ τίτλους ιστοριών και τις αντίστοιχες περιλήψεις αποσπασμάτων.
- Καθαρίστε τα δεδομένα κειμένου για να αφαιρέσετε εσωτερικές παραμέτρους παρακολούθησης και HTML.
- Χρησιμοποιήστε τον τίτλο ως στόχο και το απόσπασμα ως είσοδο για fine-tuning.
- Δοκιμάστε το model σε νέα άρθρα design για αξιολόγηση απόδοσης.
Ενισχύστε τη ροή εργασίας σας με Αυτοματισμό AI
Το Automatio συνδυάζει τη δύναμη των AI agents, του web automation και των έξυπνων ενσωματώσεων για να σας βοηθήσει να επιτύχετε περισσότερα σε λιγότερο χρόνο.
Επαγγελματικές Συμβουλές Για Το Scraping Του Web Designer News
Συμβουλές ειδικών για επιτυχημένη εξαγωγή δεδομένων από το Web Designer News.
Στοχεύστε στο WordPress REST API endpoint (/wp-json/wp/v2/posts) για ταχύτερα και πιο αξιόπιστα δομημένα δεδομένα σε σύγκριση με το HTML parsing.
Παρακολουθήστε το RSS feed του ιστότοπου στο webdesignernews.com/feed/ για να εντοπίζετε νέες ιστορίες τη στιγμή που δημοσιεύονται.
Προγραμματίστε τις εργασίες scraping για τις 9
00 AM EST ώστε να ευθυγραμμιστούν με την καθημερινή κορύφωση του περιεχομένου που υποβάλλεται από την κοινότητα.
Κάντε rotate τα User-Agent strings και εφαρμόστε καθυστέρηση 2 δευτερολέπτων μεταξύ των αιτημάτων για να αποφύγετε την ενεργοποίηση των Nginx rate limits.
Πάντα να επιλύετε τους εσωτερικούς συνδέσμους '/go/' ακολουθώντας τα redirects για να εξαγάγετε το τελικό canonical source URL.
Καθαρίστε τα δεδομένα κειμένου των αποσπασμάτων αφαιρώντας τα HTML tags και τα αποσιωπητικά στο τέλος για καλύτερα αποτελέσματα ανάλυσης.
Μαρτυρίες
Τι λένε οι χρήστες μας
Ενταχθείτε στις χιλιάδες ικανοποιημένων χρηστών που έχουν μεταμορφώσει τη ροή εργασίας τους
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Σχετικά Web Scraping




Συχνές ερωτήσεις για Web Designer News
Βρείτε απαντήσεις σε συνηθισμένες ερωτήσεις σχετικά με το Web Designer News