Cómo realizar scraping de paquetes turísticos y reseñas de Thrillophilia
Aprende cómo realizar scraping en Thrillophilia para extraer precios de paquetes turísticos, itinerarios y reseñas de clientes. Datos de viajes de alta calidad...
Protección Anti-Bot Detectada
- Cloudflare
- WAF y gestión de bots de nivel empresarial. Usa desafíos JavaScript, CAPTCHAs y análisis de comportamiento. Requiere automatización de navegador con configuración sigilosa.
- Limitación de velocidad
- Limita solicitudes por IP/sesión en el tiempo. Se puede eludir con proxies rotativos, retrasos en solicitudes y scraping distribuido.
- Bloqueo de IP
- Bloquea IPs de centros de datos conocidos y direcciones marcadas. Requiere proxies residenciales o móviles para eludir efectivamente.
- Huella del navegador
- Identifica bots por características del navegador: canvas, WebGL, fuentes, plugins. Requiere spoofing o perfiles de navegador reales.
Acerca de Thrillophilia
Descubre qué ofrece Thrillophilia y qué datos valiosos se pueden extraer.
El destino principal para experiencias de viaje
Thrillophilia es una destacada plataforma de viajes y aventura con sede en la India que ofrece paquetes turísticos integrales dirigidos por expertos en todo el mundo. Se especializa en experiencias de viaje seleccionadas que van desde expediciones al Himalaya y tours de patrimonio en Rajasthan hasta escapadas internacionales en Europa, el sudeste asiático y el Medio Oriente.
Riqueza y valor de los datos
La plataforma cuenta con listados detallados de tours de varios días, paquetes de luna de miel y aventuras grupales. Los listados en Thrillophilia contienen una gran cantidad de datos estructurados, incluyendo itinerarios específicos, detalles de estancia noche por noche, precios con descuento, calificaciones de usuarios y reseñas descriptivas. Esta información es sumamente valiosa para agencias de viajes e investigadores de mercado.
Por qué es importante para el análisis de datos
Para las empresas del sector de viajes, realizar scraping de Thrillophilia proporciona una ventaja competitiva. Al monitorear las fluctuaciones de precios y el sentimiento del cliente a través de las reseñas, las empresas pueden optimizar sus propias ofertas e identificar tendencias de viaje emergentes antes de que se vuelvan populares.
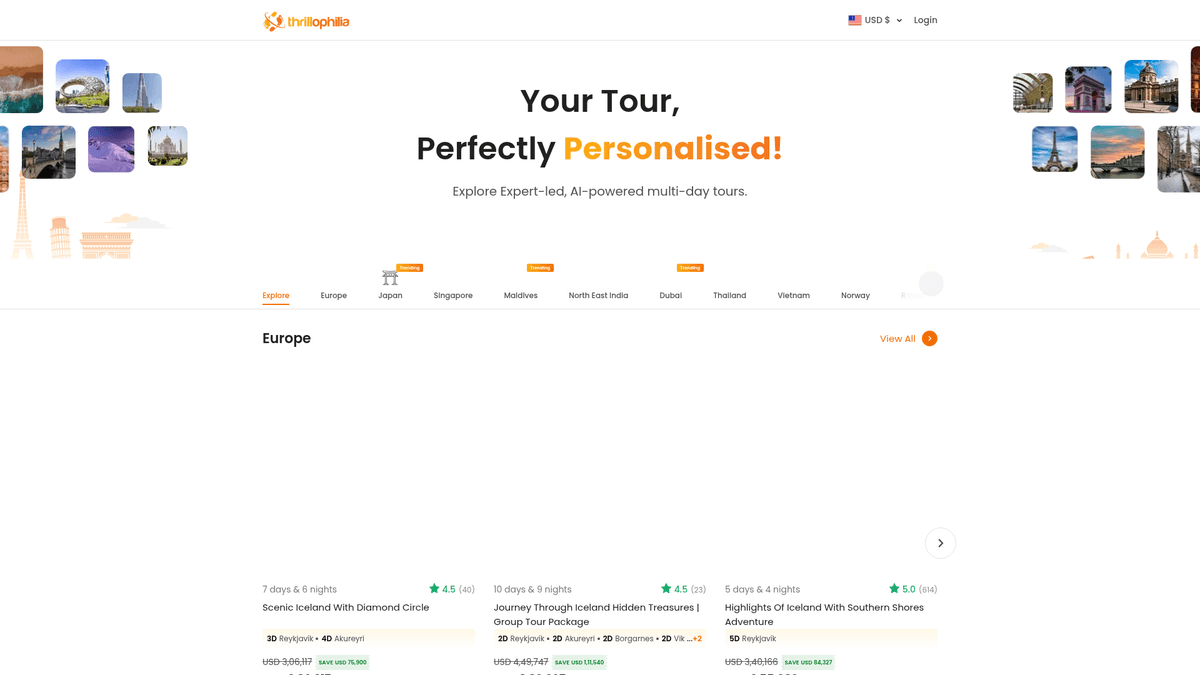
¿Por Qué Scrapear Thrillophilia?
Descubre el valor comercial y los casos de uso para extraer datos de Thrillophilia.
Inteligencia de Precios en Tiempo Real
Monitorea las fluctuaciones dinámicas de precios y los descuentos estacionales en Thrillophilia para asegurar que tus propias ofertas de viajes sigan siendo competitivas en el mercado.
Benchmarking de Itinerarios
Extrae planes detallados día a día y listas de inclusiones para analizar cómo los principales operadores turísticos estructuran sus experiencias y utiliza estos datos para mejorar tus propios productos.
Análisis de Sentimiento y Reseñas
Recopila miles de reseñas de usuarios para realizar análisis de sentimiento, identificando puntos críticos comunes para los viajeros y atracciones populares en diferentes segmentos demográficos.
Identificación de Tendencias de Mercado
Rastrea la frecuencia de nuevos listados y volúmenes de reseñas para destinos específicos con el fin de identificar puntos turísticos emergentes antes de que se vuelvan populares.
Seguimiento del Rendimiento de Operadores
Identifica y evalúa a los proveedores de servicios locales y operadores turísticos mencionados en los listados para construir una base de datos de socios comerciales potenciales de alta calidad.
Desafíos de Scraping
Desafíos técnicos que puedes encontrar al scrapear Thrillophilia.
Gestión de Bots de Cloudflare
Thrillophilia emplea una protección agresiva de Cloudflare que puede detectar y bloquear solicitudes automatizadas estándar mediante el fingerprinting del navegador y comprobaciones de reputación de IP.
Renderizado de Contenido Dinámico
El sitio web está construido con Next.js, lo que significa que datos cruciales como precios e itinerarios a menudo se inyectan mediante JavaScript después de la carga inicial de la página, requiriendo un navegador headless.
Paginación Interactiva
En lugar de las tradicionales páginas numeradas, muchas secciones de listados utilizan un botón de 'Cargar más productos' que requiere interacción activa del navegador para revelar el catálogo completo de tours.
Extracción de Datos Anidados
Los itinerarios de los tours suelen almacenarse en estructuras HTML anidadas complejas (Día 1, Día 2, etc.), lo que dificulta mantener un mapeo de datos limpio sin selectores avanzados.
Scrapea Thrillophilia con IA
Sin código necesario. Extrae datos en minutos con automatización impulsada por IA.
Cómo Funciona
Describe lo que necesitas
Dile a la IA qué datos quieres extraer de Thrillophilia. Solo escríbelo en lenguaje natural — sin código ni selectores.
La IA extrae los datos
Nuestra inteligencia artificial navega Thrillophilia, maneja contenido dinámico y extrae exactamente lo que pediste.
Obtén tus datos
Recibe datos limpios y estructurados listos para exportar como CSV, JSON o enviar directamente a tus aplicaciones.
Por Qué Usar IA para el Scraping
La IA facilita el scraping de Thrillophilia sin escribir código. Nuestra plataforma impulsada por inteligencia artificial entiende qué datos quieres — solo descríbelo en lenguaje natural y la IA los extrae automáticamente.
How to scrape with AI:
- Describe lo que necesitas: Dile a la IA qué datos quieres extraer de Thrillophilia. Solo escríbelo en lenguaje natural — sin código ni selectores.
- La IA extrae los datos: Nuestra inteligencia artificial navega Thrillophilia, maneja contenido dinámico y extrae exactamente lo que pediste.
- Obtén tus datos: Recibe datos limpios y estructurados listos para exportar como CSV, JSON o enviar directamente a tus aplicaciones.
Why use AI for scraping:
- Bypass Automatizado de Anti-Bot: Automatio gestiona desafíos complejos como Cloudflare y el fingerprinting del navegador de forma automática, asegurando que tus scrapers funcionen sin intervención manual constante.
- Gestión Visual de Paginación: Configura fácilmente la herramienta para hacer clic en los botones de 'Cargar más' o navegar a través de enlaces anidados visualmente, eliminando la necesidad de scripts de bucle complejos.
- Extracción Preparada para JavaScript: Dado que Automatio actúa como un navegador real, espera a que los componentes de Next.js se hidraten por completo, capturando precios finales y detalles del itinerario con precisión en todo momento.
- Exportación de Datos Estructurados: Transforma automáticamente detalles complejos de tours en formatos CSV o JSON limpios y estructurados, listos para su uso inmediato en tus bases de datos internas o AI models.
Scrapers Sin Código para Thrillophilia
Alternativas de apuntar y clic al scraping con IA
Varias herramientas sin código como Browse.ai, Octoparse, Axiom y ParseHub pueden ayudarte a scrapear Thrillophilia. Estas herramientas usan interfaces visuales para seleccionar elementos, pero tienen desventajas comparadas con soluciones con IA.
Flujo de Trabajo Típico con Herramientas Sin Código
Desafíos Comunes
Curva de aprendizaje
Comprender selectores y lógica de extracción lleva tiempo
Los selectores se rompen
Los cambios en el sitio web pueden romper todo el flujo de trabajo
Problemas con contenido dinámico
Los sitios con mucho JavaScript requieren soluciones complejas
Limitaciones de CAPTCHA
La mayoría de herramientas requieren intervención manual para CAPTCHAs
Bloqueo de IP
El scraping agresivo puede resultar en el bloqueo de tu IP
Scrapers Sin Código para Thrillophilia
Varias herramientas sin código como Browse.ai, Octoparse, Axiom y ParseHub pueden ayudarte a scrapear Thrillophilia. Estas herramientas usan interfaces visuales para seleccionar elementos, pero tienen desventajas comparadas con soluciones con IA.
Flujo de Trabajo Típico con Herramientas Sin Código
- Instalar extensión del navegador o registrarse en la plataforma
- Navegar al sitio web objetivo y abrir la herramienta
- Seleccionar con point-and-click los elementos de datos a extraer
- Configurar selectores CSS para cada campo de datos
- Configurar reglas de paginación para scrapear múltiples páginas
- Resolver CAPTCHAs (frecuentemente requiere intervención manual)
- Configurar programación para ejecuciones automáticas
- Exportar datos a CSV, JSON o conectar vía API
Desafíos Comunes
- Curva de aprendizaje: Comprender selectores y lógica de extracción lleva tiempo
- Los selectores se rompen: Los cambios en el sitio web pueden romper todo el flujo de trabajo
- Problemas con contenido dinámico: Los sitios con mucho JavaScript requieren soluciones complejas
- Limitaciones de CAPTCHA: La mayoría de herramientas requieren intervención manual para CAPTCHAs
- Bloqueo de IP: El scraping agresivo puede resultar en el bloqueo de tu IP
Ejemplos de Código
import requests
from bs4 import BeautifulSoup
# Thrillophilia uses Cloudflare, so standard requests might fail without proper headers or session management
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
url = 'https://www.thrillophilia.com/destinations/bali/tours'
def scrape_thrill(url):
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Selectors vary based on specific destination pages
tours = soup.select('.tour-card')
for tour in tours:
title = tour.find('h3').text.strip()
price = tour.select_one('.price-value').text.strip() if tour.select_one('.price-value') else 'N/A'
print(f'Tour: {title} | Price: {price}')
except Exception as e:
print(f'Error occurred: {e}')
scrape_thrill(url)Cuándo Usar
Mejor para páginas HTML estáticas donde el contenido se carga del lado del servidor. El enfoque más rápido y simple cuando no se requiere renderizado de JavaScript.
Ventajas
- ●Ejecución más rápida (sin sobrecarga del navegador)
- ●Menor consumo de recursos
- ●Fácil de paralelizar con asyncio
- ●Excelente para APIs y páginas estáticas
Limitaciones
- ●No puede ejecutar JavaScript
- ●Falla en SPAs y contenido dinámico
- ●Puede tener dificultades con sistemas anti-bot complejos
Cómo Scrapear Thrillophilia con Código
Python + Requests
import requests
from bs4 import BeautifulSoup
# Thrillophilia uses Cloudflare, so standard requests might fail without proper headers or session management
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
url = 'https://www.thrillophilia.com/destinations/bali/tours'
def scrape_thrill(url):
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Selectors vary based on specific destination pages
tours = soup.select('.tour-card')
for tour in tours:
title = tour.find('h3').text.strip()
price = tour.select_one('.price-value').text.strip() if tour.select_one('.price-value') else 'N/A'
print(f'Tour: {title} | Price: {price}')
except Exception as e:
print(f'Error occurred: {e}')
scrape_thrill(url)Python + Playwright
from playwright.sync_api import sync_playwright
def run():
with sync_playwright() as p:
# Launching with a real browser profile helps bypass basic detections
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto('https://www.thrillophilia.com/destinations/egypt/tours', wait_until='networkidle')
# Wait for tour cards to load dynamically
page.wait_for_selector('.tour-card')
tours = page.query_selector_all('.tour-card')
for tour in tours:
title = tour.query_selector('h3').inner_text()
print(f'Extracted: {title}')
browser.close()
run()Python + Scrapy
import scrapy
class ThrillSpider(scrapy.Spider):
name = 'thrillophilia'
start_urls = ['https://www.thrillophilia.com/destinations/japan/tours']
def parse(self, response):
for tour in response.css('.tour-card'):
yield {
'title': tour.css('h3::text').get(),
'price': tour.css('.current-price::text').get(),
'rating': tour.css('.rating-value::text').get()
}
# Handling pagination
next_page = response.css('a.next-page::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.thrillophilia.com/destinations/maldives');
// Execute script in browser context to extract data
const tours = await page.evaluate(() => {
const items = document.querySelectorAll('.tour-card');
return Array.from(items).map(item => ({
title: item.querySelector('h3')?.innerText,
price: item.querySelector('.price')?.innerText
}));
});
console.log(tours);
await browser.close();
})();Qué Puedes Hacer Con Los Datos de Thrillophilia
Explora aplicaciones prácticas e insights de los datos de Thrillophilia.
Monitoreo dinámico de precios
Monitoree los precios de las actividades diariamente para ajustar las estrategias de precios competitivos.
Cómo implementar:
- 1Realizar scraping de los precios de los tours diariamente para los destinos principales
- 2Almacenar datos históricos en una base de datos SQL
- 3Configurar alertas para caídas de precios superiores al 15%
- 4Sincronizar con el CRM interno para actualizar sus propios precios
Usa Automatio para extraer datos de Thrillophilia y crear estas aplicaciones sin escribir código.
Qué Puedes Hacer Con Los Datos de Thrillophilia
- Monitoreo dinámico de precios
Monitoree los precios de las actividades diariamente para ajustar las estrategias de precios competitivos.
- Realizar scraping de los precios de los tours diariamente para los destinos principales
- Almacenar datos históricos en una base de datos SQL
- Configurar alertas para caídas de precios superiores al 15%
- Sincronizar con el CRM interno para actualizar sus propios precios
- Análisis de sentimiento en reseñas
Analice miles de reseñas para comprender los puntos críticos de los viajeros.
- Extraer todos los textos de reseñas y calificaciones
- Aplicar modelos de NLP para categorizar el sentimiento
- Identificar palabras clave específicas relacionadas con 'seguridad' o 'retrasos'
- Generar informes para la mejora del servicio
- Descubrimiento de tendencias en itinerarios
Utilice los datos de itinerarios para diseñar nuevos paquetes turísticos que sigan las tendencias del mercado.
- Realizar scraping del desglose noche por noche de los tours más vendidos
- Identificar patrones comunes de hoteles y actividades
- Comparar la popularidad de los destinos en diferentes regiones
- Diseñar nuevos productos basados en estructuras de itinerarios de alto rendimiento
- Generación de leads para equipo de viaje
Identifique actividades populares para dirigir las ventas de equipo a grupos demográficos específicos.
- Rastrear los tipos de aventura más reservados (ej. trekking vs. lujo)
- Correlacionar la popularidad de la actividad con las tendencias estacionales
- Dirigir campañas de marketing de equipo basadas en etiquetas de actividad de destino
- Verificación de operadores turísticos
Monitoree qué operadores reciben calificaciones altas de manera constante en toda la plataforma.
- Extraer nombres de operadores y sus puntuaciones de calificación promedio
- Rastrear el volumen de tours manejados por cada operador
- Evaluar socios potenciales para su propia red de agencias de viajes
Potencia tu flujo de trabajo con Automatizacion IA
Automatio combina el poder de agentes de IA, automatizacion web e integraciones inteligentes para ayudarte a lograr mas en menos tiempo.
Consejos Pro para Scrapear Thrillophilia
Consejos expertos para extraer datos exitosamente de Thrillophilia.
Priorizar Proxies Residenciales
Para evitar ser detectado por los sistemas de seguridad de Thrillophilia, utiliza proxies residenciales de alta calidad que imiten el tráfico de usuarios reales en lugar de IPs de centros de datos.
Extraer el Script NEXT_DATA
Busca en el código fuente de la página una etiqueta de script que contenga __NEXT_DATA__; a menudo contiene un objeto JSON completo con los datos de la página, lo cual puede ser mucho más rápido de procesar.
Implementar Retrasos Aleatorios
Configura tiempos de espera aleatorios entre interacciones para imitar los patrones de navegación humana y reducir la probabilidad de activar límites de frecuencia o desafíos de seguridad.
Gestionar Imágenes con Lazy-Loading
Muchas imágenes solo se cargan cuando entran en el viewport; asegúrate de que tu scraper se desplace por la página para capturar correctamente todas las URLs de las fotos del tour.
Normalizar Divisa y Precio
Los precios pueden cambiar según la ubicación de tu proxy. Extrae siempre el código de divisa junto con el valor numérico para evitar inconsistencias en los datos.
Testimonios
Lo Que Dicen Nuestros Usuarios
Unete a miles de usuarios satisfechos que han transformado su flujo de trabajo
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Relacionados Web Scraping
Preguntas Frecuentes Sobre Thrillophilia
Encuentra respuestas a preguntas comunes sobre Thrillophilia