چگونه دادههای Web Designer News را scrape کنیم
بیاموزید چگونه Web Designer News را برای استخراج داستانهای ترند طراحی، URLهای منبع و برچسبهای زمانی scrape کنید. عالی برای مانیتورینگ ترندهای طراحی و محتوا.
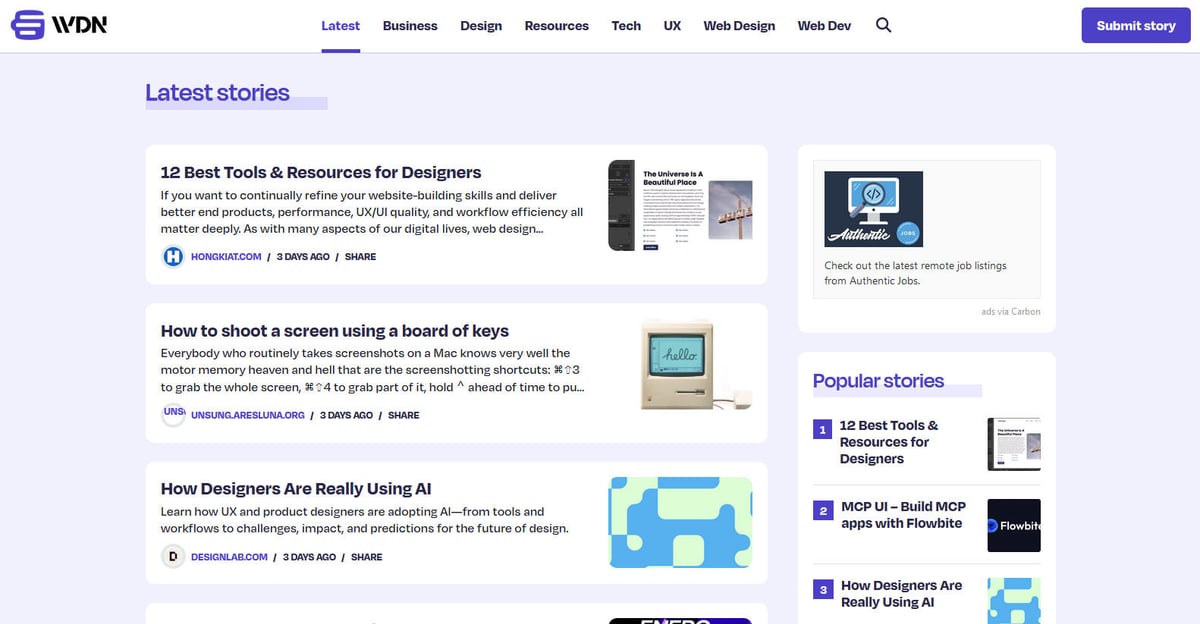
درباره Web Designer News
کشف کنید Web Designer News چه چیزی ارائه میدهد و چه دادههای ارزشمندی میتوان استخراج کرد.
نمای کلی Web Designer News
سایت Web Designer News یک منبع برتر جمعآوری اخبار جامعهمحور است که بهطور خاص برای اکوسیستم طراحی و توسعه وب کیوریت شده است. از زمان شروع به کار، این پلتفرم به عنوان یک مرکز اصلی عمل کرده که در آن متخصصان مجموعهای دستچین شده از مرتبطترین داستانهای خبری، آموزشها، ابزارها و منابع را از سراسر اینترنت کشف میکنند. این سایت طیف گستردهای از موضوعات از جمله طراحی UX، استراتژی کسبوکار، بهروزرسانیهای فناوری و طراحی گرافیک را در یک فید تمیز و بر اساس زمان ارائه میدهد.
معماری وبسایت و پتانسیل دادهها
معماری وبسایت بر پایه WordPress بنا شده است و دارای یک چیدمان بسیار ساختاریافته است که محتوا را در دستهبندیهای خاصی مانند 'Web Design'، 'Web Dev'، 'UX' و 'Resources' سازماندهی میکند. از آنجایی که این سایت دادهها را از هزاران وبلاگ و مجله جداگانه در یک رابط واحد و قابل جستجو جمعآوری میکند، به عنوان یک فیلتر باکیفیت برای هوشمندی صنعت عمل میکند. این ساختار آن را به هدفی ایدهآل برای web scraping تبدیل میکند، زیرا دسترسی به جریانی از دادههای ارزشمند صنعت را بدون نیاز به خزش در صدها دامنه جداگانه فراهم میسازد.
چرا Web Designer News را اسکرپ کنیم؟
ارزش تجاری و موارد استفاده برای استخراج داده از Web Designer News را کشف کنید.
شناسایی ترندها و ابزارهای نوظهور طراحی در زمان واقعی.
خودکارسازی کیوریتوری اخبار صنعت برای خبرنامهها و فیدهای شبکههای اجتماعی.
انجام تحلیل رقابتی با مانیتورینگ محتوای برجسته شده از رقبا.
تولید مجموعه دادههای باکیفیت برای آموزش پردازش زبان طبیعی (NLP).
ساخت یک کتابخانه متمرکز از منابع طراحی برای پایگاههای دانش تیم داخلی.
چالشهای اسکرپینگ
چالشهای فنی که ممکن است هنگام اسکرپ Web Designer News با آنها مواجه شوید.
مدیریت ریدایرکتهای فنی از طریق سیستم لینک داخلی 'go' سایت.
عدم دسترسی مداوم به تصاویر بندانگشتی در پستهای آرشیو شده قدیمیتر.
محدودیت نرخ (rate limiting) سمت سرور برای درخواستهای با فرکانس بالا از طریق محافظت Nginx.
استخراج داده از Web Designer News با هوش مصنوعی
بدون نیاز به کدنویسی. با اتوماسیون مبتنی بر هوش مصنوعی در چند دقیقه داده استخراج کنید.
نحوه عملکرد
نیاز خود را توصیف کنید
به هوش مصنوعی بگویید چه دادههایی را میخواهید از Web Designer News استخراج کنید. فقط به زبان طبیعی بنویسید — بدون نیاز به کد یا سلکتور.
هوش مصنوعی دادهها را استخراج میکند
هوش مصنوعی ما Web Designer News را مرور میکند، محتوای پویا را مدیریت میکند و دقیقاً آنچه درخواست کردهاید را استخراج میکند.
دادههای خود را دریافت کنید
دادههای تمیز و ساختاریافته آماده برای صادرات به CSV، JSON یا ارسال مستقیم به برنامههای شما دریافت کنید.
چرا از هوش مصنوعی برای استخراج داده استفاده کنید
هوش مصنوعی استخراج داده از Web Designer News را بدون نوشتن کد آسان میکند. پلتفرم ما با هوش مصنوعی میفهمد چه دادههایی میخواهید — فقط به زبان طبیعی توصیف کنید و هوش مصنوعی به طور خودکار استخراج میکند.
How to scrape with AI:
- نیاز خود را توصیف کنید: به هوش مصنوعی بگویید چه دادههایی را میخواهید از Web Designer News استخراج کنید. فقط به زبان طبیعی بنویسید — بدون نیاز به کد یا سلکتور.
- هوش مصنوعی دادهها را استخراج میکند: هوش مصنوعی ما Web Designer News را مرور میکند، محتوای پویا را مدیریت میکند و دقیقاً آنچه درخواست کردهاید را استخراج میکند.
- دادههای خود را دریافت کنید: دادههای تمیز و ساختاریافته آماده برای صادرات به CSV، JSON یا ارسال مستقیم به برنامههای شما دریافت کنید.
Why use AI for scraping:
- گردش کار کاملاً بدون کد (no-code) برای طراحان و بازاریابان غیرفنی.
- زمانبندی مبتنی بر ابری که امکان استخراج خودکار اخبار روزانه را فراهم میکند.
- مدیریت داخلی صفحهبندی (pagination) و تشخیص عناصر ساختاریافته.
- ادغام مستقیم با Google Sheets برای توزیع فوری دادهها.
اسکرپرهای وب بدون کد برای Web Designer News
جایگزینهای کلیک و انتخاب برای اسکرپینگ مبتنی بر AI
چندین ابزار بدون کد مانند Browse.ai، Octoparse، Axiom و ParseHub میتوانند به شما در اسکرپ Web Designer News بدون نوشتن کد کمک کنند. این ابزارها معمولاً از رابطهای بصری برای انتخاب داده استفاده میکنند، اگرچه ممکن است با محتوای پویای پیچیده یا اقدامات ضد ربات مشکل داشته باشند.
گردش کار معمول با ابزارهای بدون کد
چالشهای رایج
منحنی یادگیری
درک انتخابگرها و منطق استخراج زمان میبرد
انتخابگرها خراب میشوند
تغییرات وبسایت میتواند کل جریان کار را خراب کند
مشکلات محتوای پویا
سایتهای پر از JavaScript نیاز به راهحلهای پیچیده دارند
محدودیتهای CAPTCHA
اکثر ابزارها نیاز به مداخله دستی برای CAPTCHA دارند
مسدود شدن IP
استخراج تهاجمی میتواند منجر به مسدود شدن IP شما شود
اسکرپرهای وب بدون کد برای Web Designer News
چندین ابزار بدون کد مانند Browse.ai، Octoparse، Axiom و ParseHub میتوانند به شما در اسکرپ Web Designer News بدون نوشتن کد کمک کنند. این ابزارها معمولاً از رابطهای بصری برای انتخاب داده استفاده میکنند، اگرچه ممکن است با محتوای پویای پیچیده یا اقدامات ضد ربات مشکل داشته باشند.
گردش کار معمول با ابزارهای بدون کد
- افزونه مرورگر را نصب کنید یا در پلتفرم ثبتنام کنید
- به وبسایت هدف بروید و ابزار را باز کنید
- عناصر دادهای مورد نظر را با کلیک انتخاب کنید
- انتخابگرهای CSS را برای هر فیلد داده پیکربندی کنید
- قوانین صفحهبندی را برای استخراج چندین صفحه تنظیم کنید
- CAPTCHA را مدیریت کنید (اغلب نیاز به حل دستی دارد)
- زمانبندی اجرای خودکار را پیکربندی کنید
- دادهها را به CSV، JSON صادر کنید یا از طریق API متصل شوید
چالشهای رایج
- منحنی یادگیری: درک انتخابگرها و منطق استخراج زمان میبرد
- انتخابگرها خراب میشوند: تغییرات وبسایت میتواند کل جریان کار را خراب کند
- مشکلات محتوای پویا: سایتهای پر از JavaScript نیاز به راهحلهای پیچیده دارند
- محدودیتهای CAPTCHA: اکثر ابزارها نیاز به مداخله دستی برای CAPTCHA دارند
- مسدود شدن IP: استخراج تهاجمی میتواند منجر به مسدود شدن IP شما شود
نمونه کدها
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
url = 'https://webdesignernews.com/'
try:
# Send request to the main page
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Locate post containers
posts = soup.find_all('div', class_='single-post')
for post in posts:
title = post.find('h3').get_text(strip=True)
# Check if source site name exists
source = post.find('span', class_='site_name').get_text(strip=True) if post.find('span', class_='site_name') else 'Unknown'
link = post.find('h3').find('a')['href']
print(f'Title: {title} | Source: {source} | Link: {link}')
except Exception as e:
print(f'An error occurred: {e}')زمان استفاده
بهترین گزینه برای صفحات HTML ایستا که محتوا در سمت سرور بارگذاری میشود. سریعترین و سادهترین روش وقتی رندر JavaScript لازم نیست.
مزایا
- ●سریعترین اجرا (بدون سربار مرورگر)
- ●کمترین مصرف منابع
- ●به راحتی با asyncio قابل موازیسازی
- ●عالی برای API و صفحات ایستا
محدودیتها
- ●قادر به اجرای JavaScript نیست
- ●در SPA و محتوای پویا ناموفق است
- ●ممکن است با سیستمهای ضد ربات پیچیده مشکل داشته باشد
How to Scrape Web Designer News with Code
Python + Requests
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
url = 'https://webdesignernews.com/'
try:
# Send request to the main page
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Locate post containers
posts = soup.find_all('div', class_='single-post')
for post in posts:
title = post.find('h3').get_text(strip=True)
# Check if source site name exists
source = post.find('span', class_='site_name').get_text(strip=True) if post.find('span', class_='site_name') else 'Unknown'
link = post.find('h3').find('a')['href']
print(f'Title: {title} | Source: {source} | Link: {link}')
except Exception as e:
print(f'An error occurred: {e}')Python + Playwright
from playwright.sync_api import sync_playwright
def scrape_wdn():
with sync_playwright() as p:
# Launch headless browser
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto('https://webdesignernews.com/')
# Wait for the post elements to load
page.wait_for_selector('.single-post')
posts = page.query_selector_all('.single-post')
for post in posts:
title_el = post.query_selector('h3 a')
if title_el:
title = title_el.inner_text()
link = title_el.get_attribute('href')
print(f'Scraped: {title} - {link}')
browser.close()
scrape_wdn()Python + Scrapy
import scrapy
class WdnSpider(scrapy.Spider):
name = 'wdn_spider'
start_urls = ['https://webdesignernews.com/']
def parse(self, response):
# Extract each post in the feed
for post in response.css('.single-post'):
yield {
'title': post.css('h3 a::text').get(),
'source': post.css('.site_name::text').get(),
'link': post.css('h3 a::attr(href)').get()
}
# Handle pagination by finding the 'Next' link
next_page = response.css('a.next::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://webdesignernews.com/', { waitUntil: 'domcontentloaded' });
// Evaluate the page to extract data fields
const results = await page.evaluate(() => {
const items = Array.from(document.querySelectorAll('.single-post'));
return items.map(item => ({
title: item.querySelector('h3 a') ? item.querySelector('h3 a').innerText : null,
source: item.querySelector('.site_name') ? item.querySelector('.site_name').innerText : null,
link: item.querySelector('h3 a') ? item.querySelector('h3 a').href : null
}));
});
console.log(results);
await browser.close();
})();با دادههای Web Designer News چه کارهایی میتوانید انجام دهید
کاربردهای عملی و بینشها از دادههای Web Designer News را بررسی کنید.
فید خبری خودکار طراحی
یک کانال خبری زنده و کیوریت شده برای تیمهای طراحی حرفهای از طریق Slack یا Discord ایجاد کنید.
نحوه پیادهسازی:
- 1داستانهای دارای بالاترین امتیاز را هر 4 ساعت یکبار scrape کنید.
- 2نتایج را بر اساس تگهای دستهبندی مرتبط مانند 'UX' یا 'Web Dev' فیلتر کنید.
- 3عنوانها و خلاصههای استخراج شده را به یک webhook پیامرسان ارسال کنید.
- 4دادهها را برای ردیابی محبوبیت بلندمدت ابزارهای صنعت آرشیو کنید.
از Automatio برای استخراج داده از Web Designer News و ساخت این برنامهها بدون نوشتن کد استفاده کنید.
با دادههای Web Designer News چه کارهایی میتوانید انجام دهید
- فید خبری خودکار طراحی
یک کانال خبری زنده و کیوریت شده برای تیمهای طراحی حرفهای از طریق Slack یا Discord ایجاد کنید.
- داستانهای دارای بالاترین امتیاز را هر 4 ساعت یکبار scrape کنید.
- نتایج را بر اساس تگهای دستهبندی مرتبط مانند 'UX' یا 'Web Dev' فیلتر کنید.
- عنوانها و خلاصههای استخراج شده را به یک webhook پیامرسان ارسال کنید.
- دادهها را برای ردیابی محبوبیت بلندمدت ابزارهای صنعت آرشیو کنید.
- ردیاب ترند ابزارهای طراحی
شناسایی کنید که کدام نرمافزارها یا کتابخانههای طراحی بیشترین تعامل را در جامعه به دست میآورند.
- عنوانها و گزیدهها را از آرشیو دستهبندی 'Resources' استخراج کنید.
- تحلیل فرکانس کلمات کلیدی را روی اصطلاحات خاص (مانند 'Figma' یا 'React') انجام دهید.
- رشد دفعات تکرار را ماه به ماه مقایسه کنید تا ستارههای نوظهور را شناسایی کنید.
- گزارشهای بصری برای تیمهای بازاریابی یا استراتژی محصول خروجی بگیرید.
- مانیتورینگ بکلینک رقبا
شناسایی کنید که کدام وبلاگها یا آژانسها با موفقیت محتوای خود را در مراکز اصلی قرار میدهند.
- فیلد 'Source Website Name' را برای تمام لیستهای تاریخی scrape کنید.
- تعداد تکرارها را به ازای هر دامنه خارجی تجمیع کنید تا ببینید چه کسی بیشتر نمایش داده شده است.
- انواع محتوایی که پذیرفته میشوند را برای تعامل بهتر تحلیل کنید.
- شرکای همکاری بالقوه را در فضای طراحی شناسایی کنید.
- مجموعه داده آموزشی برای Machine Learning
از قطعات و خلاصههای کیوریت شده برای آموزش مدلهای خلاصه سازی فنی استفاده کنید.
- بیش از 10,000 عنوان داستان و خلاصههای مربوطه را scrape کنید.
- دادههای متنی را برای حذف پارامترهای ردیابی داخلی و HTML پاکسازی کنید.
- از عنوان به عنوان هدف و از خلاصه به عنوان ورودی برای fine-tuning استفاده کنید.
- مدل را روی مقالات طراحی جدید و مشاهده نشده برای سنجش عملکرد تست کنید.
گردش کار خود را با اتوماسیون AI
Automatio قدرت عاملهای AI، اتوماسیون وب و ادغامهای هوشمند را ترکیب میکند تا به شما کمک کند در زمان کمتر بیشتر انجام دهید.
نکات حرفهای برای اسکرپ Web Designer News
توصیههای تخصصی برای استخراج موفق داده از Web Designer News.
از endpoint مربوط به REST API وردپرس (/wp-json/wp/v2/posts) برای دریافت سریعتر و مطمئنتر دادههای ساختاریافته نسبت به پردازش HTML استفاده کنید.
فید RSS سایت را در آدرس webdesignernews.com/feed/ مانیتور کنید تا داستانهای جدید را به محض انتشار دریافت کنید.
وظایف scraping خود را برای ساعت 9
00 AM EST برنامهریزی کنید تا با اوج روزانه محتوای ارسال شده توسط جامعه هماهنگ شود.
رشتههای User-Agent را بچرخانید (rotate) و یک تأخیر 2 ثانیهای بین درخواستها اعمال کنید تا از تحریک محدودیتهای نرخ Nginx جلوگیری شود.
همیشه لینکهای داخلی '/go/' را با دنبال کردن ریدایرکتها حل کنید تا URL منبع نهایی و canonical را استخراج کنید.
دادههای متنی خلاصه (excerpt) را با حذف تگهای HTML و نقاط متوالی (ellipses) برای نتایج تحلیل بهتر، پاکسازی کنید.
نظرات
کاربران ما چه میگویند
به هزاران کاربر راضی که گردش کار خود را متحول کردهاند بپیوندید
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
مرتبط Web Scraping




سوالات متداول درباره Web Designer News
پاسخ سوالات رایج درباره Web Designer News را بیابید