Comment scraper Coinpaprika : Guide d'extraction de données du marché crypto
Apprenez à scraper Coinpaprika pour obtenir les prix crypto en temps réel, les capitalisations boursières et les volumes d'échange. Extrayez des données de...
Protection Anti-Bot Détectée
- Cloudflare
- WAF et gestion de bots de niveau entreprise. Utilise des défis JavaScript, des CAPTCHAs et l'analyse comportementale. Nécessite l'automatisation du navigateur avec des paramètres furtifs.
- Limitation de débit
- Limite les requêtes par IP/session dans le temps. Peut être contourné avec des proxys rotatifs, des délais de requête et du scraping distribué.
- Blocage IP
- Bloque les IP de centres de données connues et les adresses signalées. Nécessite des proxys résidentiels ou mobiles pour contourner efficacement.
- Empreinte navigateur
- Identifie les bots par les caractéristiques du navigateur : canvas, WebGL, polices, plugins. Nécessite du spoofing ou de vrais profils de navigateur.
À Propos de Coinpaprika
Découvrez ce que Coinpaprika offre et quelles données précieuses peuvent être extraites.
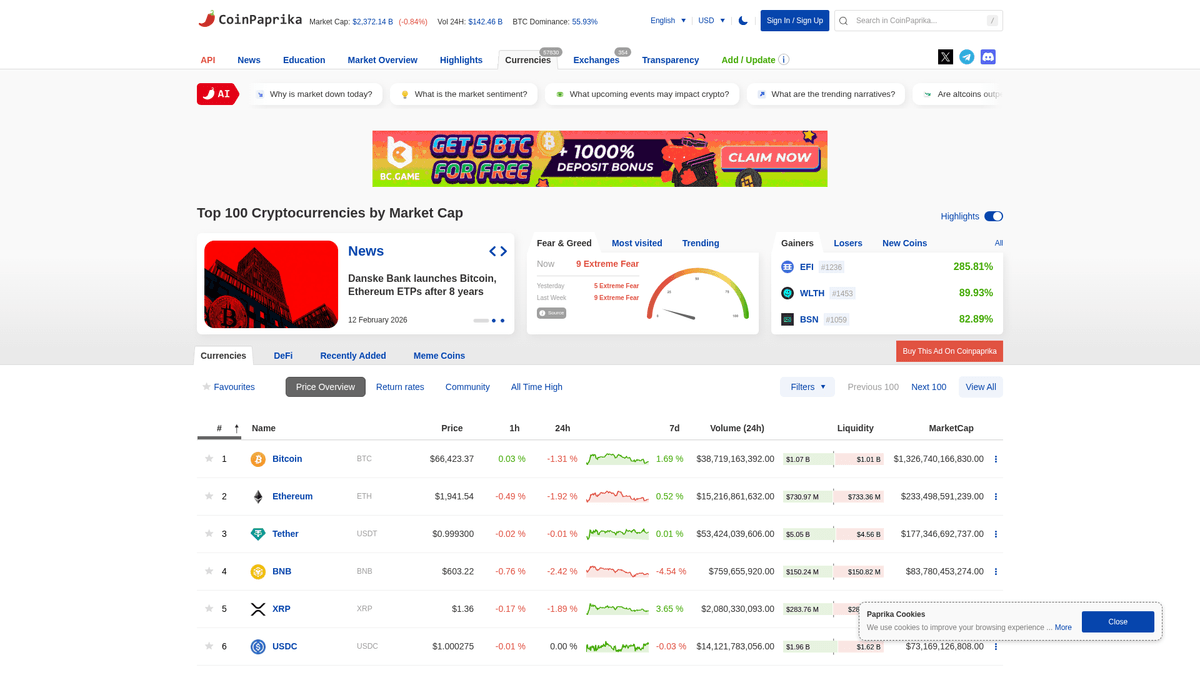
Aperçu de Coinpaprika
Coinpaprika est une plateforme complète de recherche sur les cryptomonnaies lancée en 2018 pour fournir des données de marché fiables. Elle suit des milliers d'actifs numériques sur des centaines d'échanges, offrant des informations sur les mouvements de prix, les volumes d'échange et les indicateurs de liquidité. La plateforme est conçue pour les investisseurs, les développeurs et les chercheurs qui recherchent une vision transparente de l'écosystème crypto mondial.
Données Disponibles
Le site contient une multitude de listes, incluant des pages de coins individuelles, des classements de transparence des échanges et des ressources éducatives. Les points de données vont du prix de base et de la capitalisation boursière à des indicateurs complexes comme les Confidence scores et la profondeur du marché (analyse du carnet d'ordres à 1 % et 10 %). Il sert de benchmark pour l'industrie aux côtés d'autres grands agrégateurs comme CoinMarketCap et CoinGecko.
Valeur du Scraping
Scraper Coinpaprika est extrêmement précieux pour créer des tableaux de bord financiers, effectuer des analyses de marché historiques et mener une veille concurrentielle. Les données permettent aux utilisateurs de surveiller les opportunités d'arbitrage, de suivre la croissance de secteurs de marché spécifiques comme la DeFi ou les NFTs, et d'intégrer des valorisations crypto en temps réel dans des applications privées ou des articles de recherche académique sans les limitations des limites de débit des API standards.
Pourquoi Scraper Coinpaprika?
Découvrez la valeur commerciale et les cas d'utilisation pour l'extraction de données de Coinpaprika.
Détection d'arbitrage en temps réel
Scrapez et comparez les prix en direct sur plus de 350 plateformes d'échange listées sur Coinpaprika pour identifier et exploiter les écarts de prix du marché.
Recherche approfondie sur la Tokenomics
Surveillez l'offre en circulation, l'offre maximale et les variations de l'offre totale sur plus de 57 000 actifs pour effectuer une analyse fondamentale de la viabilité des projets.
Évaluation de la liquidité et des risques
Extrayez la profondeur de marché (1 % et 10 %) et les scores de confiance pour évaluer la liquidité réelle des paires de trading et éviter les risques de wash-trading.
Audit des équipes de projet
Rassemblez les détails sur les équipes de projet, les liens vers les whitepapers et les URL du code source GitHub pour effectuer une due diligence sur les nouvelles initiatives blockchain.
Backtesting historique du marché
Collectez les points de données All-Time High et All-Time Low ainsi que les tableaux de prix historiques pour affiner et tester vos stratégies de trading quantitatif.
Suivi du sentiment et des réseaux sociaux
Suivez les liens vers les réseaux sociaux et les niveaux d'activité de la communauté listés sur les pages individuelles des coins pour évaluer la hype et l'engagement du marché.
Défis du Scraping
Défis techniques que vous pouvez rencontrer lors du scraping de Coinpaprika.
Rendu dynamique basé sur React
De nombreuses mises à jour de prix en temps réel et graphiques interactifs sont rendus via JavaScript, nécessitant un navigateur headless pour capturer le DOM entièrement hydraté.
Boucliers de sécurité Cloudflare
Coinpaprika utilise le WAF de Cloudflare, qui peut déclencher des défis ou des blocages s'il détecte un trafic non issu d'un navigateur ou des schémas de scraping suspects.
Mises à jour fréquentes des sélecteurs
Les classes CSS du frontend de la plateforme sont souvent mises à jour et peuvent changer selon la direction des prix (bullish vs bearish), rendant les sélecteurs statiques fragiles.
Rate limiting agressif
Les requêtes non authentifiées sont soumises à des limites strictes, nécessitant l'utilisation de proxys tournants de haute qualité pour maintenir une extraction de données à haute vitesse.
Scrapez Coinpaprika avec l'IA
Aucun code requis. Extrayez des données en minutes avec l'automatisation par IA.
Comment ça marche
Décrivez ce dont vous avez besoin
Dites à l'IA quelles données vous souhaitez extraire de Coinpaprika. Tapez simplement en langage naturel — pas de code ni de sélecteurs.
L'IA extrait les données
Notre intelligence artificielle navigue sur Coinpaprika, gère le contenu dynamique et extrait exactement ce que vous avez demandé.
Obtenez vos données
Recevez des données propres et structurées, prêtes à exporter en CSV, JSON ou à envoyer directement à vos applications.
Pourquoi utiliser l'IA pour le scraping
L'IA facilite le scraping de Coinpaprika sans écrire de code. Notre plateforme alimentée par l'intelligence artificielle comprend quelles données vous voulez — décrivez-les en langage naturel et l'IA les extrait automatiquement.
How to scrape with AI:
- Décrivez ce dont vous avez besoin: Dites à l'IA quelles données vous souhaitez extraire de Coinpaprika. Tapez simplement en langage naturel — pas de code ni de sélecteurs.
- L'IA extrait les données: Notre intelligence artificielle navigue sur Coinpaprika, gère le contenu dynamique et extrait exactement ce que vous avez demandé.
- Obtenez vos données: Recevez des données propres et structurées, prêtes à exporter en CSV, JSON ou à envoyer directement à vos applications.
Why use AI for scraping:
- Constructeur visuel No-Code: Mappez facilement les champs de données comme la capitalisation boursière et le volume via une interface pointer-cliquer sans écrire de scripts complexes Playwright ou Puppeteer.
- Gestion automatique des Captchas: Contournez automatiquement Cloudflare et d'autres mécanismes de détection de bots, garantissant que vos tâches de scraping s'exécutent sans interruption manuelle.
- Snapshots de marché programmés: Configurez vos scrapers pour qu'ils s'exécutent à des intervalles spécifiques afin de construire une base de données historique personnalisée des prix crypto et de la liquidité des échanges.
- Intégration directe via Webhook: Poussez instantanément les données de marché scrapées vers vos propres applications, bots Telegram ou serveurs Discord pour des alertes et une automatisation en temps réel.
- Gestion intelligente des proxys: Utilisez des proxys résidentiels et tournants intégrés pour imiter le trafic organique et prévenir les bannissements d'IP par le site cible.
Scrapers Web No-Code pour Coinpaprika
Alternatives pointer-cliquer au scraping alimenté par l'IA
Plusieurs outils no-code comme Browse.ai, Octoparse, Axiom et ParseHub peuvent vous aider à scraper Coinpaprika sans écrire de code. Ces outils utilisent généralement des interfaces visuelles pour sélectionner les données, bien qu'ils puissent avoir des difficultés avec le contenu dynamique complexe ou les mesures anti-bot.
Workflow Typique avec les Outils No-Code
Défis Courants
Courbe d'apprentissage
Comprendre les sélecteurs et la logique d'extraction prend du temps
Les sélecteurs cassent
Les modifications du site web peuvent casser tout le workflow
Problèmes de contenu dynamique
Les sites riches en JavaScript nécessitent des solutions complexes
Limitations des CAPTCHAs
La plupart des outils nécessitent une intervention manuelle pour les CAPTCHAs
Blocage d'IP
Le scraping agressif peut entraîner le blocage de votre IP
Scrapers Web No-Code pour Coinpaprika
Plusieurs outils no-code comme Browse.ai, Octoparse, Axiom et ParseHub peuvent vous aider à scraper Coinpaprika sans écrire de code. Ces outils utilisent généralement des interfaces visuelles pour sélectionner les données, bien qu'ils puissent avoir des difficultés avec le contenu dynamique complexe ou les mesures anti-bot.
Workflow Typique avec les Outils No-Code
- Installer l'extension de navigateur ou s'inscrire sur la plateforme
- Naviguer vers le site web cible et ouvrir l'outil
- Sélectionner en point-and-click les éléments de données à extraire
- Configurer les sélecteurs CSS pour chaque champ de données
- Configurer les règles de pagination pour scraper plusieurs pages
- Gérer les CAPTCHAs (nécessite souvent une résolution manuelle)
- Configurer la planification pour les exécutions automatiques
- Exporter les données en CSV, JSON ou se connecter via API
Défis Courants
- Courbe d'apprentissage: Comprendre les sélecteurs et la logique d'extraction prend du temps
- Les sélecteurs cassent: Les modifications du site web peuvent casser tout le workflow
- Problèmes de contenu dynamique: Les sites riches en JavaScript nécessitent des solutions complexes
- Limitations des CAPTCHAs: La plupart des outils nécessitent une intervention manuelle pour les CAPTCHAs
- Blocage d'IP: Le scraping agressif peut entraîner le blocage de votre IP
Exemples de Code
import requests
from bs4 import BeautifulSoup
# URL de la page du coin spécifique
url = 'https://coinpaprika.com/coin/btc-bitcoin/'
# Définir les headers pour imiter une requête de navigateur réel
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
try:
# Envoyer la requête au site web
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Extraire le nom de l'actif et le prix
coin_name = soup.find('h1').text.strip() if soup.find('h1') else 'N/A'
price = soup.find('span', {'class': 'cp-price-value'}).text.strip() if soup.find('span', {'class': 'cp-price-value'}) else 'N/A'
print(f'Actif: {coin_name}')
print(f'Prix actuel: {price}')
except Exception as e:
print(f'Une erreur est survenue : {e}')Quand Utiliser
Idéal pour les pages HTML statiques avec peu de JavaScript. Parfait pour les blogs, sites d'actualités et pages e-commerce simples.
Avantages
- ●Exécution la plus rapide (sans surcharge navigateur)
- ●Consommation de ressources minimale
- ●Facile à paralléliser avec asyncio
- ●Excellent pour les APIs et pages statiques
Limitations
- ●Ne peut pas exécuter JavaScript
- ●Échoue sur les SPAs et contenu dynamique
- ●Peut avoir des difficultés avec les systèmes anti-bot complexes
Comment Scraper Coinpaprika avec du Code
Python + Requests
import requests
from bs4 import BeautifulSoup
# URL de la page du coin spécifique
url = 'https://coinpaprika.com/coin/btc-bitcoin/'
# Définir les headers pour imiter une requête de navigateur réel
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
try:
# Envoyer la requête au site web
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Extraire le nom de l'actif et le prix
coin_name = soup.find('h1').text.strip() if soup.find('h1') else 'N/A'
price = soup.find('span', {'class': 'cp-price-value'}).text.strip() if soup.find('span', {'class': 'cp-price-value'}) else 'N/A'
print(f'Actif: {coin_name}')
print(f'Prix actuel: {price}')
except Exception as e:
print(f'Une erreur est survenue : {e}')Python + Playwright
from playwright.sync_api import sync_playwright
def scrape_coinpaprika():
with sync_playwright() as p:
# Lancer un navigateur headless
browser = p.chromium.launch(headless=True)
page = browser.new_page()
# Naviguer vers la page du coin
page.goto('https://coinpaprika.com/coin/btc-bitcoin/')
# Attendre que l'élément du prix soit rendu par JS
page.wait_for_selector('.cp-price-value')
data = {
'title': page.title(),
'price': page.inner_text('.cp-price-value'),
'market_cap': page.inner_text('text=Market Cap >> xpath=..')
}
print(data)
browser.close()
if __name__ == '__main__':
scrape_coinpaprika()Python + Scrapy
import scrapy
class CoinpaprikaSpider(scrapy.Spider):
name = 'coinpaprika'
start_urls = ['https://coinpaprika.com/all-coins/']
def parse(self, response):
# Itérer à travers les lignes du tableau des coins
for row in response.css('table.cp-table tbody tr'):
yield {
'rank': row.css('td.rank::text').get(),
'name': row.css('td.name a::text').get().strip(),
'price': row.css('td.price span::text').get(),
'market_cap': row.css('td.market-cap::text').get()
}
# Gérer la pagination numérotée simple
next_page = response.css('a.next-page::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
try {
// Naviguer et attendre que l'activité réseau se stabilise
await page.goto('https://coinpaprika.com/coin/btc-bitcoin/', { waitUntil: 'networkidle2' });
const coinData = await page.evaluate(() => {
return {
name: document.querySelector('h1')?.innerText.trim(),
price: document.querySelector('.cp-price-value')?.innerText.trim(),
volume24h: document.querySelector('text/Volume (24h)')?.parentElement?.innerText
};
});
console.log(coinData);
} catch (error) {
console.error('Erreur lors du scraping:', error);
} finally {
await browser.close();
}
})();Que Pouvez-Vous Faire Avec Les Données de Coinpaprika
Explorez les applications pratiques et les insights des données de Coinpaprika.
Surveillance de l'arbitrage crypto
Identifiez les écarts de prix pour un même actif sur différents échanges afin de trouver des opportunités de profit.
Comment implémenter :
- 1Scraper toutes les paires de trading pour un coin spécifique à partir de sa page de marché.
- 2Comparer le champ Price sur tous les échanges listés en temps réel.
- 3Filtrer les résultats par Confidence score pour s'assurer que la liquidité est vérifiée.
- 4Calculer la marge de profit potentielle après avoir pris en compte les frais de transaction.
Utilisez Automatio pour extraire des données de Coinpaprika et créer ces applications sans écrire de code.
Que Pouvez-Vous Faire Avec Les Données de Coinpaprika
- Surveillance de l'arbitrage crypto
Identifiez les écarts de prix pour un même actif sur différents échanges afin de trouver des opportunités de profit.
- Scraper toutes les paires de trading pour un coin spécifique à partir de sa page de marché.
- Comparer le champ Price sur tous les échanges listés en temps réel.
- Filtrer les résultats par Confidence score pour s'assurer que la liquidité est vérifiée.
- Calculer la marge de profit potentielle après avoir pris en compte les frais de transaction.
- Valorisation automatisée de portefeuille
Créez un tableau de bord privé qui met à jour automatiquement la valeur totale des avoirs crypto d'un utilisateur.
- Configurer un scraper programmé pour les coins spécifiques du portefeuille.
- Extraire les données de prix en temps réel toutes les 5 à 15 minutes.
- Multiplier le prix extrait par le solde statique de l'utilisateur dans une feuille de calcul.
- Visualiser la performance des actifs individuels et le gain/perte total au fil du temps.
- Analyse du sentiment du marché
Analysez si la couverture médiatique et les mises à jour de projets corrèlent avec les mouvements de prix pour la prédiction des tendances du marché.
- Scraper la section News de Coinpaprika pour des catégories de coins spécifiques.
- Extraire les titres, les descriptions et les horodatages de publication.
- Effectuer une analyse de sentiment NLP sur le texte pour déterminer le ton (bullish ou bearish).
- Comparer les scores de sentiment avec l'évolution des prix extraite des graphiques.
- Recherche par backtesting historique
Rassemblez des données historiques approfondies pour tester et affiner vos stratégies de trading avant de risquer du capital.
- Scraper les graphiques de prix historiques pour les valeurs d'ouverture, de haut, de bas et de clôture quotidiennes.
- Collecter les données de volume sur 24h pour identifier les zones de trading à fort intérêt.
- Formater les données dans une structure OHLC standard pour les indicateurs techniques.
- Passer les données dans un logiciel de backtesting pour mesurer la performance de la stratégie.
- Audit de la légitimité des projets
Vérifiez la confiance et la transparence des projets crypto pour l'évaluation des risques d'investissement.
- Scraper les indicateurs de transparence pour un échange ou un listing de coin spécifique.
- Extraire les données de la section Team pour vérifier l'historique des développeurs sur GitHub.
- Surveiller les changements soudains de l'offre ou les anomalies de volume de trading.
- Signaler pour examen les projets avec de faibles scores de confiance ou des whitepapers manquants.
Optimisez votre flux de travail avec l'Automatisation IA
Automatio combine la puissance des agents IA, de l'automatisation web et des integrations intelligentes pour vous aider a accomplir plus en moins de temps.
Conseils Pro pour Scraper Coinpaprika
Conseils d'experts pour extraire avec succès les données de Coinpaprika.
Surveiller le trafic XHR interne
Consultez l'onglet réseau de votre navigateur pour identifier les points de terminaison JSON internes que le site utilise pour alimenter ses tableaux de données afin d'obtenir une extraction plus propre.
Utiliser des attributs de données stables
Lors de la sélection des éléments, privilégiez les attributs de données ou les identifiants ID uniques plutôt que les classes CSS génériques qui peuvent changer lors des mises à jour de l'interface.
Effectuer une rotation régulière des User Agents
Alternez entre différents en-têtes de navigateurs modernes pour simuler un ensemble diversifié d'utilisateurs organiques et réduire les risques de fingerprinting.
Gérer proprement les valeurs nulles
Les nouvelles cryptomonnaies listées manquent souvent de données sur la capitalisation boursière ou l'offre ; assurez-vous que votre logique de scraping inclut des vérifications pour les chaînes vides ou les mentions 'Aucune donnée'.
Implémenter un Exponential Backoff
Si vous rencontrez des codes d'état 429, augmentez le temps d'attente entre les requêtes pour respecter la charge du serveur et éviter les bannissements d'IP permanents.
Témoignages
Ce Que Disent Nos Utilisateurs
Rejoignez des milliers d'utilisateurs satisfaits qui ont transforme leur flux de travail
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Associés Web Scraping
How to Scrape Moon.ly | Step-by-Step NFT Data Extraction Guide
How to Scrape Yahoo Finance: Extract Stock Market Data
How to Scrape Rocket Mortgage: A Comprehensive Guide
How to Scrape Open Collective: Financial and Contributor Data Guide
How to Scrape jup.ag: Jupiter DEX Web Scraper Guide
How to Scrape Indiegogo: The Ultimate Crowdfunding Data Extraction Guide
How to Scrape ICO Drops: Comprehensive Crypto Data Guide
How to Scrape Crypto.com: Comprehensive Market Data Guide
Questions Fréquentes sur Coinpaprika
Trouvez des réponses aux questions courantes sur Coinpaprika