Comment scraper Hacker News (news.ycombinator.com)
Apprenez à scraper Hacker News pour extraire les meilleurs articles tech, les offres d'emploi et les discussions de la communauté. Idéal pour l'étude de marché...
Protection Anti-Bot Détectée
- Limitation de débit
- Limite les requêtes par IP/session dans le temps. Peut être contourné avec des proxys rotatifs, des délais de requête et du scraping distribué.
- Blocage IP
- Bloque les IP de centres de données connues et les adresses signalées. Nécessite des proxys résidentiels ou mobiles pour contourner efficacement.
- User-Agent Filtering
À Propos de Hacker News
Découvrez ce que Hacker News offre et quelles données précieuses peuvent être extraites.
Le Hub Tech
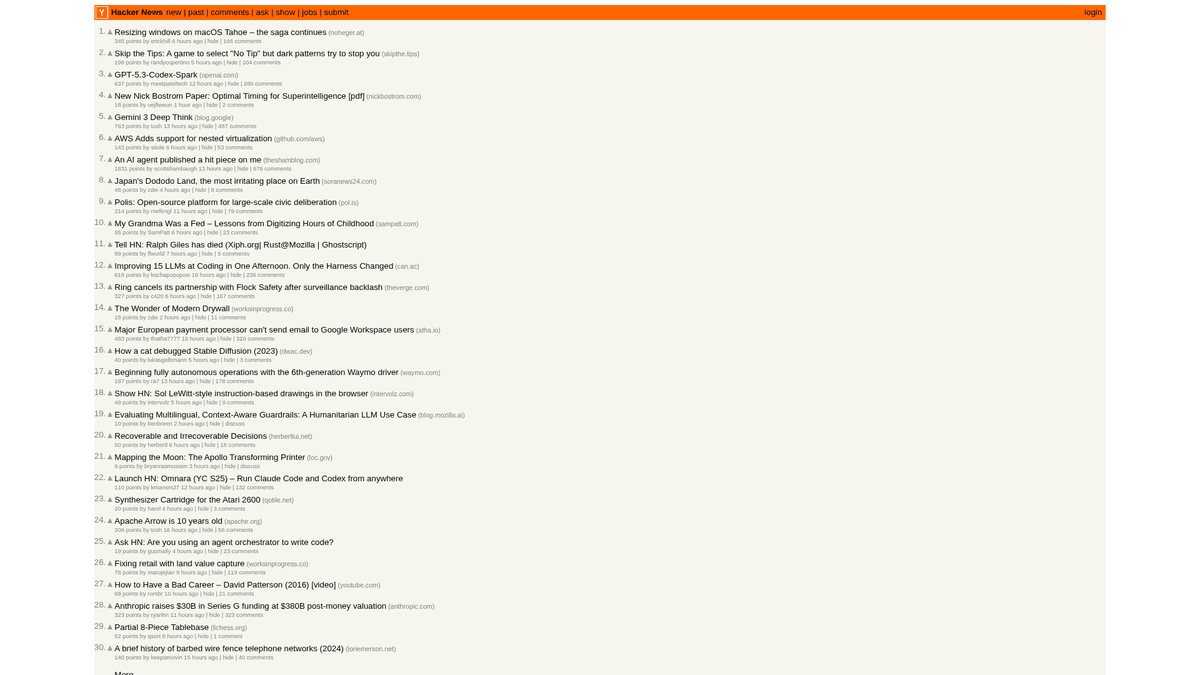
Hacker News est un site de social news axé sur l'informatique et l'entrepreneuriat, géré par l'incubateur de startups Y Combinator. Il fonctionne comme une plateforme communautaire où les utilisateurs soumettent des liens vers des articles techniques, des actualités sur les startups et des discussions approfondies.
Richesse des Données
La plateforme regorge de données en temps réel, notamment des histoires tech plébiscitées, des lancements de startups "Show HN", des questions communautaires "Ask HN" et des tableaux d'offres d'emploi spécialisés. Elle est largement considérée comme le pouls de l'écosystème de la Silicon Valley et de la communauté mondiale des développeurs.
Valeur Stratégique
Le scraping de ces données permet aux entreprises et aux chercheurs de surveiller les technologies émergentes, de suivre les mentions des concurrents et d'identifier les leaders d'opinion influents. Comme la mise en page du site est remarquablement stable et légère, c'est l'une des sources les plus fiables pour l'agrégation automatisée d'actualités techniques.
Pourquoi Scraper Hacker News?
Découvrez la valeur commerciale et les cas d'utilisation pour l'extraction de données de Hacker News.
Identification des tendances du marché
Surveillez la page d'accueil pour voir quels langages de programmation, frameworks ou outils gagnent du terrain dans la communauté des développeurs en temps réel.
Analyse de sentiment
Scrapez les fils de commentaires pour analyser comment une audience hautement technique réagit aux lancements de nouveaux produits, aux changements de politique ou aux évolutions du marché.
Veille sur les startups
Suivez les publications 'Show HN' pour découvrir les startups en phase de démarrage et les projets innovants avant qu'ils ne fassent l'objet d'une couverture médiatique grand public.
Génération de leads pour le recrutement
Extrayez les données des entreprises qui recrutent dans la section Jobs pour trouver des sociétés tech en pleine croissance recherchant des expertises spécifiques.
Agrégation de contenu
Créez des flux d'actualités techniques ou des newsletters de haute qualité en filtrant les publications avec le plus grand nombre d'upvotes ou des mots-clés spécifiques aux développeurs.
Défis du Scraping
Défis techniques que vous pouvez rencontrer lors du scraping de Hacker News.
Limitation du débit par IP
Hacker News limite agressivement les requêtes à haute fréquence provenant d'une seule adresse IP, ce qui nécessite une vitesse de crawl lente ou une rotation de proxy.
Parsing des tableaux imbriqués
Le site utilise des structures de tableaux HTML héritées pour imbriquer les commentaires, ce qui nécessite une logique de parcours minutieuse pour reconstruire correctement les relations parent-enfant.
Horodatages relatifs
Les heures sont affichées sous la forme 'il y a X heures', ce qui nécessite une logique de conversion si vous avez besoin d'horodatages absolus pour une base de données historique chronologique.
Classements dynamiques
La page d'accueil change rapidement à mesure que les articles montent et descendent, ce qui peut entraîner des doublons de données ou des éléments manqués si le scraping n'est pas géré via des ID uniques.
Scrapez Hacker News avec l'IA
Aucun code requis. Extrayez des données en minutes avec l'automatisation par IA.
Comment ça marche
Décrivez ce dont vous avez besoin
Dites à l'IA quelles données vous souhaitez extraire de Hacker News. Tapez simplement en langage naturel — pas de code ni de sélecteurs.
L'IA extrait les données
Notre intelligence artificielle navigue sur Hacker News, gère le contenu dynamique et extrait exactement ce que vous avez demandé.
Obtenez vos données
Recevez des données propres et structurées, prêtes à exporter en CSV, JSON ou à envoyer directement à vos applications.
Pourquoi utiliser l'IA pour le scraping
L'IA facilite le scraping de Hacker News sans écrire de code. Notre plateforme alimentée par l'intelligence artificielle comprend quelles données vous voulez — décrivez-les en langage naturel et l'IA les extrait automatiquement.
How to scrape with AI:
- Décrivez ce dont vous avez besoin: Dites à l'IA quelles données vous souhaitez extraire de Hacker News. Tapez simplement en langage naturel — pas de code ni de sélecteurs.
- L'IA extrait les données: Notre intelligence artificielle navigue sur Hacker News, gère le contenu dynamique et extrait exactement ce que vous avez demandé.
- Obtenez vos données: Recevez des données propres et structurées, prêtes à exporter en CSV, JSON ou à envoyer directement à vos applications.
Why use AI for scraping:
- Extraction d'articles en No-Code: Extrayez les titres, les points et les URL en quelques minutes en cliquant simplement sur les éléments au lieu d'écrire des sélecteurs CSS ou XPath personnalisés pour les tableaux imbriqués.
- Gestion intelligente de la pagination: Automatio gère sans effort le lien 'More' pour parcourir automatiquement plusieurs pages d'historique ou des fils de commentaires profonds.
- Rotation de proxy intégrée: Contournez automatiquement les limites de débit grâce à la rotation de proxy intégrée, garantissant que vos tâches de scraping ne sont jamais interrompues par des blocages d'IP.
- Monitoring planifié: Configurez un planning pour scraper automatiquement la page d'accueil toutes les heures afin de maintenir votre base de données à jour avec les dernières tendances tech.
- Intégration directe: Envoyez les données scrapées de Hacker News directement vers Google Sheets ou des webhooks pour déclencher des alertes lorsque des mots-clés spécifiques apparaissent dans les discussions.
Scrapers Web No-Code pour Hacker News
Alternatives pointer-cliquer au scraping alimenté par l'IA
Plusieurs outils no-code comme Browse.ai, Octoparse, Axiom et ParseHub peuvent vous aider à scraper Hacker News sans écrire de code. Ces outils utilisent généralement des interfaces visuelles pour sélectionner les données, bien qu'ils puissent avoir des difficultés avec le contenu dynamique complexe ou les mesures anti-bot.
Workflow Typique avec les Outils No-Code
Défis Courants
Courbe d'apprentissage
Comprendre les sélecteurs et la logique d'extraction prend du temps
Les sélecteurs cassent
Les modifications du site web peuvent casser tout le workflow
Problèmes de contenu dynamique
Les sites riches en JavaScript nécessitent des solutions complexes
Limitations des CAPTCHAs
La plupart des outils nécessitent une intervention manuelle pour les CAPTCHAs
Blocage d'IP
Le scraping agressif peut entraîner le blocage de votre IP
Scrapers Web No-Code pour Hacker News
Plusieurs outils no-code comme Browse.ai, Octoparse, Axiom et ParseHub peuvent vous aider à scraper Hacker News sans écrire de code. Ces outils utilisent généralement des interfaces visuelles pour sélectionner les données, bien qu'ils puissent avoir des difficultés avec le contenu dynamique complexe ou les mesures anti-bot.
Workflow Typique avec les Outils No-Code
- Installer l'extension de navigateur ou s'inscrire sur la plateforme
- Naviguer vers le site web cible et ouvrir l'outil
- Sélectionner en point-and-click les éléments de données à extraire
- Configurer les sélecteurs CSS pour chaque champ de données
- Configurer les règles de pagination pour scraper plusieurs pages
- Gérer les CAPTCHAs (nécessite souvent une résolution manuelle)
- Configurer la planification pour les exécutions automatiques
- Exporter les données en CSV, JSON ou se connecter via API
Défis Courants
- Courbe d'apprentissage: Comprendre les sélecteurs et la logique d'extraction prend du temps
- Les sélecteurs cassent: Les modifications du site web peuvent casser tout le workflow
- Problèmes de contenu dynamique: Les sites riches en JavaScript nécessitent des solutions complexes
- Limitations des CAPTCHAs: La plupart des outils nécessitent une intervention manuelle pour les CAPTCHAs
- Blocage d'IP: Le scraping agressif peut entraîner le blocage de votre IP
Exemples de Code
import requests
from bs4 import BeautifulSoup
url = 'https://news.ycombinator.com/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Les histoires sont contenues dans des lignes avec la classe 'athing'
posts = soup.select('.athing')
for post in posts:
title_element = post.select_one('.titleline > a')
title = title_element.text
link = title_element['href']
print(f'Titre: {title}
Lien: {link}
---')
except Exception as e:
print(f'Le scraping a échoué: {e}')Quand Utiliser
Idéal pour les pages HTML statiques avec peu de JavaScript. Parfait pour les blogs, sites d'actualités et pages e-commerce simples.
Avantages
- ●Exécution la plus rapide (sans surcharge navigateur)
- ●Consommation de ressources minimale
- ●Facile à paralléliser avec asyncio
- ●Excellent pour les APIs et pages statiques
Limitations
- ●Ne peut pas exécuter JavaScript
- ●Échoue sur les SPAs et contenu dynamique
- ●Peut avoir des difficultés avec les systèmes anti-bot complexes
Comment Scraper Hacker News avec du Code
Python + Requests
import requests
from bs4 import BeautifulSoup
url = 'https://news.ycombinator.com/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Les histoires sont contenues dans des lignes avec la classe 'athing'
posts = soup.select('.athing')
for post in posts:
title_element = post.select_one('.titleline > a')
title = title_element.text
link = title_element['href']
print(f'Titre: {title}
Lien: {link}
---')
except Exception as e:
print(f'Le scraping a échoué: {e}')Python + Playwright
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto('https://news.ycombinator.com/')
# Attendre que le tableau se charge
page.wait_for_selector('.athing')
# Extraire tous les titres et liens d'histoires
items = page.query_selector_all('.athing')
for item in items:
title_link = item.query_selector('.titleline > a')
if title_link:
print(title_link.inner_text(), title_link.get_attribute('href'))
browser.close()Python + Scrapy
import scrapy
class HackerNewsSpider(scrapy.Spider):
name = 'hn_spider'
start_urls = ['https://news.ycombinator.com/']
def parse(self, response):
for post in response.css('.athing'):
yield {
'id': post.attrib.get('id'),
'title': post.css('.titleline > a::text').get(),
'link': post.css('.titleline > a::attr(href)').get(),
}
# Suivre le lien de pagination 'More'
next_page = response.css('a.morelink::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://news.ycombinator.com/');
const results = await page.evaluate(() => {
const items = Array.from(document.querySelectorAll('.athing'));
return items.map(item => ({
title: item.querySelector('.titleline > a').innerText,
url: item.querySelector('.titleline > a').href
}));
});
console.log(results);
await browser.close();
})();Que Pouvez-Vous Faire Avec Les Données de Hacker News
Explorez les applications pratiques et les insights des données de Hacker News.
Découverte de tendances de startups
Identifiez les industries ou les types de produits qui sont lancés et discutés le plus fréquemment.
Comment implémenter :
- 1Scraper la catégorie 'Show HN' sur une base hebdomadaire.
- 2Nettoyer et catégoriser les descriptions de startups à l'aide du NLP.
- 3Classer les tendances en fonction des upvotes de la communauté et du sentiment des commentaires.
Utilisez Automatio pour extraire des données de Hacker News et créer ces applications sans écrire de code.
Que Pouvez-Vous Faire Avec Les Données de Hacker News
- Découverte de tendances de startups
Identifiez les industries ou les types de produits qui sont lancés et discutés le plus fréquemment.
- Scraper la catégorie 'Show HN' sur une base hebdomadaire.
- Nettoyer et catégoriser les descriptions de startups à l'aide du NLP.
- Classer les tendances en fonction des upvotes de la communauté et du sentiment des commentaires.
- Sourcing technique et recrutement
Extrayez des listes d'emplois et des détails sur les entreprises à partir des threads de recrutement mensuels spécialisés.
- Surveiller l'ID du thread mensuel 'Who is hiring'.
- Scraper tous les commentaires de premier niveau contenant des descriptions de postes.
- Analyser le texte pour des tech stacks spécifiques comme Rust, AI ou React.
- Intelligence compétitive
Suivez les mentions des concurrents dans les commentaires pour comprendre la perception du public et les plaintes.
- Configurer un scraper basé sur des mots-clés pour des noms de marques spécifiques.
- Extraire les commentaires des utilisateurs et les timestamps pour l'analyse de sentiment.
- Générer des rapports hebdomadaires sur la santé de la marque par rapport aux concurrents.
- Curation automatique de contenu
Créez une newsletter tech à haut signal qui ne contient que les histoires les plus pertinentes.
- Scraper la page d'accueil toutes les 6 heures.
- Filtrer les posts qui dépassent un seuil de 200 points.
- Automatiser l'envoi de ces liens vers un bot Telegram ou une liste de diffusion.
- Génération de leads pour Capital-Risque
Découvrez des startups en phase de démarrage qui gagnent une traction communautaire significative.
- Suivre les posts 'Show HN' qui atteignent la page d'accueil.
- Surveiller le taux de croissance des upvotes au cours des 4 premières heures.
- Alerter les analystes lorsqu'un post montre des schémas de croissance virale.
Optimisez votre flux de travail avec l'Automatisation IA
Automatio combine la puissance des agents IA, de l'automatisation web et des integrations intelligentes pour vous aider a accomplir plus en moins de temps.
Conseils Pro pour Scraper Hacker News
Conseils d'experts pour extraire avec succès les données de Hacker News.
Utilisez l'API officielle
Pour les volumes de données importants, utilisez l'API officielle Firebase qui est plus efficace et fiable que le parsing de la structure HTML héritée.
Respectez le fichier Robots.txt
Vérifiez toujours le fichier robots.txt du site et incluez un délai de crawl d'au moins 30 secondes pour éviter d'être bloqué de manière permanente par le serveur.
Ciblez les ID d'éléments uniques
Chaque article et commentaire possède un ID numérique unique dans le HTML ; utilisez-le comme clé primaire dans votre base de données pour éviter les entrées en double.
Effectuez une rotation des User-Agents
Changez fréquemment les en-têtes de votre navigateur pour empêcher le serveur d'identifier votre trafic comme une activité de bot automatisée.
Utilisez l'API de recherche Algolia
Pour les données historiques ou les recherches par mots-clés complexes, l'API Algolia HN, maintenue par la communauté, est nettement plus rapide et flexible.
Parsing récursif des commentaires
Lors du scraping des commentaires, recherchez la largeur d'indentation ('indent') dans le HTML pour déterminer par programmation le niveau d'imbrication de la discussion.
Témoignages
Ce Que Disent Nos Utilisateurs
Rejoignez des milliers d'utilisateurs satisfaits qui ont transforme leur flux de travail
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Associés Web Scraping




Questions Fréquentes sur Hacker News
Trouvez des réponses aux questions courantes sur Hacker News