Comment scraper Web Designer News
Apprenez à scraper Web Designer News pour extraire les tendances design, les URLs sources et les horodatages. Idéal pour le suivi des tendances design et la...
À Propos de Web Designer News
Découvrez ce que Web Designer News offre et quelles données précieuses peuvent être extraites.
Présentation de Web Designer News
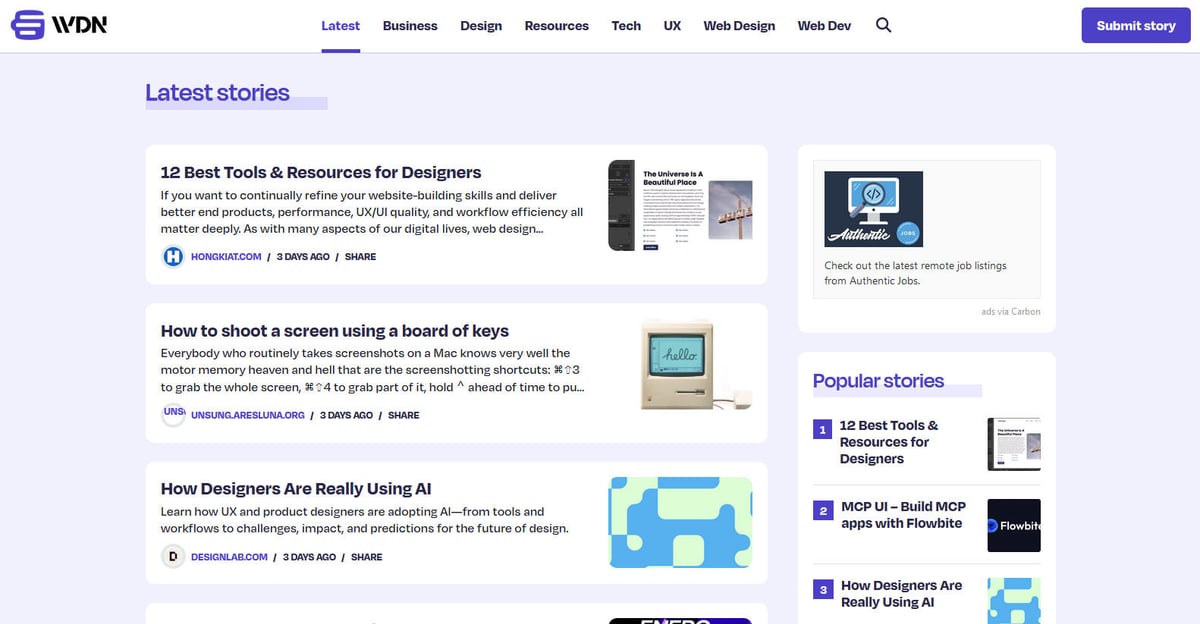
Web Designer News est un agrégateur de news communautaire de premier plan, spécifiquement conçu pour l'écosystème du web design et du développement. Depuis sa création, la plateforme fonctionne comme un hub central où les professionnels découvrent une sélection rigoureuse d'actualités, de tutoriels, d'outils et de ressources les plus pertinents du web. Elle couvre un large éventail de sujets, notamment le design UX, la stratégie commerciale, les mises à jour technologiques et le design graphique, présentés dans un flux chronologique épuré.
Architecture du site et potentiel de données
L'architecture du site repose sur WordPress, avec une mise en page hautement structurée qui organise le contenu en catégories spécifiques telles que 'Web Design', 'Web Dev', 'UX' et 'Resources'. Parce qu'il agrège des données provenant de milliers de blogs et de revues individuels dans une interface unique et consultable, il sert de filtre de haute qualité pour la veille sectorielle. Cette structure en fait une cible idéale pour le web scraping, car elle offre un accès à un flux de données industrielles à haute valeur ajoutée, préalablement validées, sans avoir à parcourir des centaines de domaines distincts.
Pourquoi Scraper Web Designer News?
Découvrez la valeur commerciale et les cas d'utilisation pour l'extraction de données de Web Designer News.
Découverte de tendances en temps réel
Repérez les nouveaux frameworks de design, les bibliothèques UI et les outils de prototypage dès qu'ils gagnent en popularité au sein de la communauté professionnelle.
Curation de contenu automatisée
Maintenez votre propre blog de design, votre newsletter ou vos réseaux sociaux à jour en agrégeant les articles de la plus haute qualité validés par les éditeurs du secteur.
Intelligence de marché
Identifiez quelles agences de design et sociétés de logiciels produisent systématiquement du contenu viral ou sélectionné par la rédaction pour comprendre les leaders du marché.
SEO et recherche de mots-clés
Analysez les titres et les extraits des histoires tendances pour identifier les mots-clés et les sujets les plus pertinents qui captent l'attention de l'industrie.
Archivage historique de l'industrie
Constituez une base de données à long terme sur l'évolution du web design pour suivre comment certains styles, standards de code et technologies évoluent au fil des ans.
Génération de leads B2B
Découvrez de nouvelles startups et agences mises en avant sur la plateforme pour identifier des partenaires ou clients potentiels dans l'espace des technologies créatives.
Défis du Scraping
Défis techniques que vous pouvez rencontrer lors du scraping de Web Designer News.
Redirections de suivi internes
Le site utilise des liens internes '/go/' pour le trafic sortant, ce qui signifie qu'un scraper doit suivre les redirections pour extraire l'URL source réelle.
Parsing des dates relatives
Les horodatages sont souvent affichés dans des formats relatifs comme 'il y a 5 heures', nécessitant une logique personnalisée pour les convertir en formats de date ISO standardisés.
Problèmes de cohérence des données
Certains articles comportent des extraits descriptifs complets et des catégories, tandis que d'autres ne fournissent qu'un titre, ce qui rend difficile le maintien d'une structure de base de données uniforme.
Limitation de débit côté serveur
L'infrastructure basée sur Nginx peut détecter et brider les requêtes à haute fréquence, nécessitant l'utilisation de délais et de headers rotatifs pour éviter les blocages d'IP.
Scrapez Web Designer News avec l'IA
Aucun code requis. Extrayez des données en minutes avec l'automatisation par IA.
Comment ça marche
Décrivez ce dont vous avez besoin
Dites à l'IA quelles données vous souhaitez extraire de Web Designer News. Tapez simplement en langage naturel — pas de code ni de sélecteurs.
L'IA extrait les données
Notre intelligence artificielle navigue sur Web Designer News, gère le contenu dynamique et extrait exactement ce que vous avez demandé.
Obtenez vos données
Recevez des données propres et structurées, prêtes à exporter en CSV, JSON ou à envoyer directement à vos applications.
Pourquoi utiliser l'IA pour le scraping
L'IA facilite le scraping de Web Designer News sans écrire de code. Notre plateforme alimentée par l'intelligence artificielle comprend quelles données vous voulez — décrivez-les en langage naturel et l'IA les extrait automatiquement.
How to scrape with AI:
- Décrivez ce dont vous avez besoin: Dites à l'IA quelles données vous souhaitez extraire de Web Designer News. Tapez simplement en langage naturel — pas de code ni de sélecteurs.
- L'IA extrait les données: Notre intelligence artificielle navigue sur Web Designer News, gère le contenu dynamique et extrait exactement ce que vous avez demandé.
- Obtenez vos données: Recevez des données propres et structurées, prêtes à exporter en CSV, JSON ou à envoyer directement à vos applications.
Why use AI for scraping:
- Gestion visuelle des redirections: Automatio peut être configuré pour suivre automatiquement les liens internes 'go' et capturer l'URL de destination finale sans écrire de logique de redirection complexe.
- Pagination No-Code: Naviguez sans effort à travers les vastes pages d'archives du site en sélectionnant simplement le bouton 'Suivant' dans l'interface point-and-click.
- Planification basée sur le cloud: Exécutez vos scrapers sur un calendrier quotidien récurrent dans le cloud afin que votre base de données d'actualités design reste à jour sans intervention manuelle.
- Synchronisation de données structurées: Exportez directement vos données d'actualités scrapées vers Google Sheets, Webflow ou via API pour alimenter instantanément vos propres applications de design.
Scrapers Web No-Code pour Web Designer News
Alternatives pointer-cliquer au scraping alimenté par l'IA
Plusieurs outils no-code comme Browse.ai, Octoparse, Axiom et ParseHub peuvent vous aider à scraper Web Designer News sans écrire de code. Ces outils utilisent généralement des interfaces visuelles pour sélectionner les données, bien qu'ils puissent avoir des difficultés avec le contenu dynamique complexe ou les mesures anti-bot.
Workflow Typique avec les Outils No-Code
Défis Courants
Courbe d'apprentissage
Comprendre les sélecteurs et la logique d'extraction prend du temps
Les sélecteurs cassent
Les modifications du site web peuvent casser tout le workflow
Problèmes de contenu dynamique
Les sites riches en JavaScript nécessitent des solutions complexes
Limitations des CAPTCHAs
La plupart des outils nécessitent une intervention manuelle pour les CAPTCHAs
Blocage d'IP
Le scraping agressif peut entraîner le blocage de votre IP
Scrapers Web No-Code pour Web Designer News
Plusieurs outils no-code comme Browse.ai, Octoparse, Axiom et ParseHub peuvent vous aider à scraper Web Designer News sans écrire de code. Ces outils utilisent généralement des interfaces visuelles pour sélectionner les données, bien qu'ils puissent avoir des difficultés avec le contenu dynamique complexe ou les mesures anti-bot.
Workflow Typique avec les Outils No-Code
- Installer l'extension de navigateur ou s'inscrire sur la plateforme
- Naviguer vers le site web cible et ouvrir l'outil
- Sélectionner en point-and-click les éléments de données à extraire
- Configurer les sélecteurs CSS pour chaque champ de données
- Configurer les règles de pagination pour scraper plusieurs pages
- Gérer les CAPTCHAs (nécessite souvent une résolution manuelle)
- Configurer la planification pour les exécutions automatiques
- Exporter les données en CSV, JSON ou se connecter via API
Défis Courants
- Courbe d'apprentissage: Comprendre les sélecteurs et la logique d'extraction prend du temps
- Les sélecteurs cassent: Les modifications du site web peuvent casser tout le workflow
- Problèmes de contenu dynamique: Les sites riches en JavaScript nécessitent des solutions complexes
- Limitations des CAPTCHAs: La plupart des outils nécessitent une intervention manuelle pour les CAPTCHAs
- Blocage d'IP: Le scraping agressif peut entraîner le blocage de votre IP
Exemples de Code
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
url = 'https://webdesignernews.com/'
try:
# Send request to the main page
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Locate post containers
posts = soup.find_all('div', class_='single-post')
for post in posts:
title = post.find('h3').get_text(strip=True)
# Check if source site name exists
source = post.find('span', class_='site_name').get_text(strip=True) if post.find('span', class_='site_name') else 'Unknown'
link = post.find('h3').find('a')['href']
print(f'Title: {title} | Source: {source} | Link: {link}')
except Exception as e:
print(f'An error occurred: {e}')Quand Utiliser
Idéal pour les pages HTML statiques avec peu de JavaScript. Parfait pour les blogs, sites d'actualités et pages e-commerce simples.
Avantages
- ●Exécution la plus rapide (sans surcharge navigateur)
- ●Consommation de ressources minimale
- ●Facile à paralléliser avec asyncio
- ●Excellent pour les APIs et pages statiques
Limitations
- ●Ne peut pas exécuter JavaScript
- ●Échoue sur les SPAs et contenu dynamique
- ●Peut avoir des difficultés avec les systèmes anti-bot complexes
Comment Scraper Web Designer News avec du Code
Python + Requests
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
url = 'https://webdesignernews.com/'
try:
# Send request to the main page
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Locate post containers
posts = soup.find_all('div', class_='single-post')
for post in posts:
title = post.find('h3').get_text(strip=True)
# Check if source site name exists
source = post.find('span', class_='site_name').get_text(strip=True) if post.find('span', class_='site_name') else 'Unknown'
link = post.find('h3').find('a')['href']
print(f'Title: {title} | Source: {source} | Link: {link}')
except Exception as e:
print(f'An error occurred: {e}')Python + Playwright
from playwright.sync_api import sync_playwright
def scrape_wdn():
with sync_playwright() as p:
# Launch headless browser
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto('https://webdesignernews.com/')
# Wait for the post elements to load
page.wait_for_selector('.single-post')
posts = page.query_selector_all('.single-post')
for post in posts:
title_el = post.query_selector('h3 a')
if title_el:
title = title_el.inner_text()
link = title_el.get_attribute('href')
print(f'Scraped: {title} - {link}')
browser.close()
scrape_wdn()Python + Scrapy
import scrapy
class WdnSpider(scrapy.Spider):
name = 'wdn_spider'
start_urls = ['https://webdesignernews.com/']
def parse(self, response):
# Extract each post in the feed
for post in response.css('.single-post'):
yield {
'title': post.css('h3 a::text').get(),
'source': post.css('.site_name::text').get(),
'link': post.css('h3 a::attr(href)').get()
}
# Handle pagination by finding the 'Next' link
next_page = response.css('a.next::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://webdesignernews.com/', { waitUntil: 'domcontentloaded' });
// Evaluate the page to extract data fields
const results = await page.evaluate(() => {
const items = Array.from(document.querySelectorAll('.single-post'));
return items.map(item => ({
title: item.querySelector('h3 a') ? item.querySelector('h3 a').innerText : null,
source: item.querySelector('.site_name') ? item.querySelector('.site_name').innerText : null,
link: item.querySelector('h3 a') ? item.querySelector('h3 a').href : null
}));
});
console.log(results);
await browser.close();
})();Que Pouvez-Vous Faire Avec Les Données de Web Designer News
Explorez les applications pratiques et les insights des données de Web Designer News.
Flux d'actualités design automatisé
Créez une chaîne d'actualités en direct et sélectionnée pour les équipes de design professionnelles via Slack ou Discord.
Comment implémenter :
- 1Scrapez les articles les mieux notés toutes les 4 heures.
- 2Filtrez les résultats par tags de catégorie pertinents comme 'UX' ou 'Web Dev'.
- 3Envoyez les titres et résumés extraits vers un webhook de messagerie.
- 4Archivez les données pour suivre la popularité des outils de l'industrie à long terme.
Utilisez Automatio pour extraire des données de Web Designer News et créer ces applications sans écrire de code.
Que Pouvez-Vous Faire Avec Les Données de Web Designer News
- Flux d'actualités design automatisé
Créez une chaîne d'actualités en direct et sélectionnée pour les équipes de design professionnelles via Slack ou Discord.
- Scrapez les articles les mieux notés toutes les 4 heures.
- Filtrez les résultats par tags de catégorie pertinents comme 'UX' ou 'Web Dev'.
- Envoyez les titres et résumés extraits vers un webhook de messagerie.
- Archivez les données pour suivre la popularité des outils de l'industrie à long terme.
- Traqueur de tendances d'outils de design
Identifiez les logiciels ou bibliothèques de design qui gagnent le plus de terrain au sein de la communauté.
- Extrayez les titres et extraits des archives de la catégorie 'Resources'.
- Effectuez une analyse de fréquence de mots-clés sur des termes spécifiques (ex: 'Figma', 'React').
- Comparez la croissance des mentions d'un mois à l'autre pour identifier les tendances émergentes.
- Exportez des rapports visuels pour les équipes marketing ou de stratégie produit.
- Surveillance des backlinks concurrents
Identifiez les blogs ou agences qui réussissent à placer du contenu sur les hubs majeurs.
- Scrapez le champ 'Source Website Name' pour toutes les listes historiques.
- Agrégatez le nombre de mentions par domaine externe pour voir qui est le plus mis en avant.
- Analysez les types de contenu acceptés pour optimiser vos prises de contact.
- Identifiez des partenaires de collaboration potentiels dans l'espace du design.
- Jeu de données d'entraînement pour le machine learning
Utilisez les extraits et résumés sélectionnés pour entraîner des modèles de résumé technique.
- Scrapez plus de 10 000 titres d'articles et les résumés correspondants.
- Nettoyez les données textuelles pour supprimer les paramètres de suivi internes et le HTML.
- Utilisez le titre comme cible et l'extrait comme entrée pour le fine-tuning.
- Testez la performance du model sur de nouveaux articles de design non vus.
Optimisez votre flux de travail avec l'Automatisation IA
Automatio combine la puissance des agents IA, de l'automatisation web et des integrations intelligentes pour vous aider a accomplir plus en moins de temps.
Conseils Pro pour Scraper Web Designer News
Conseils d'experts pour extraire avec succès les données de Web Designer News.
Utiliser l'API REST
Accédez à l'API REST WordPress du site sur /wp-json/wp/v2/posts pour obtenir un flux JSON structuré et plus propre, beaucoup plus rapide à traiter que l'HTML brut.
Surveiller la barre latérale
Scrapez les sections 'Popular' et 'Recent' de la barre latérale pour donner la priorité aux contenus à fort engagement pour votre curation ou votre analyse.
Rotation des headers de navigateur
Utilisez toujours des chaînes User-Agent réalistes et effectuez une rotation pour imiter différents types de navigateurs, réduisant ainsi le risque d'être détecté par la sécurité Nginx.
Extraire les métadonnées de catégorie
Ciblez les classes CSS spécifiques aux catégories d'articles pour permettre un filtrage approfondi et une analyse thématique dans votre dataset final.
Gérer le lazy-loading des images
Les miniatures peuvent utiliser le lazy-loading ; assurez-vous que votre scraper cible les attributs 'data-src' ou 'srcset' pour ne pas manquer les ressources visuelles.
Implémenter des délais de requête
Un simple délai de 2 à 3 secondes entre les requêtes garantit que vous ne surchargez pas le serveur et aide votre activité de scraping à rester indétectable.
Témoignages
Ce Que Disent Nos Utilisateurs
Rejoignez des milliers d'utilisateurs satisfaits qui ont transforme leur flux de travail
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Associés Web Scraping




Questions Fréquentes sur Web Designer News
Trouvez des réponses aux questions courantes sur Web Designer News