Come fare lo scraping di Open Collective: Guida ai dati finanziari e dei contributori
Scopri come fare scraping di Open Collective per transazioni finanziarie, liste di contributori e dati di finanziamento dei progetti. Estrai insight...
Protezione Anti-Bot Rilevata
- Cloudflare
- WAF e gestione bot di livello enterprise. Usa sfide JavaScript, CAPTCHA e analisi comportamentale. Richiede automazione del browser con impostazioni stealth.
- Rate Limiting
- Limita le richieste per IP/sessione nel tempo. Può essere aggirato con proxy rotanti, ritardi nelle richieste e scraping distribuito.
- WAF
Informazioni Su Open Collective
Scopri cosa offre Open Collective e quali dati preziosi possono essere estratti.
Su Open Collective
Open Collective è una piattaforma finanziaria e legale unica, progettata per fornire trasparenza a organizzazioni guidate dalla community, progetti software open-source e associazioni di quartiere. Agendo come uno strumento di finanziamento decentralizzato, consente ai 'collettivi' di raccogliere fondi e gestire le spese senza la necessità di un'entità legale formale, utilizzando spesso host fiscali per il supporto amministrativo. Importanti progetti tecnologici come Babel e Webpack si affidano a questa piattaforma per gestire i propri ecosistemi finanziati dalla community.
La piattaforma è rinomata per la sua trasparenza radicale. Ogni transazione, che si tratti di una donazione da parte di una grande multinazionale o di una piccola spesa per un incontro della community, viene registrata ed è visibile pubblicamente. Ciò fornisce una ricchezza di dati riguardanti la salute finanziaria e le abitudini di spesa di alcune delle dipendenze open-source più critiche al mondo.
Lo scraping di Open Collective è di grande valore per le organizzazioni che desiderano condurre ricerche di mercato sull'economia open-source. Consente agli utenti di identificare opportunità di sponsorizzazione aziendale, tracciare le tendenze di finanziamento degli sviluppatori e verificare la sostenibilità finanziaria di progetti software critici. I dati servono come una finestra diretta sul flusso di capitale all'interno della comunità globale degli sviluppatori.
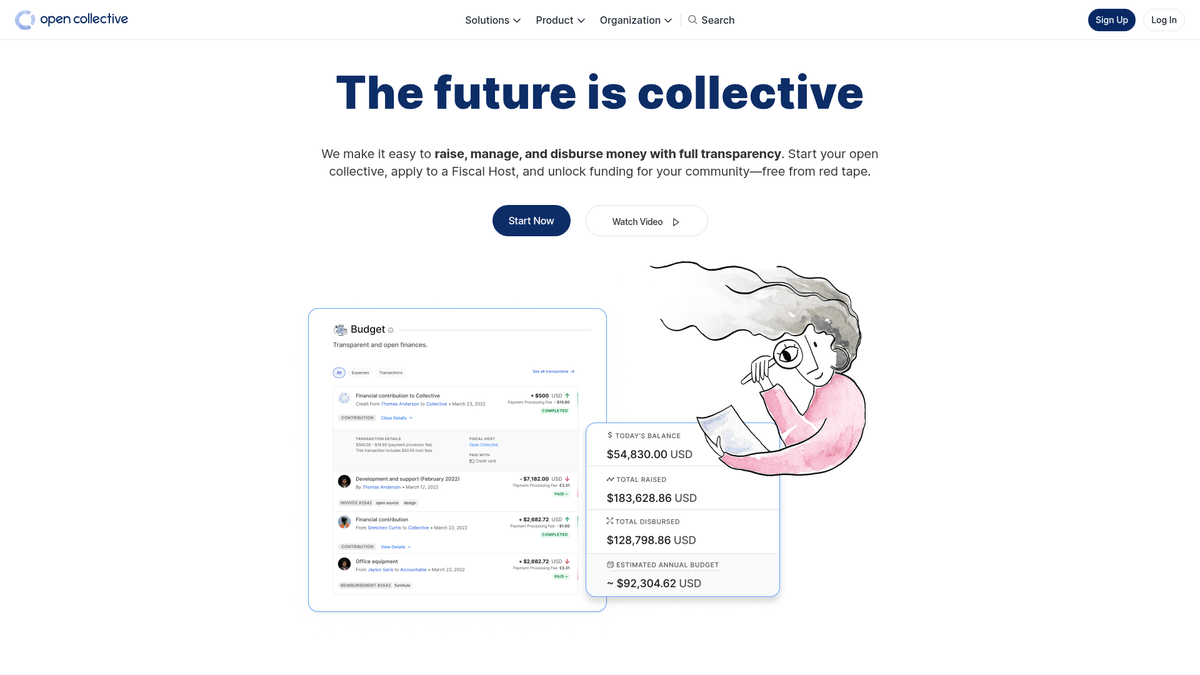
Perché Fare Scraping di Open Collective?
Scopri il valore commerciale e i casi d'uso per l'estrazione dati da Open Collective.
Analizzare la sostenibilità dell'open-source
Monitora la salute finanziaria e la redditività a lungo termine di progetti di infrastruttura tecnologica critica come Webpack, Babel e Logseq.
Ricerca di sponsorizzazioni aziendali
Identifica le organizzazioni che già sponsorizzano software open-source per creare un elenco mirato di potenziali lead per le tue iniziative.
Audit di trasparenza finanziaria
Monitora come i gruppi decentralizzati e i collettivi comunitari allocano i propri fondi per garantire la responsabilità nei confronti di donatori e stakeholder.
Scoperta dei trend di mercato
Valuta quali categorie, come tecnologia, attivismo ambientale o istruzione, stanno ricevendo la crescita maggiore nei finanziamenti della comunità.
Ricerca di contributori e influencer
Scopri i principali contributori individuali e aziendali all'interno di nicchie specifiche per trovare influencer chiave per attività di outreach o reclutamento.
Monitoraggio dell'impatto dei finanziamenti
Aggrega i dati su come i grandi finanziamenti vengono erogati su più progetti per misurare l'impatto reale della spesa filantropica.
Sfide dello Scraping
Sfide tecniche che potresti incontrare durante lo scraping di Open Collective.
Rendering pesante in JavaScript
Open Collective è costruito come una moderna applicazione web che richiede l'esecuzione completa di JavaScript per renderizzare i registri finanziari e le liste dei contributori.
Architettura GraphQL complessa
Il sito recupera i dati attraverso query GraphQL profondamente annidate, rendendo il parsing HTML tradizionale meno efficiente rispetto al monitoraggio delle risposte API.
Pattern di caricamento dinamico
Le cronologie delle transazioni e le liste dei membri utilizzano spesso lo scrolling infinito o pulsanti 'Carica altro' che richiedono un'automazione guidata dagli eventi per l'estrazione completa.
Cloudflare e rate limiting
Lo scraping ad alta frequenza può attivare il Web Application Firewall (WAF) di Cloudflare o comportare ban temporanei dell'IP a causa di rigidi limiti di frequenza globali.
Strutture dati annidate
Le informazioni su host fiscali, collettivi e spese sono distribuite su diversi livelli di pagina, richiedendo una navigazione complessa in più passaggi.
Scraping di Open Collective con l'IA
Nessun codice richiesto. Estrai dati in minuti con l'automazione basata sull'IA.
Come Funziona
Descrivi ciò di cui hai bisogno
Di' all'IA quali dati vuoi estrarre da Open Collective. Scrivi semplicemente in linguaggio naturale — nessun codice o selettore necessario.
L'IA estrae i dati
La nostra intelligenza artificiale naviga Open Collective, gestisce contenuti dinamici ed estrae esattamente ciò che hai richiesto.
Ottieni i tuoi dati
Ricevi dati puliti e strutturati pronti per l'esportazione in CSV, JSON o da inviare direttamente alle tue applicazioni.
Perché Usare l'IA per lo Scraping
L'IA rende facile lo scraping di Open Collective senza scrivere codice. La nostra piattaforma basata sull'intelligenza artificiale capisce quali dati vuoi — descrivili in linguaggio naturale e l'IA li estrae automaticamente.
How to scrape with AI:
- Descrivi ciò di cui hai bisogno: Di' all'IA quali dati vuoi estrarre da Open Collective. Scrivi semplicemente in linguaggio naturale — nessun codice o selettore necessario.
- L'IA estrae i dati: La nostra intelligenza artificiale naviga Open Collective, gestisce contenuti dinamici ed estrae esattamente ciò che hai richiesto.
- Ottieni i tuoi dati: Ricevi dati puliti e strutturati pronti per l'esportazione in CSV, JSON o da inviare direttamente alle tue applicazioni.
Why use AI for scraping:
- Estrazione dati visuale: Estrai record finanziari complessi e tabelle di contributori utilizzando un'interfaccia punta-e-clicca senza scrivere alcuna logica di query GraphQL.
- Gestione intelligente della paginazione: Gestisci automaticamente lo scroll infinito o i pulsanti 'Carica altro' per assicurarti che ogni singola spesa o donazione venga catturata dal registro.
- Programmazione del monitoraggio automatizzato: Configura un bot ricorrente per estrarre i dati ogni 24 ore, assicurandoti di avere sempre i saldi e i record delle transazioni più aggiornati.
- Aggirare le misure anti-bot: Utilizza la rotazione IP integrata e le funzionalità di interazione simile a quella umana per evitare di essere segnalato da Cloudflare durante lo scraping su larga scala.
- Esportazione diretta in JSON/CSV: Trasforma istantaneamente i dati web grezzi in formati strutturati pronti per l'analisi in Google Sheets, Excel o database interni.
Scraper Web No-Code per Open Collective
Alternative point-and-click allo scraping alimentato da IA
Diversi strumenti no-code come Browse.ai, Octoparse, Axiom e ParseHub possono aiutarti a fare scraping di Open Collective senza scrivere codice. Questi strumenti usano interfacce visive per selezionare i dati, anche se possono avere difficoltà con contenuti dinamici complessi o misure anti-bot.
Workflow Tipico con Strumenti No-Code
Sfide Comuni
Curva di apprendimento
Comprendere selettori e logica di estrazione richiede tempo
I selettori si rompono
Le modifiche al sito web possono rompere l'intero flusso di lavoro
Problemi con contenuti dinamici
I siti con molto JavaScript richiedono soluzioni complesse
Limitazioni CAPTCHA
La maggior parte degli strumenti richiede intervento manuale per i CAPTCHA
Blocco IP
Lo scraping aggressivo può portare al blocco del tuo IP
Scraper Web No-Code per Open Collective
Diversi strumenti no-code come Browse.ai, Octoparse, Axiom e ParseHub possono aiutarti a fare scraping di Open Collective senza scrivere codice. Questi strumenti usano interfacce visive per selezionare i dati, anche se possono avere difficoltà con contenuti dinamici complessi o misure anti-bot.
Workflow Tipico con Strumenti No-Code
- Installare l'estensione del browser o registrarsi sulla piattaforma
- Navigare verso il sito web target e aprire lo strumento
- Selezionare con point-and-click gli elementi dati da estrarre
- Configurare i selettori CSS per ogni campo dati
- Impostare le regole di paginazione per lo scraping di più pagine
- Gestire i CAPTCHA (spesso richiede risoluzione manuale)
- Configurare la pianificazione per le esecuzioni automatiche
- Esportare i dati in CSV, JSON o collegare tramite API
Sfide Comuni
- Curva di apprendimento: Comprendere selettori e logica di estrazione richiede tempo
- I selettori si rompono: Le modifiche al sito web possono rompere l'intero flusso di lavoro
- Problemi con contenuti dinamici: I siti con molto JavaScript richiedono soluzioni complesse
- Limitazioni CAPTCHA: La maggior parte degli strumenti richiede intervento manuale per i CAPTCHA
- Blocco IP: Lo scraping aggressivo può portare al blocco del tuo IP
Esempi di Codice
import requests
# L'endpoint GraphQL di Open Collective
url = 'https://api.opencollective.com/graphql/v2'
# Query GraphQL per ottenere informazioni di base su un collettivo
query = '''
query {
collective(slug: "webpack") {
name
stats {
totalAmountReceived { value }
balance { value }
}
}
}
'''
headers = {'Content-Type': 'application/json'}
try:
# Invio della richiesta POST all'API
response = requests.post(url, json={'query': query}, headers=headers)
response.raise_for_status()
data = response.json()
# Estrazione e stampa di nome e saldo
collective = data['data']['collective']
print(f"Nome: {collective['name']}")
print(f"Saldo: {collective['stats']['balance']['value']}")
except Exception as e:
print(f"Si è verificato un errore: {e}")Quando Usare
Ideale per pagine HTML statiche con JavaScript minimo. Perfetto per blog, siti di notizie e pagine prodotto e-commerce semplici.
Vantaggi
- ●Esecuzione più veloce (senza overhead del browser)
- ●Consumo risorse minimo
- ●Facile da parallelizzare con asyncio
- ●Ottimo per API e pagine statiche
Limitazioni
- ●Non può eseguire JavaScript
- ●Fallisce su SPA e contenuti dinamici
- ●Può avere difficoltà con sistemi anti-bot complessi
Come Fare Scraping di Open Collective con Codice
Python + Requests
import requests
# L'endpoint GraphQL di Open Collective
url = 'https://api.opencollective.com/graphql/v2'
# Query GraphQL per ottenere informazioni di base su un collettivo
query = '''
query {
collective(slug: "webpack") {
name
stats {
totalAmountReceived { value }
balance { value }
}
}
}
'''
headers = {'Content-Type': 'application/json'}
try:
# Invio della richiesta POST all'API
response = requests.post(url, json={'query': query}, headers=headers)
response.raise_for_status()
data = response.json()
# Estrazione e stampa di nome e saldo
collective = data['data']['collective']
print(f"Nome: {collective['name']}")
print(f"Saldo: {collective['stats']['balance']['value']}")
except Exception as e:
print(f"Si è verificato un errore: {e}")Python + Playwright
from playwright.sync_api import sync_playwright
def scrape_opencollective():
with sync_playwright() as p:
# Lancio del browser con supporto JS
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto('https://opencollective.com/discover')
# Attendi il caricamento delle schede dei collettivi
page.wait_for_selector('.CollectiveCard')
# Estrai i dati dal DOM
collectives = page.query_selector_all('.CollectiveCard')
for c in collectives:
name = c.query_selector('h2').inner_text()
print(f'Progetto trovato: {name}')
browser.close()
scrape_opencollective()Python + Scrapy
import scrapy
import json
class OpenCollectiveSpider(scrapy.Spider):
name = 'opencollective'
start_urls = ['https://opencollective.com/webpack']
def parse(self, response):
# Open Collective utilizza Next.js; i dati sono spesso all'interno di un tag script
next_data = response.xpath('//script[@id="__NEXT_DATA__"]/text()').get()
if next_data:
parsed_data = json.loads(next_data)
collective = parsed_data['props']['pageProps']['collective']
yield {
'name': collective.get('name'),
'balance': collective.get('stats', {}).get('balance'),
'currency': collective.get('currency')
}Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://opencollective.com/discover');
// Attendi il caricamento del contenuto dinamico
await page.waitForSelector('.CollectiveCard');
// Mappa gli elementi per estrarre i nomi
const data = await page.evaluate(() => {
return Array.from(document.querySelectorAll('.CollectiveCard')).map(el => ({
name: el.querySelector('h2').innerText
}));
});
console.log(data);
await browser.close();
})();Cosa Puoi Fare Con I Dati di Open Collective
Esplora applicazioni pratiche e insight dai dati di Open Collective.
Previsione della crescita Open Source
Identifica le tecnologie emergenti monitorando i tassi di crescita finanziaria di specifiche categorie di collettivi.
Come implementare:
- 1Estrarre le entrate mensili per i progetti principali in tag specifici
- 2Calcolare i tassi di crescita annuale composti (CAGR)
- 3Visualizzare lo stato dei finanziamenti del progetto per prevedere l'adozione tecnologica
Usa Automatio per estrarre dati da Open Collective e costruire queste applicazioni senza scrivere codice.
Cosa Puoi Fare Con I Dati di Open Collective
- Previsione della crescita Open Source
Identifica le tecnologie emergenti monitorando i tassi di crescita finanziaria di specifiche categorie di collettivi.
- Estrarre le entrate mensili per i progetti principali in tag specifici
- Calcolare i tassi di crescita annuale composti (CAGR)
- Visualizzare lo stato dei finanziamenti del progetto per prevedere l'adozione tecnologica
- Lead Generation per SaaS
Identifica progetti ben finanziati che potrebbero aver bisogno di strumenti per sviluppatori, hosting o servizi professionali.
- Filtrare i collettivi per budget e importo totale raccolto
- Estrarre le descrizioni dei progetti e gli URL dei siti web esterni
- Verificare lo stack tecnologico attraverso i repository GitHub collegati
- Audit della filantropia aziendale
Monitora dove le grandi aziende spendono i loro budget per i contributi open-source.
- Estrarre le liste dei contributori per i progetti principali
- Filtrare per profili aziendali rispetto ai profili individuali
- Aggregare gli importi dei contributi per entità aziendale
- Ricerca sull'impatto della community
Analizza come i gruppi decentralizzati distribuiscono i loro fondi per comprendere l'impatto sociale.
- Estrarre l'intero registro delle transazioni per un collettivo specifico
- Categorizzare le spese (viaggi, stipendi, hardware)
- Generare report sull'allocazione delle risorse all'interno dei gruppi della community
- Pipeline di reclutamento sviluppatori
Trova leader attivi in ecosistemi specifici basandoti sulla loro gestione della community e sulla cronologia dei contributi.
- Estrarre le liste dei membri dei principali collettivi tecnici
- Incrociare i contributori con i loro profili social pubblici
- Identificare i maintainer attivi per attività di outreach di alto livello
Potenzia il tuo workflow con l'automazione AI
Automatio combina la potenza degli agenti AI, dell'automazione web e delle integrazioni intelligenti per aiutarti a fare di piu in meno tempo.
Consigli Pro per lo Scraping di Open Collective
Consigli esperti per estrarre con successo i dati da Open Collective.
Estrarre tramite slug URL
Il modo più semplice per puntare a collettivi specifici è utilizzare i loro slug URL univoci, che possono essere raccolti dalla pagina di scoperta principale.
Cercare __NEXT_DATA__
Il codice sorgente della pagina contiene spesso un tag script con ID __NEXT_DATA__ che ospita JSON pre-renderizzato, il che può essere più veloce dello scraping dell'interfaccia utente.
Usare i selettori 'data-cy'
Punta agli attributi 'data-cy' nei tuoi selettori, poiché si tratta di ID di test che rimangono stabili anche quando le classi CSS cambiano durante gli aggiornamenti del sito.
Monitorare le richieste XHR
Usa gli strumenti per sviluppatori del browser per trovare le chiamate dirette all'endpoint GraphQL, poiché queste forniscono la struttura dati più pulita per le transazioni finanziarie.
Implementare ritardi casuali
Aggiungi tempi di attesa casuali tra 2 e 6 secondi per imitare la navigazione naturale e rimanere al di sotto dei radar dei sistemi di rilevamento bot automatizzati.
Sfruttare la documentazione ufficiale
Consulta la documentazione dell'API GraphQL di Open Collective per comprendere le convenzioni di denominazione per i diversi campi dei dati finanziari.
Testimonianze
Cosa dicono i nostri utenti
Unisciti a migliaia di utenti soddisfatti che hanno trasformato il loro workflow
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Correlati Web Scraping
How to Scrape Moon.ly | Step-by-Step NFT Data Extraction Guide
How to Scrape Yahoo Finance: Extract Stock Market Data
How to Scrape Rocket Mortgage: A Comprehensive Guide
How to Scrape jup.ag: Jupiter DEX Web Scraper Guide
How to Scrape Indiegogo: The Ultimate Crowdfunding Data Extraction Guide
How to Scrape ICO Drops: Comprehensive Crypto Data Guide
How to Scrape Crypto.com: Comprehensive Market Data Guide
How to Scrape Coinpaprika: Crypto Market Data Extraction Guide
Domande frequenti su Open Collective
Trova risposte alle domande comuni su Open Collective