Come fare lo scraping di Seeking Alpha: dati finanziari e trascrizioni
Scopri come fare lo scraping di Seeking Alpha per notizie azionarie, rating degli analisti e trascrizioni degli utili. Impara a superare Cloudflare ed estrarre...
Protezione Anti-Bot Rilevata
- Cloudflare
- WAF e gestione bot di livello enterprise. Usa sfide JavaScript, CAPTCHA e analisi comportamentale. Richiede automazione del browser con impostazioni stealth.
- DataDome
- Rilevamento bot in tempo reale con modelli ML. Analizza fingerprint del dispositivo, segnali di rete e pattern comportamentali. Comune nei siti e-commerce.
- Google reCAPTCHA
- Sistema CAPTCHA di Google. v2 richiede interazione utente, v3 funziona silenziosamente con punteggio di rischio. Può essere risolto con servizi CAPTCHA.
- Rate Limiting
- Limita le richieste per IP/sessione nel tempo. Può essere aggirato con proxy rotanti, ritardi nelle richieste e scraping distribuito.
- Blocco IP
- Blocca IP di data center noti e indirizzi segnalati. Richiede proxy residenziali o mobili per aggirare efficacemente.
Informazioni Su Seeking Alpha
Scopri cosa offre Seeking Alpha e quali dati preziosi possono essere estratti.
Il principale hub per l'intelligence finanziaria
Seeking Alpha è una piattaforma leader di ricerca finanziaria in crowdsourcing che funge da ponte vitale tra i dati di mercato grezzi e gli insight di investimento operativi. Ospita una vasta libreria di articoli di analisi, notizie di mercato in tempo reale e il repository più completo del web di trascrizioni di earnings call per migliaia di società quotate in borsa.
Un ecosistema di dati diversificato
La piattaforma offre una ricchezza di dati strutturati e non strutturati, inclusi suggerimenti azionari, cronologia dei dividendi e i rating proprietari Quant che battono il mercato. Gestito da un team editoriale professionale, il contenuto è generato da migliaia di analisti indipendenti i cui contributi devono soddisfare elevati standard di qualità e conformità prima della pubblicazione.
Valore strategico per l'estrazione dati
Fare scraping di Seeking Alpha è essenziale per gli analisti finanziari e i trader quantitativi che eseguono analisi del sentiment, tracciano i trend storici degli utili e monitorano le notizie su specifici ticker. I dati forniscono insight granulari sulla psicologia del mercato e sulle performance aziendali che possono essere utilizzati per costruire sofisticati model finanziari e condurre attività di competitive intelligence.
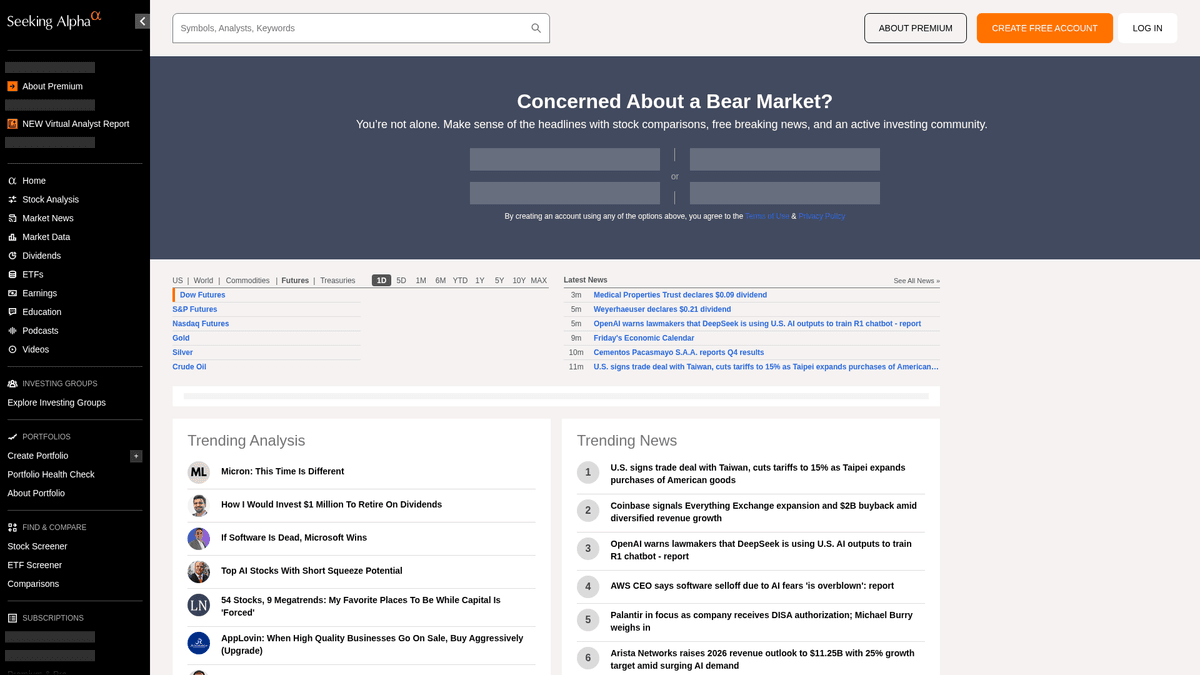
Perché Fare Scraping di Seeking Alpha?
Scopri il valore commerciale e i casi d'uso per l'estrazione dati da Seeking Alpha.
Analisi del sentiment
Estrai articoli e commenti crowdsourced per eseguire l'elaborazione del linguaggio naturale al fine di valutare il sentiment del mercato su specifici ticker azionari.
Intelligence sui risultati finanziari
Raccogli le trascrizioni delle conference call sugli utili per identificare le principali tendenze delle guidance aziendali, le prospettive finanziarie e il sentiment dei dirigenti in vari settori.
Rating Quant proprietari
Monitora gli esclusivi rating Quant di Seeking Alpha e i punteggi di convinzione degli analisti per alimentare segnali di trading automatizzati o strumenti di gestione del portafoglio.
Ricerca competitiva
Tieni traccia di ciò che dicono gli analisti più quotati sui competitor nel tuo settore per rimanere aggiornato sui cambiamenti dell'industria e sulle aspettative del mercato.
Archiviazione storica dei dati
Costruisci un repository privato delle raccomandazioni degli analisti e delle reazioni dei prezzi delle azioni per valutare l'accuratezza a lungo termine di specifici autori di investimenti.
Sfide dello Scraping
Sfide tecniche che potresti incontrare durante lo scraping di Seeking Alpha.
Rilevamento bot avanzato
Seeking Alpha impiega una sicurezza perimetrale sofisticata come Cloudflare e PerimeterX che monitorano i fingerprint dei browser automatizzati e i pattern comportamentali.
Paywall per contenuti premium
Molti dataset di alto valore, inclusi i parametri quantitativi dettagliati e le trascrizioni storiche, sono protetti da un abbonamento che richiede una gestione sicura della sessione.
Rendering dei contenuti dinamici
La piattaforma utilizza un framework React moderno, il che significa che i dati vengono spesso caricati in modo asincrono tramite richieste XHR invece di essere presenti nel sorgente HTML iniziale.
Rate limiting rigoroso
Frequenze di richiesta aggressive attivano rapidamente errori 403 Forbidden e ban temporanei dell'IP se il comportamento di scraping non imita quello di un utente umano.
Scraping di Seeking Alpha con l'IA
Nessun codice richiesto. Estrai dati in minuti con l'automazione basata sull'IA.
Come Funziona
Descrivi ciò di cui hai bisogno
Di' all'IA quali dati vuoi estrarre da Seeking Alpha. Scrivi semplicemente in linguaggio naturale — nessun codice o selettore necessario.
L'IA estrae i dati
La nostra intelligenza artificiale naviga Seeking Alpha, gestisce contenuti dinamici ed estrae esattamente ciò che hai richiesto.
Ottieni i tuoi dati
Ricevi dati puliti e strutturati pronti per l'esportazione in CSV, JSON o da inviare direttamente alle tue applicazioni.
Perché Usare l'IA per lo Scraping
L'IA rende facile lo scraping di Seeking Alpha senza scrivere codice. La nostra piattaforma basata sull'intelligenza artificiale capisce quali dati vuoi — descrivili in linguaggio naturale e l'IA li estrae automaticamente.
How to scrape with AI:
- Descrivi ciò di cui hai bisogno: Di' all'IA quali dati vuoi estrarre da Seeking Alpha. Scrivi semplicemente in linguaggio naturale — nessun codice o selettore necessario.
- L'IA estrae i dati: La nostra intelligenza artificiale naviga Seeking Alpha, gestisce contenuti dinamici ed estrae esattamente ciò che hai richiesto.
- Ottieni i tuoi dati: Ricevi dati puliti e strutturati pronti per l'esportazione in CSV, JSON o da inviare direttamente alle tue applicazioni.
Why use AI for scraping:
- Mascheramento stealth del fingerprint: Automatio ruota automaticamente i fingerprint e gli header del browser per bypassare i sistemi di rilevamento come Cloudflare senza richiedere configurazioni manuali.
- Supporto al rendering dinamico: L'architettura del browser headless dello strumento assicura che tutti i componenti basati su React e i grafici finanziari siano completamente renderizzati prima che inizi l'estrazione dei dati.
- Gestione delle sessioni no-code: Gestisci facilmente i login e i cookie persistenti per accedere alle trascrizioni premium e ai rating degli analisti senza scrivere complessi script di autenticazione.
- Selezione visiva dei dati: Seleziona visivamente i dati delle tabelle finanziarie complesse, garantendo un'estrazione stabile anche quando le classi CSS sottostanti o i layout di pagina cambiano.
Scraper Web No-Code per Seeking Alpha
Alternative point-and-click allo scraping alimentato da IA
Diversi strumenti no-code come Browse.ai, Octoparse, Axiom e ParseHub possono aiutarti a fare scraping di Seeking Alpha senza scrivere codice. Questi strumenti usano interfacce visive per selezionare i dati, anche se possono avere difficoltà con contenuti dinamici complessi o misure anti-bot.
Workflow Tipico con Strumenti No-Code
Sfide Comuni
Curva di apprendimento
Comprendere selettori e logica di estrazione richiede tempo
I selettori si rompono
Le modifiche al sito web possono rompere l'intero flusso di lavoro
Problemi con contenuti dinamici
I siti con molto JavaScript richiedono soluzioni complesse
Limitazioni CAPTCHA
La maggior parte degli strumenti richiede intervento manuale per i CAPTCHA
Blocco IP
Lo scraping aggressivo può portare al blocco del tuo IP
Scraper Web No-Code per Seeking Alpha
Diversi strumenti no-code come Browse.ai, Octoparse, Axiom e ParseHub possono aiutarti a fare scraping di Seeking Alpha senza scrivere codice. Questi strumenti usano interfacce visive per selezionare i dati, anche se possono avere difficoltà con contenuti dinamici complessi o misure anti-bot.
Workflow Tipico con Strumenti No-Code
- Installare l'estensione del browser o registrarsi sulla piattaforma
- Navigare verso il sito web target e aprire lo strumento
- Selezionare con point-and-click gli elementi dati da estrarre
- Configurare i selettori CSS per ogni campo dati
- Impostare le regole di paginazione per lo scraping di più pagine
- Gestire i CAPTCHA (spesso richiede risoluzione manuale)
- Configurare la pianificazione per le esecuzioni automatiche
- Esportare i dati in CSV, JSON o collegare tramite API
Sfide Comuni
- Curva di apprendimento: Comprendere selettori e logica di estrazione richiede tempo
- I selettori si rompono: Le modifiche al sito web possono rompere l'intero flusso di lavoro
- Problemi con contenuti dinamici: I siti con molto JavaScript richiedono soluzioni complesse
- Limitazioni CAPTCHA: La maggior parte degli strumenti richiede intervento manuale per i CAPTCHA
- Blocco IP: Lo scraping aggressivo può portare al blocco del tuo IP
Esempi di Codice
import requests
from bs4 import BeautifulSoup
# URL per le ultime notizie di mercato
url = 'https://seekingalpha.com/market-news'
# Header browser standard per imitare il comportamento umano
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'Accept-Language': 'it-IT,it;q=0.9,en-US;q=0.8,en;q=0.7',
'Referer': 'https://seekingalpha.com/'
}
def scrape_sa_news():
try:
response = requests.get(url, headers=headers, timeout=10)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
# Estrai i titoli utilizzando gli attributi data-test-id
headlines = soup.find_all('a', {'data-test-id': 'post-list-item-title'})
for item in headlines:
print(f'Titolo Notizia: {item.text.strip()}')
else:
print(f'Bloccato con stato: {response.status_code}')
except Exception as e:
print(f'Si è verificato un errore: {e}')
if __name__ == "__main__":
scrape_sa_news()Quando Usare
Ideale per pagine HTML statiche con JavaScript minimo. Perfetto per blog, siti di notizie e pagine prodotto e-commerce semplici.
Vantaggi
- ●Esecuzione più veloce (senza overhead del browser)
- ●Consumo risorse minimo
- ●Facile da parallelizzare con asyncio
- ●Ottimo per API e pagine statiche
Limitazioni
- ●Non può eseguire JavaScript
- ●Fallisce su SPA e contenuti dinamici
- ●Può avere difficoltà con sistemi anti-bot complessi
Come Fare Scraping di Seeking Alpha con Codice
Python + Requests
import requests
from bs4 import BeautifulSoup
# URL per le ultime notizie di mercato
url = 'https://seekingalpha.com/market-news'
# Header browser standard per imitare il comportamento umano
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'Accept-Language': 'it-IT,it;q=0.9,en-US;q=0.8,en;q=0.7',
'Referer': 'https://seekingalpha.com/'
}
def scrape_sa_news():
try:
response = requests.get(url, headers=headers, timeout=10)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
# Estrai i titoli utilizzando gli attributi data-test-id
headlines = soup.find_all('a', {'data-test-id': 'post-list-item-title'})
for item in headlines:
print(f'Titolo Notizia: {item.text.strip()}')
else:
print(f'Bloccato con stato: {response.status_code}')
except Exception as e:
print(f'Si è verificato un errore: {e}')
if __name__ == "__main__":
scrape_sa_news()Python + Playwright
from playwright.sync_api import sync_playwright
def run(playwright):
# Avvio di un browser Chromium
browser = playwright.chromium.launch(headless=True)
context = browser.new_context(
user_agent='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
)
page = context.new_page()
try:
# Navigazione verso la pagina delle trascrizioni di un ticker specifico
page.goto('https://seekingalpha.com/symbol/AAPL/transcripts')
# Attendi che il contenuto principale venga renderizzato dinamicamente
page.wait_for_selector('article', timeout=15000)
# Individua ed estrai i titoli delle trascrizioni
titles = page.locator('h3').all_inner_texts()
for title in titles:
print(f'Trascrizione trovata: {title}')
except Exception as e:
print(f'Estrazione fallita: {e}')
finally:
browser.close()
with sync_playwright() as playwright:
run(playwright)Python + Scrapy
import scrapy
class SeekingAlphaSpider(scrapy.Spider):
name = 'sa_spider'
allowed_domains = ['seekingalpha.com']
start_urls = ['https://seekingalpha.com/latest-articles']
custom_settings = {
'DOWNLOAD_DELAY': 8,
'USER_AGENT': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/120.0.0.0',
'ROBOTSTXT_OBEY': False,
'COOKIES_ENABLED': True
}
def parse(self, response):
for article in response.css('article'):
yield {
'title': article.css('h3 a::text').get(),
'link': response.urljoin(article.css('h3 a::attr(href)').get()),
'author': article.css('span[data-test-id="author-name"]::text').get()
}
# Gestione della paginazione semplice tramite link 'next'
next_page = response.css('a.next_page::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
// Imposta uno User-Agent di alta qualità
await page.setUserAgent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36');
try {
// Naviga verso la homepage di Seeking Alpha
await page.goto('https://seekingalpha.com/', { waitUntil: 'networkidle2' });
// Valuta gli script nel contesto del browser per estrarre i titoli
const trending = await page.evaluate(() => {
const nodes = Array.from(document.querySelectorAll('h3'));
return nodes.map(n => n.innerText.trim());
});
console.log('Contenuti di Tendenza:', trending);
} catch (err) {
console.error('Errore riscontrato da Puppeteer:', err);
} finally {
await browser.close();
}
})();Cosa Puoi Fare Con I Dati di Seeking Alpha
Esplora applicazioni pratiche e insight dai dati di Seeking Alpha.
Analisi quantitativa del sentiment
Le società finanziarie utilizzano gli articoli degli analisti per determinare il sentiment del mercato per specifici settori azionari.
Come implementare:
- 1Estrarre tutti gli articoli di analisi per un ticker di un settore specifico.
- 2Elaborare il contenuto attraverso un motore NLP per calcolare la polarità del sentiment.
- 3Integrare i punteggi di sentiment negli algoritmi di trading esistenti.
- 4Attivare avvisi automatici di acquisto/vendita basati sui cambiamenti del sentiment.
Usa Automatio per estrarre dati da Seeking Alpha e costruire queste applicazioni senza scrivere codice.
Cosa Puoi Fare Con I Dati di Seeking Alpha
- Analisi quantitativa del sentiment
Le società finanziarie utilizzano gli articoli degli analisti per determinare il sentiment del mercato per specifici settori azionari.
- Estrarre tutti gli articoli di analisi per un ticker di un settore specifico.
- Elaborare il contenuto attraverso un motore NLP per calcolare la polarità del sentiment.
- Integrare i punteggi di sentiment negli algoritmi di trading esistenti.
- Attivare avvisi automatici di acquisto/vendita basati sui cambiamenti del sentiment.
- Estrazione di insight dagli utili
Estrarre la guidance aziendale critica direttamente dalle trascrizioni degli utili per una reportistica rapida.
- Automatizzare lo scraping giornaliero della sezione Earnings Transcripts.
- Cercare parole chiave finanziarie specifiche come 'EBITDA' o 'Outlook'.
- Isolare le frasi contenenti le metriche di guidance del management.
- Esportare i risultati in un CSV strutturato per la revisione del comitato d'investimento.
- Benchmarking del rendimento dei dividendi
Confrontare le performance dei dividendi su migliaia di titoli per trovare opportunità di rendimento.
- Estrarre la cronologia dei dividendi e i payout ratio per una lista definita di azioni.
- Calcolare il rendimento medio rispetto ai trend storici utilizzando i dati estratti.
- Identificare i titoli che hanno recentemente aumentato la loro distribuzione.
- Aggiornare una dashboard privata con confronti dei rendimenti in tempo reale.
- Tracciamento delle performance degli analisti
Identificare gli autori con alta accuratezza da seguire per ottenere migliori idee di investimento.
- Estrarre rating storici e articoli degli autori con le valutazioni più alte.
- Incrociare le date di pubblicazione degli articoli con la performance del prezzo delle azioni.
- Classificare gli autori in base all'accuratezza delle loro raccomandazioni 'Buy' o 'Sell'.
- Inviare notifiche automatiche quando gli autori con ranking elevato pubblicano nuove idee.
Potenzia il tuo workflow con l'automazione AI
Automatio combina la potenza degli agenti AI, dell'automazione web e delle integrazioni intelligenti per aiutarti a fare di piu in meno tempo.
Consigli Pro per lo Scraping di Seeking Alpha
Consigli esperti per estrarre con successo i dati da Seeking Alpha.
Priorità ai proxy residenziali
Seeking Alpha mette in blacklist la maggior parte degli IP datacenter; l'uso di proxy residenziali fa apparire il tuo traffico come quello di legittimi utenti internet domestici.
Punta agli endpoint delle API interne
Ispeziona il traffico di rete per trovare chiamate API interne basate su JSON (v3/api), che sono spesso più facili da analizzare rispetto alle strutture HTML grezze.
Implementa ritardi simili a quelli umani
Rendi casuali i tempi di interazione e mantieni basso il volume delle richieste per evitare di attivare i sistemi di rilevamento comportamentale che cercano pattern robotici.
Usa gli attributi data per i selettori
Punta agli attributi 'data-test-id' nei tuoi selettori, poiché è meno probabile che cambino durante gli aggiornamenti del sito rispetto alle classi CSS dinamiche di React.
Esegui lo scraping nelle ore non di punta
Effettua la raccolta dati su larga scala durante la chiusura del mercato o nei fine settimana per ridurre il rischio di attivare i limiti di frequenza per traffico elevato.
Testimonianze
Cosa dicono i nostri utenti
Unisciti a migliaia di utenti soddisfatti che hanno trasformato il loro workflow
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Correlati Web Scraping
How to Scrape Moon.ly | Step-by-Step NFT Data Extraction Guide
How to Scrape Yahoo Finance: Extract Stock Market Data
How to Scrape Rocket Mortgage: A Comprehensive Guide
How to Scrape Open Collective: Financial and Contributor Data Guide
How to Scrape jup.ag: Jupiter DEX Web Scraper Guide
How to Scrape Indiegogo: The Ultimate Crowdfunding Data Extraction Guide
How to Scrape ICO Drops: Comprehensive Crypto Data Guide
How to Scrape Crypto.com: Comprehensive Market Data Guide
Domande frequenti su Seeking Alpha
Trova risposte alle domande comuni su Seeking Alpha