Come fare scraping di Web Designer News
Scopri come fare lo scraping di Web Designer News per estrarre storie di design di tendenza, URL di origine e timestamp. Ideale per il monitoraggio dei trend...
Informazioni Su Web Designer News
Scopri cosa offre Web Designer News e quali dati preziosi possono essere estratti.
Panoramica di Web Designer News
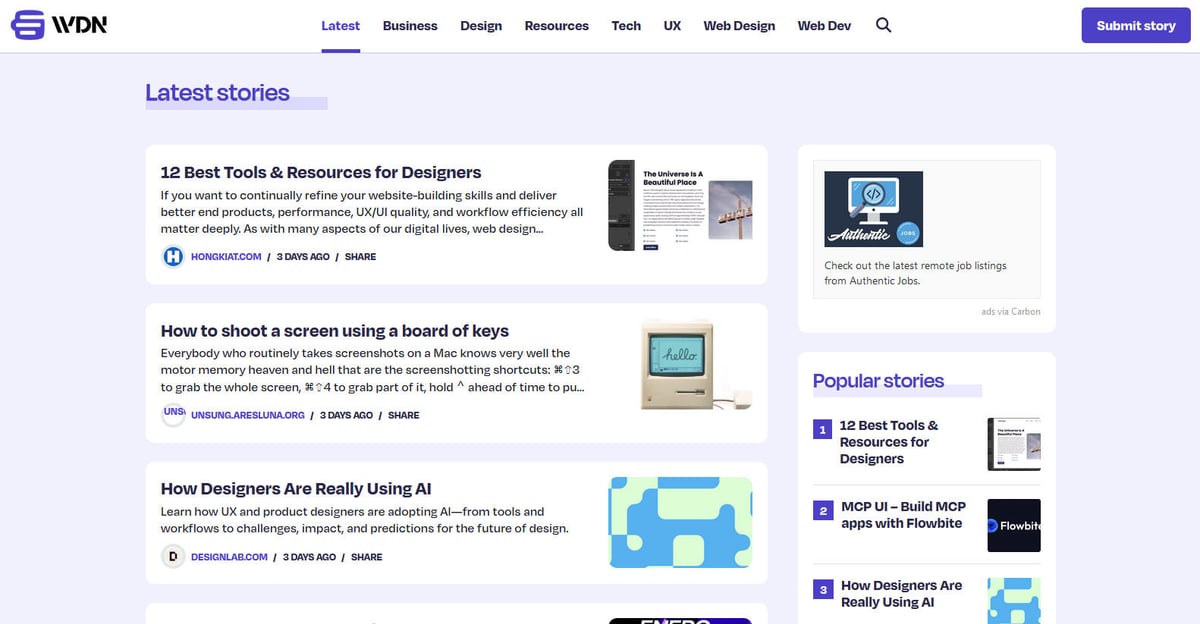
Web Designer News è un principale aggregatore di notizie guidato dalla community, curato specificamente per l'ecosistema del web design e dello sviluppo. Fin dalla sua nascita, la piattaforma ha funzionato come un hub centrale dove i professionisti scoprono una selezione accurata delle notizie, tutorial, strumenti e risorse più rilevanti da tutto il web. Copre un ampio spettro di argomenti tra cui UX design, strategie di business, aggiornamenti tecnologici e graphic design, presentati in un feed cronologico pulito.
Architettura del Sito e Potenziale dei Dati
L'architettura del sito è costruita su WordPress, con un layout altamente strutturato che organizza i contenuti in categorie specifiche come 'Web Design', 'Web Dev', 'UX' e 'Resources'. Poiché aggrega dati da migliaia di singoli blog e riviste in un'unica interfaccia ricercabile, funge da filtro di alta qualità per l'intelligence di settore. Questa struttura lo rende un bersaglio ideale per il web scraping, in quanto fornisce accesso a un flusso pre-verificato di dati industriali di alto valore senza la necessità di scansionare centinaia di domini separati.
Perché Fare Scraping di Web Designer News?
Scopri il valore commerciale e i casi d'uso per l'estrazione dati da Web Designer News.
Scoperta di trend in tempo reale
Individua i framework di design emergenti, le librerie UI e gli strumenti di prototipazione nel momento in cui guadagnano trazione nella comunità professionale.
Curatela automatizzata dei contenuti
Mantieni aggiornati il tuo blog di design, la tua newsletter o i tuoi canali social aggregando le storie di più alta qualità selezionate dagli esperti del settore.
Market Intelligence
Identifica quali agenzie di design e software house producono costantemente contenuti virali o selezionati editorialmente per comprendere i leader di mercato.
SEO e ricerca di keyword
Analizza i titoli e gli snippet delle storie di tendenza per identificare le keyword e gli argomenti più rilevanti che catturano l'attenzione del settore.
Archiviazione storica del settore
Costruisci un database a lungo termine sull'evoluzione del web design per tracciare come specifici stili, standard di codifica e tecnologie fluttuano in popolarità nel corso degli anni.
Lead generation B2B
Scopri nuove startup e agenzie presentate sulla piattaforma per identificare potenziali partner o clienti nello spazio della tecnologia creativa.
Sfide dello Scraping
Sfide tecniche che potresti incontrare durante lo scraping di Web Designer News.
Redirect di tracciamento interni
Il sito web utilizza link '/go/' interni per il traffico in uscita, il che significa che uno scraper deve seguire i redirect per estrarre l'URL sorgente effettivo.
Parsing delle date relative
I timestamp sono spesso visualizzati in formati relativi come '5 ore fa', richiedendo una logica personalizzata per convertirli in formati di data ISO standardizzati.
Problemi di coerenza dei dati
Alcuni post presentano snippet descrittivi completi e categorie, mentre altri forniscono solo un titolo, rendendo difficile mantenere una struttura di database uniforme.
Rate limiting lato server
L'infrastruttura basata su Nginx può rilevare e limitare le richieste ad alta frequenza, rendendo necessario l'uso di ritardi e header rotanti per evitare blocchi IP.
Scraping di Web Designer News con l'IA
Nessun codice richiesto. Estrai dati in minuti con l'automazione basata sull'IA.
Come Funziona
Descrivi ciò di cui hai bisogno
Di' all'IA quali dati vuoi estrarre da Web Designer News. Scrivi semplicemente in linguaggio naturale — nessun codice o selettore necessario.
L'IA estrae i dati
La nostra intelligenza artificiale naviga Web Designer News, gestisce contenuti dinamici ed estrae esattamente ciò che hai richiesto.
Ottieni i tuoi dati
Ricevi dati puliti e strutturati pronti per l'esportazione in CSV, JSON o da inviare direttamente alle tue applicazioni.
Perché Usare l'IA per lo Scraping
L'IA rende facile lo scraping di Web Designer News senza scrivere codice. La nostra piattaforma basata sull'intelligenza artificiale capisce quali dati vuoi — descrivili in linguaggio naturale e l'IA li estrae automaticamente.
How to scrape with AI:
- Descrivi ciò di cui hai bisogno: Di' all'IA quali dati vuoi estrarre da Web Designer News. Scrivi semplicemente in linguaggio naturale — nessun codice o selettore necessario.
- L'IA estrae i dati: La nostra intelligenza artificiale naviga Web Designer News, gestisce contenuti dinamici ed estrae esattamente ciò che hai richiesto.
- Ottieni i tuoi dati: Ricevi dati puliti e strutturati pronti per l'esportazione in CSV, JSON o da inviare direttamente alle tue applicazioni.
Why use AI for scraping:
- Gestione visuale dei redirect: Automatio può essere configurato per seguire automaticamente i link 'go' interni e catturare l'URL di destinazione finale senza scrivere complesse logiche di reindirizzamento.
- Paginazione No-Code: Naviga senza sforzo attraverso le estese pagine dell'archivio del sito semplicemente selezionando il pulsante 'Successivo' nell'interfaccia punta-e-clicca.
- Pianificazione basata su cloud: Esegui i tuoi scraper con una programmazione giornaliera ricorrente nel cloud, in modo che il tuo database di notizie sul design rimanga aggiornato senza interventi manuali.
- Sincronizzazione di dati strutturati: Esporta direttamente i dati delle notizie estratti su Google Sheets, Webflow o tramite API per alimentare istantaneamente le tue applicazioni dedicate al design.
Scraper Web No-Code per Web Designer News
Alternative point-and-click allo scraping alimentato da IA
Diversi strumenti no-code come Browse.ai, Octoparse, Axiom e ParseHub possono aiutarti a fare scraping di Web Designer News senza scrivere codice. Questi strumenti usano interfacce visive per selezionare i dati, anche se possono avere difficoltà con contenuti dinamici complessi o misure anti-bot.
Workflow Tipico con Strumenti No-Code
Sfide Comuni
Curva di apprendimento
Comprendere selettori e logica di estrazione richiede tempo
I selettori si rompono
Le modifiche al sito web possono rompere l'intero flusso di lavoro
Problemi con contenuti dinamici
I siti con molto JavaScript richiedono soluzioni complesse
Limitazioni CAPTCHA
La maggior parte degli strumenti richiede intervento manuale per i CAPTCHA
Blocco IP
Lo scraping aggressivo può portare al blocco del tuo IP
Scraper Web No-Code per Web Designer News
Diversi strumenti no-code come Browse.ai, Octoparse, Axiom e ParseHub possono aiutarti a fare scraping di Web Designer News senza scrivere codice. Questi strumenti usano interfacce visive per selezionare i dati, anche se possono avere difficoltà con contenuti dinamici complessi o misure anti-bot.
Workflow Tipico con Strumenti No-Code
- Installare l'estensione del browser o registrarsi sulla piattaforma
- Navigare verso il sito web target e aprire lo strumento
- Selezionare con point-and-click gli elementi dati da estrarre
- Configurare i selettori CSS per ogni campo dati
- Impostare le regole di paginazione per lo scraping di più pagine
- Gestire i CAPTCHA (spesso richiede risoluzione manuale)
- Configurare la pianificazione per le esecuzioni automatiche
- Esportare i dati in CSV, JSON o collegare tramite API
Sfide Comuni
- Curva di apprendimento: Comprendere selettori e logica di estrazione richiede tempo
- I selettori si rompono: Le modifiche al sito web possono rompere l'intero flusso di lavoro
- Problemi con contenuti dinamici: I siti con molto JavaScript richiedono soluzioni complesse
- Limitazioni CAPTCHA: La maggior parte degli strumenti richiede intervento manuale per i CAPTCHA
- Blocco IP: Lo scraping aggressivo può portare al blocco del tuo IP
Esempi di Codice
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
url = 'https://webdesignernews.com/'
try:
# Invia la richiesta alla pagina principale
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Individua i contenitori dei post
posts = soup.find_all('div', class_='single-post')
for post in posts:
title = post.find('h3').get_text(strip=True)
# Verifica se il nome del sito sorgente esiste
source = post.find('span', class_='site_name').get_text(strip=True) if post.find('span', class_='site_name') else 'Unknown'
link = post.find('h3').find('a')['href']
print(f'Title: {title} | Source: {source} | Link: {link}')
except Exception as e:
print(f'Si è verificato un errore: {e}')Quando Usare
Ideale per pagine HTML statiche con JavaScript minimo. Perfetto per blog, siti di notizie e pagine prodotto e-commerce semplici.
Vantaggi
- ●Esecuzione più veloce (senza overhead del browser)
- ●Consumo risorse minimo
- ●Facile da parallelizzare con asyncio
- ●Ottimo per API e pagine statiche
Limitazioni
- ●Non può eseguire JavaScript
- ●Fallisce su SPA e contenuti dinamici
- ●Può avere difficoltà con sistemi anti-bot complessi
Come Fare Scraping di Web Designer News con Codice
Python + Requests
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
url = 'https://webdesignernews.com/'
try:
# Invia la richiesta alla pagina principale
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Individua i contenitori dei post
posts = soup.find_all('div', class_='single-post')
for post in posts:
title = post.find('h3').get_text(strip=True)
# Verifica se il nome del sito sorgente esiste
source = post.find('span', class_='site_name').get_text(strip=True) if post.find('span', class_='site_name') else 'Unknown'
link = post.find('h3').find('a')['href']
print(f'Title: {title} | Source: {source} | Link: {link}')
except Exception as e:
print(f'Si è verificato un errore: {e}')Python + Playwright
from playwright.sync_api import sync_playwright
def scrape_wdn():
with sync_playwright() as p:
# Avvia il browser headless
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto('https://webdesignernews.com/')
# Attende il caricamento degli elementi del post
page.wait_for_selector('.single-post')
posts = page.query_selector_all('.single-post')
for post in posts:
title_el = post.query_selector('h3 a')
if title_el:
title = title_el.inner_text()
link = title_el.get_attribute('href')
print(f'Scraped: {title} - {link}')
browser.close()
scrape_wdn()Python + Scrapy
import scrapy
class WdnSpider(scrapy.Spider):
name = 'wdn_spider'
start_urls = ['https://webdesignernews.com/']
def parse(self, response):
# Estrae ogni post nel feed
for post in response.css('.single-post'):
yield {
'title': post.css('h3 a::text').get(),
'source': post.css('.site_name::text').get(),
'link': post.css('h3 a::attr(href)').get()
}
# Gestisce la paginazione cercando il link 'Next'
next_page = response.css('a.next::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://webdesignernews.com/', { waitUntil: 'domcontentloaded' });
// Valuta la pagina per estrarre i campi dati
const results = await page.evaluate(() => {
const items = Array.from(document.querySelectorAll('.single-post'));
return items.map(item => ({
title: item.querySelector('h3 a') ? item.querySelector('h3 a').innerText : null,
source: item.querySelector('.site_name') ? item.querySelector('.site_name').innerText : null,
link: item.querySelector('h3 a') ? item.querySelector('h3 a').href : null
}));
});
console.log(results);
await browser.close();
})();Cosa Puoi Fare Con I Dati di Web Designer News
Esplora applicazioni pratiche e insight dai dati di Web Designer News.
Feed di Notizie Design Automatizzato
Crea un canale di notizie curato in tempo reale per team di design professionisti via Slack o Discord.
Come implementare:
- 1Estrai le storie più votate ogni 4 ore.
- 2Filtra i risultati per tag di categoria rilevanti come 'UX' o 'Web Dev'.
- 3Invia i titoli e i riassunti estratti a un webhook di messaggistica.
- 4Archivia i dati per monitorare la popolarità a lungo termine degli strumenti del settore.
Usa Automatio per estrarre dati da Web Designer News e costruire queste applicazioni senza scrivere codice.
Cosa Puoi Fare Con I Dati di Web Designer News
- Feed di Notizie Design Automatizzato
Crea un canale di notizie curato in tempo reale per team di design professionisti via Slack o Discord.
- Estrai le storie più votate ogni 4 ore.
- Filtra i risultati per tag di categoria rilevanti come 'UX' o 'Web Dev'.
- Invia i titoli e i riassunti estratti a un webhook di messaggistica.
- Archivia i dati per monitorare la popolarità a lungo termine degli strumenti del settore.
- Tracker dei Trend per Strumenti di Design
Identifica quali software di design o librerie stanno guadagnando più trazione nella community.
- Estrai titoli ed excerpt dall'archivio della categoria 'Resources'.
- Esegui un'analisi della frequenza delle parole chiave su termini specifici (es. 'Figma', 'React').
- Confronta la crescita delle menzioni mese su mese per identificare i trend emergenti.
- Esporta report visivi per i team di marketing o strategia di prodotto.
- Monitoraggio Backlink dei Competitor
Identifica quali blog o agenzie riescono a posizionare contenuti sui principali hub.
- Estrai il campo 'Source Website Name' per tutti i post storici.
- Aggrega il conteggio delle menzioni per dominio esterno per vedere chi viene presentato più spesso.
- Analizza i tipi di contenuto che vengono accettati per migliorare l'outreach.
- Identifica potenziali partner di collaborazione nello spazio del design.
- Dataset di Addestramento per Machine Learning
Usa gli snippet e i riassunti curati per addestrare modelli di sintesi tecnica.
- Estrai oltre 10.000 titoli di storie e i corrispondenti riassunti degli excerpt.
- Pulisci i dati testuali per rimuovere i parametri di tracciamento interni e l'HTML.
- Usa il titolo come target e l'excerpt come input per il fine-tuning.
- Testa il model su nuovi articoli di design non inclusi per valutarne le performance.
Potenzia il tuo workflow con l'automazione AI
Automatio combina la potenza degli agenti AI, dell'automazione web e delle integrazioni intelligenti per aiutarti a fare di piu in meno tempo.
Consigli Pro per lo Scraping di Web Designer News
Consigli esperti per estrarre con successo i dati da Web Designer News.
Utilizza la REST API
Accedi alla REST API di WordPress del sito all'indirizzo /wp-json/wp/v2/posts per ottenere un feed JSON strutturato e pulito, molto più veloce da elaborare rispetto all'HTML grezzo.
Monitora la barra laterale
Estrai i dati dalle sezioni 'Popular' e 'Recent' della barra laterale per dare priorità ai contenuti con il più alto livello di engagement per la tua analisi o curatela.
Ruota gli header del browser
Utilizza sempre stringhe User-Agent realistiche e ruotale per imitare diversi tipi di browser, riducendo il rischio di essere segnalati dai sistemi di sicurezza Nginx.
Estrai i metadati delle categorie
Punta alle classi CSS specifiche per le categorie dei post per consentire un filtraggio approfondito e un'analisi tematica nel tuo dataset finale.
Gestisci il caricamento differito delle immagini
Le immagini in miniatura potrebbero utilizzare il lazy-loading; assicurati che il tuo scraper punti agli attributi 'data-src' o 'srcset' per evitare di perdere gli asset visivi.
Implementa ritardi tra le richieste
Un semplice ritardo di 2-3 secondi tra le richieste assicura di non sovraccaricare il server e aiuta la tua attività di scraping a non essere rilevata.
Testimonianze
Cosa dicono i nostri utenti
Unisciti a migliaia di utenti soddisfatti che hanno trasformato il loro workflow
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Correlati Web Scraping




Domande frequenti su Web Designer News
Trova risposte alle domande comuni su Web Designer News