Seeking Alphaのスクレイピング方法:金融データとトランスクリプトの取得
株価ニュース、アナリストの評価、決算説明会のトランスクリプトを収集するためのSeeking Alphaのスクレイピング方法を解説します。Cloudflareを回避し、金融インサイトを抽出する方法を学びましょう。
ボット対策検出
- Cloudflare
- エンタープライズ級のWAFとボット管理。JavaScriptチャレンジ、CAPTCHA、行動分析を使用。ステルス設定でのブラウザ自動化が必要。
- DataDome
- MLモデルによるリアルタイムボット検出。デバイスフィンガープリント、ネットワーク信号、行動パターンを分析。ECサイトで一般的。
- Google reCAPTCHA
- GoogleのCAPTCHAシステム。v2はユーザー操作が必要、v3はリスクスコアリングでサイレント動作。CAPTCHAサービスで解決可能。
- レート制限
- 時間あたりのIP/セッションごとのリクエストを制限。ローテーションプロキシ、リクエスト遅延、分散スクレイピングで回避可能。
- IPブロック
- 既知のデータセンターIPとフラグ付きアドレスをブロック。効果的に回避するにはレジデンシャルまたはモバイルプロキシが必要。
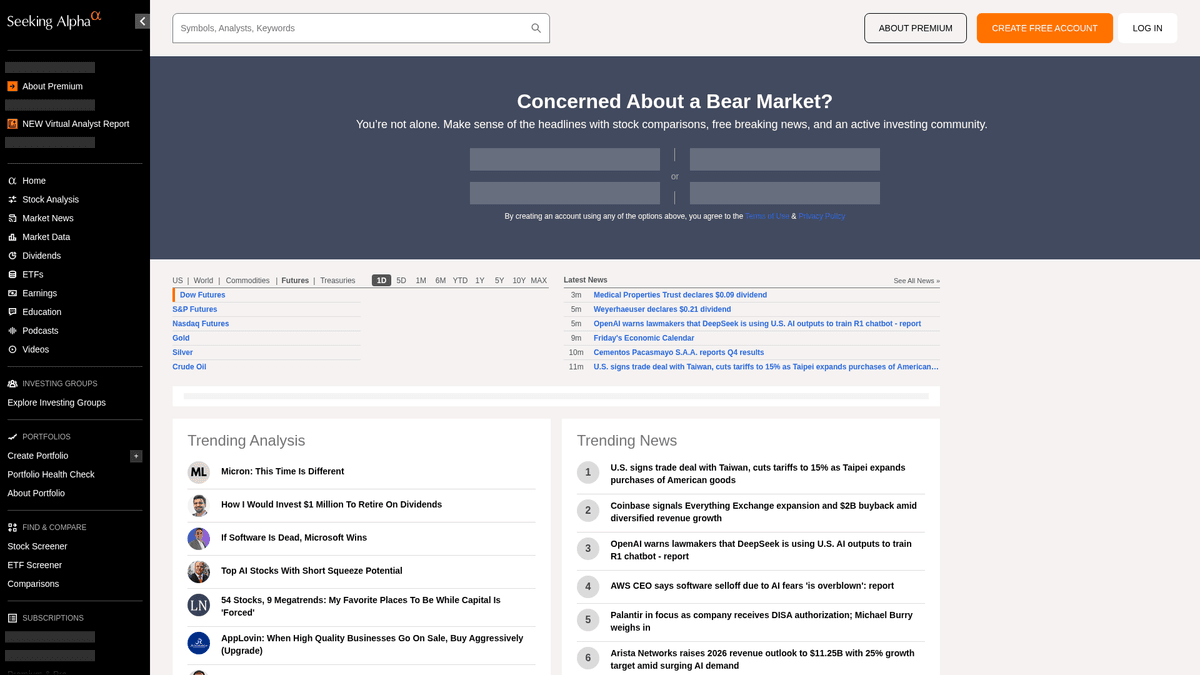
Seeking Alphaについて
Seeking Alphaが提供するものと抽出可能な貴重なデータを発見してください。
金融インテリジェンスのプレミアハブ
Seeking Alphaは、生の市場データと実行可能な投資インサイトを結びつける重要な架け橋として機能する、主要なクラウドソース型金融リサーチプラットフォームです。膨大な数の分析記事、リアルタイムの市場ニュース、そして数千の上場企業に関するインターネット上で最も包括的な決算説明会トランスクリプトのリポジトリをホストしています。
多様なデータエコシステム
このプラットフォームは、ストックアイデア、配当履歴、独自の市場平均を上回るQuant ratingsなど、豊富な構造化および非構造化データを提供しています。プロの編集チームによって管理されており、コンテンツは数千人の独立したアナリストによって作成され、公開前に高い品質とコンプライアンス基準を満たす必要があります。
データ抽出の戦略的価値
Seeking Alphaのスクレイピングは、感情分析(sentiment analysis)を行い、過去の収益トレンドを追跡し、特定のティッカーにわたるニュースを監視する金融アナリストやクオンツトレーダーにとって不可欠です。このデータは、市場心理や企業業績に関する詳細なインサイトを提供し、洗練された金融モデルの構築や競合分析に活用できます。
なぜSeeking Alphaをスクレイピングするのか?
Seeking Alphaからのデータ抽出のビジネス価値とユースケースを発見してください。
アルゴリズム取引のためのクオンツ感情分析エンジンの構築
LLMベースの金融リサーチ用決算トランスクリプトの集約
インカムゲイン・ポートフォリオのための配当変更と配当性向の監視
特定セクターにおけるアナリストのパフォーマンスと評価推移の追跡
機関投資家クライアント向けのリアルタイム市場ニュースダッシュボードの開発
企業のガイダンスと実績の比較による過去の競合分析の実施
スクレイピングの課題
Seeking Alphaのスクレイピング時に遭遇する可能性のある技術的課題。
CloudflareおよびDataDomeの境界セキュリティによる積極的なアンチボット検出
決算説明会トランスクリプトの全文アクセスに対するログイン要件
完全なブラウザレンダリングを必要とするAJAX/XHR経由の動的データ読み込み
高頻度リクエストに対して永続的なIPBANを誘発する高度なレート制限
頻繁に変更されるCSSセレクターを伴う複雑なHTML構造
Seeking AlphaをAIでスクレイピング
コーディング不要。AI搭載の自動化で数分でデータを抽出。
仕組み
必要なものを記述
Seeking Alphaから抽出したいデータをAIに伝えてください。自然言語で入力するだけ — コードやセレクターは不要です。
AIがデータを抽出
人工知能がSeeking Alphaをナビゲートし、動的コンテンツを処理し、あなたが求めたものを正確に抽出します。
データを取得
CSV、JSONでエクスポートしたり、アプリやワークフローに直接送信できる、クリーンで構造化されたデータを受け取ります。
なぜスクレイピングにAIを使うのか
AIを使えば、コードを書かずにSeeking Alphaを簡単にスクレイピングできます。人工知能搭載のプラットフォームが必要なデータを理解します — 自然言語で記述するだけで、AIが自動的に抽出します。
How to scrape with AI:
- 必要なものを記述: Seeking Alphaから抽出したいデータをAIに伝えてください。自然言語で入力するだけ — コードやセレクターは不要です。
- AIがデータを抽出: 人工知能がSeeking Alphaをナビゲートし、動的コンテンツを処理し、あなたが求めたものを正確に抽出します。
- データを取得: CSV、JSONでエクスポートしたり、アプリやワークフローに直接送信できる、クリーンで構造化されたデータを受け取ります。
Why use AI for scraping:
- 複雑なブラウザ自動化ライブラリの管理が不要なノーコード環境
- JavaScriptを多用するサイトや動的コンテンツの読み込みを処理する組み込み機能
- ローカルリソースを使わずに大規模なデータ収集をスケジュール実行できるクラウド実行
- 標準的なアンチボット検出パターンやブラウザのフィンガープリントへの自動対応
Seeking Alpha用ノーコードWebスクレイパー
AI搭載スクレイピングのポイント&クリック代替手段
Browse.ai、Octoparse、Axiom、ParseHubなどのノーコードツールは、コードを書かずにSeeking Alphaをスクレイピングするのに役立ちます。これらのツールは視覚的なインターフェースを使用してデータを選択しますが、複雑な動的コンテンツやアンチボット対策には苦戦する場合があります。
ノーコードツールでの一般的なワークフロー
一般的な課題
学習曲線
セレクタと抽出ロジックの理解に時間がかかる
セレクタの破損
Webサイトの変更によりワークフロー全体が壊れる可能性がある
動的コンテンツの問題
JavaScript多用サイトは複雑な回避策が必要
CAPTCHAの制限
ほとんどのツールはCAPTCHAに手動介入が必要
IPブロック
過度なスクレイピングはIPのブロックにつながる可能性がある
Seeking Alpha用ノーコードWebスクレイパー
Browse.ai、Octoparse、Axiom、ParseHubなどのノーコードツールは、コードを書かずにSeeking Alphaをスクレイピングするのに役立ちます。これらのツールは視覚的なインターフェースを使用してデータを選択しますが、複雑な動的コンテンツやアンチボット対策には苦戦する場合があります。
ノーコードツールでの一般的なワークフロー
- ブラウザ拡張機能をインストールするかプラットフォームに登録する
- ターゲットWebサイトに移動してツールを開く
- ポイント&クリックで抽出するデータ要素を選択する
- 各データフィールドのCSSセレクタを設定する
- 複数ページをスクレイピングするためのページネーションルールを設定する
- CAPTCHAに対処する(多くの場合手動解決が必要)
- 自動実行のスケジュールを設定する
- データをCSV、JSONにエクスポートするかAPIで接続する
一般的な課題
- 学習曲線: セレクタと抽出ロジックの理解に時間がかかる
- セレクタの破損: Webサイトの変更によりワークフロー全体が壊れる可能性がある
- 動的コンテンツの問題: JavaScript多用サイトは複雑な回避策が必要
- CAPTCHAの制限: ほとんどのツールはCAPTCHAに手動介入が必要
- IPブロック: 過度なスクレイピングはIPのブロックにつながる可能性がある
コード例
import requests
from bs4 import BeautifulSoup
# 最新の市場ニュースのURL
url = 'https://seekingalpha.com/market-news'
# 人間の挙動を模倣するための標準的なブラウザヘッダー
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'Accept-Language': 'ja-JP,ja;q=0.9,en-US;q=0.8,en;q=0.7',
'Referer': 'https://seekingalpha.com/'
}
def scrape_sa_news():
try:
response = requests.get(url, headers=headers, timeout=10)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
# data-test-id属性を使用して見出しを抽出
headlines = soup.find_all('a', {'data-test-id': 'post-list-item-title'})
for item in headlines:
print(f'ニュースタイトル: {item.text.strip()}')
else:
print(f'ブロックされました。ステータスコード: {response.status_code}')
except Exception as e:
print(f'エラーが発生しました: {e}')
if __name__ == "__main__":
scrape_sa_news()いつ使うか
JavaScriptが最小限の静的HTMLページに最適。ブログ、ニュースサイト、シンプルなEコマース製品ページに理想的。
メリット
- ●最速の実行(ブラウザオーバーヘッドなし)
- ●最小限のリソース消費
- ●asyncioで簡単に並列化
- ●APIと静的ページに最適
制限事項
- ●JavaScriptを実行できない
- ●SPAや動的コンテンツで失敗
- ●複雑なアンチボットシステムで苦戦する可能性
コードでSeeking Alphaをスクレイピングする方法
Python + Requests
import requests
from bs4 import BeautifulSoup
# 最新の市場ニュースのURL
url = 'https://seekingalpha.com/market-news'
# 人間の挙動を模倣するための標準的なブラウザヘッダー
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'Accept-Language': 'ja-JP,ja;q=0.9,en-US;q=0.8,en;q=0.7',
'Referer': 'https://seekingalpha.com/'
}
def scrape_sa_news():
try:
response = requests.get(url, headers=headers, timeout=10)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
# data-test-id属性を使用して見出しを抽出
headlines = soup.find_all('a', {'data-test-id': 'post-list-item-title'})
for item in headlines:
print(f'ニュースタイトル: {item.text.strip()}')
else:
print(f'ブロックされました。ステータスコード: {response.status_code}')
except Exception as e:
print(f'エラーが発生しました: {e}')
if __name__ == "__main__":
scrape_sa_news()Python + Playwright
from playwright.sync_api import sync_playwright
def run(playwright):
# Chromiumブラウザの起動
browser = playwright.chromium.launch(headless=True)
context = browser.new_context(
user_agent='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
)
page = context.new_page()
try:
# 特定の株式シンボルページへ移動
page.goto('https://seekingalpha.com/symbol/AAPL/transcripts')
# メインコンテンツが動的にレンダリングされるのを待機
page.wait_for_selector('article', timeout=15000)
# トランスクリプトのタイトルを特定して抽出
titles = page.locator('h3').all_inner_texts()
for title in titles:
print(f'トランスクリプトを発見: {title}')
except Exception as e:
print(f'抽出に失敗しました: {e}')
finally:
browser.close()
with sync_playwright() as playwright:
run(playwright)Python + Scrapy
import scrapy
class SeekingAlphaSpider(scrapy.Spider):
name = 'sa_spider'
allowed_domains = ['seekingalpha.com']
start_urls = ['https://seekingalpha.com/latest-articles']
custom_settings = {
'DOWNLOAD_DELAY': 8,
'USER_AGENT': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/120.0.0.0',
'ROBOTSTXT_OBEY': False,
'COOKIES_ENABLED': True
}
def parse(self, response):
for article in response.css('article'):
yield {
'title': article.css('h3 a::text').get(),
'link': response.urljoin(article.css('h3 a::attr(href)').get()),
'author': article.css('span[data-test-id="author-name"]::text').get()
}
# 次のページへのリンクを介したシンプルなページネーション処理
next_page = response.css('a.next_page::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
// 高品質なUser-Agentを設定
await page.setUserAgent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36');
try {
// Seeking Alphaのホームページに移動
await page.goto('https://seekingalpha.com/', { waitUntil: 'networkidle2' });
// ブラウザコンテキスト内でスクリプトを実行してタイトルを抽出
const trending = await page.evaluate(() => {
const nodes = Array.from(document.querySelectorAll('h3'));
return nodes.map(n => n.innerText.trim());
});
console.log('トレンドコンテンツ:', trending);
} catch (err) {
console.error('Puppeteerでエラーが発生しました:', err);
} finally {
await browser.close();
}
})();Seeking Alphaデータで何ができるか
Seeking Alphaデータからの実用的なアプリケーションとインサイトを探索してください。
クオンツ感情分析(Quantitative Sentiment Analysis)
金融機関は、アナリストの記事を利用して特定の株式セクターの市場心理を判断します。
実装方法:
- 1特定の業界ティッカーに関するすべての分析記事を抽出する。
- 2NLPエンジンでコンテンツを処理し、感情の極性を計算する。
- 3感情スコアを既存の取引アルゴリズムに統合する。
- 4感情の変化に基づいて自動売買アラートをトリガーする。
Automatioを使用してSeeking Alphaからデータを抽出し、コードを書かずにこれらのアプリケーションを構築しましょう。
Seeking Alphaデータで何ができるか
- クオンツ感情分析(Quantitative Sentiment Analysis)
金融機関は、アナリストの記事を利用して特定の株式セクターの市場心理を判断します。
- 特定の業界ティッカーに関するすべての分析記事を抽出する。
- NLPエンジンでコンテンツを処理し、感情の極性を計算する。
- 感情スコアを既存の取引アルゴリズムに統合する。
- 感情の変化に基づいて自動売買アラートをトリガーする。
- 決算インサイトの抽出
決算トランスクリプトから企業の重要なガイダンスを直接抽出し、迅速なレポート作成に役立てます。
- 決算トランスクリプトセクションのデイリースクレイピングを自動化する。
- 「EBITDA」や「Outlook(見通し)」などの特定の金融キーワードを検索する。
- 経営陣のガイダンス指標を含む文章を抽出する。
- 投資委員会での検討用に、結果を構造化されたCSVへエクスポートする。
- 配当利回りのベンチマーキング
数千の銘柄間で配当パフォーマンスを比較し、利回り機会を見つけ出します。
- 定義された銘柄リストの配当履歴と配当性向をスクレイピングする。
- 取得したデータを使用して、平均利回り対過去のトレンドを計算する。
- 最近増配した銘柄を特定する。
- リアルタイムの利回り比較でプライベートダッシュボードを更新する。
- アナリストのパフォーマンス追跡
精度の高い執筆者を特定し、より優れた投資アイデアをフォローします。
- 評価の高い執筆者による過去の評価と記事をスクレイピングする。
- 記事の公開日と株価パフォーマンスを照合する。
- 「買い」または「売り」推奨の正確性に基づいて執筆者をランク付けする。
- 上位ランクの執筆者が新しいアイデアを投稿した際に自動通知を送信する。
ワークフローを強化する AI自動化
AutomatioはAIエージェント、ウェブ自動化、スマート統合のパワーを組み合わせ、より短時間でより多くのことを達成するお手伝いをします。
Seeking Alphaスクレイピングのプロのヒント
Seeking Alphaからデータを正常に抽出するための専門家のアドバイス。
CloudflareやDataDomeの境界を効果的に回避するために、プレミアム住宅用(レジデンシャル)プロキシを使用してください。
User-Agent文字列をローテートし、セッション内で一貫したブラウザのフィンガープリントを維持してください。
人間のブラウジングパターンを模倣するために、10秒から30秒のランダムな待機時間を実装してください。
アクセス制限(rate limits)の可能性を減らすため、市場の閉場後や週末にスクレイピングを実行してください。
よりクリーンなデータを取得するために、DevToolsの「ネットワーク」タブで内部のJSON APIエンドポイント(v3/api)を確認してください。
ログインが必要なデータをスクレイピングする必要がある場合は、永続的なセッションCookieを保持してください。
お客様の声
ユーザーの声
ワークフローを変革した何千人もの満足したユーザーに加わりましょう
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
関連 Web Scraping
How to Scrape Moon.ly | Step-by-Step NFT Data Extraction Guide
How to Scrape Yahoo Finance: Extract Stock Market Data
How to Scrape Rocket Mortgage: A Comprehensive Guide
How to Scrape Open Collective: Financial and Contributor Data Guide
How to Scrape jup.ag: Jupiter DEX Web Scraper Guide
How to Scrape Indiegogo: The Ultimate Crowdfunding Data Extraction Guide
How to Scrape ICO Drops: Comprehensive Crypto Data Guide
How to Scrape Crypto.com: Comprehensive Market Data Guide
Seeking Alphaについてのよくある質問
Seeking Alphaに関するよくある質問への回答を見つけてください