Jak scrapować Seeking Alpha: dane finansowe i transkrypcje
Dowiedz się, jak scrapować Seeking Alpha w poszukiwaniu wiadomości giełdowych, ratingów analityków i transkrypcji. Naucz się omijać Cloudflare i wyodrębniać...
Wykryto ochronę przed botami
- Cloudflare
- Korporacyjny WAF i zarządzanie botami. Używa wyzwań JavaScript, CAPTCHA i analizy behawioralnej. Wymaga automatyzacji przeglądarki z ustawieniami stealth.
- DataDome
- Wykrywanie botów w czasie rzeczywistym za pomocą modeli ML. Analizuje odcisk urządzenia, sygnały sieciowe i wzorce zachowań. Częsty na stronach e-commerce.
- Google reCAPTCHA
- System CAPTCHA Google. v2 wymaga interakcji użytkownika, v3 działa cicho z oceną ryzyka. Można rozwiązać za pomocą usług CAPTCHA.
- Ograniczanie szybkości
- Ogranicza liczbę żądań na IP/sesję w czasie. Można obejść za pomocą rotacyjnych proxy, opóźnień żądań i rozproszonego scrapingu.
- Blokowanie IP
- Blokuje znane IP centrów danych i oznaczone adresy. Wymaga rezydencjalnych lub mobilnych proxy do skutecznego obejścia.
O Seeking Alpha
Odkryj, co oferuje Seeking Alpha i jakie cenne dane można wyodrębnić.
Główne centrum inteligencji finansowej
Seeking Alpha to wiodąca platforma analiz finansowych typu crowd-sourced, która stanowi kluczowy pomost między surowymi danymi rynkowymi a konkretnymi wnioskami inwestycyjnymi. Gości ona obszerną bibliotekę artykułów analitycznych, wiadomości rynkowe w czasie rzeczywistym oraz najbardziej kompleksowe w internecie repozytorium transkrypcji z konferencji wynikowych (earnings call transcripts) dla tysięcy spółek giełdowych.
Zróżnicowany ekosystem danych
Platforma oferuje bogactwo danych strukturalnych i nieustrukturyzowanych, w tym pomysły na akcje, historie dywidend oraz autorskie ratingi Quant. Treści zarządzane przez profesjonalny zespół redakcyjny są generowane przez tysiące niezależnych analityków, których wkład musi spełniać wysokie standardy jakości i zgodności przed publikacją.
Strategiczna wartość ekstrakcji danych
Scraping Seeking Alpha jest niezbędny dla analityków finansowych i traderów ilościowych, którzy przeprowadzają analizę sentymentu (sentiment analysis), śledzą historyczne trendy wyników i monitorują wiadomości dotyczące konkretnych tickerów. Dane te dostarczają szczegółowych informacji na temat psychologii rynku i kondycji korporacyjnej, które można wykorzystać do budowy zaawansowanych modeli finansowych oraz wywiadu konkurencyjnego.
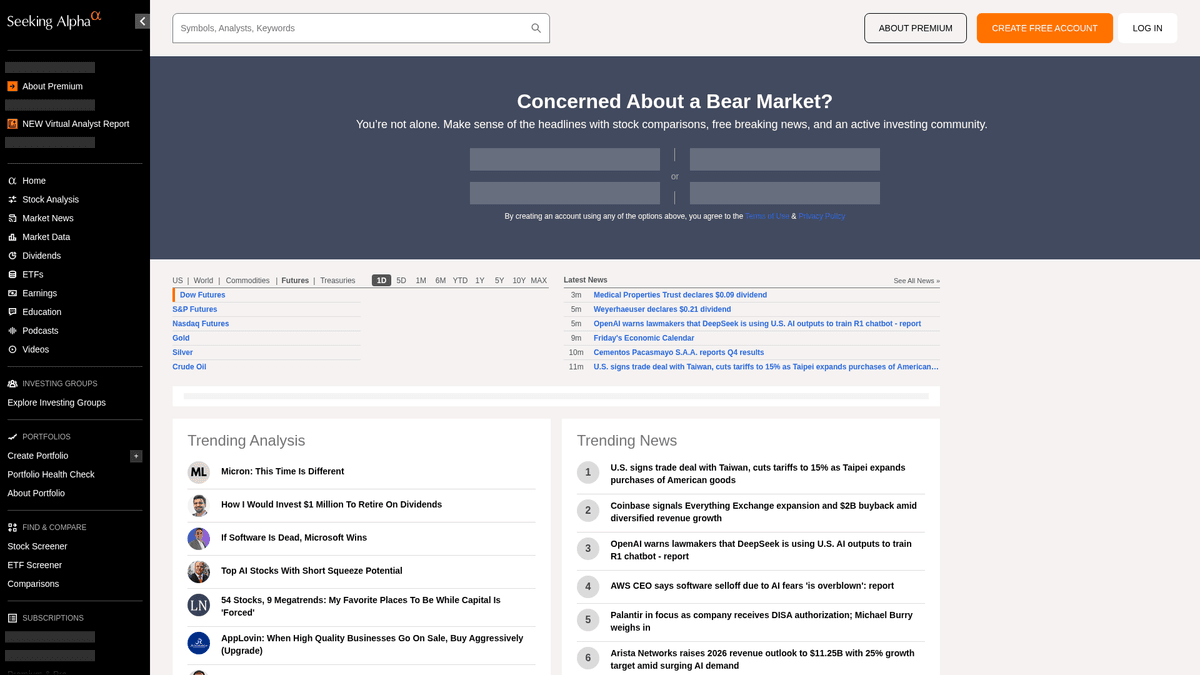
Dlaczego Scrapować Seeking Alpha?
Odkryj wartość biznesową i przypadki użycia ekstrakcji danych z Seeking Alpha.
Budowa silników ilościowej analizy sentymentu dla handlu algorytmicznego
Agregowanie transkrypcji z konferencji wynikowych dla badań finansowych opartych na LLM
Monitorowanie zmian dywidend i wskaźników wypłat dla portfeli dochodowych
Śledzenie wyników analityków i zmian ratingów w konkretnych sektorach
Tworzenie dashboardów z wiadomościami rynkowymi w czasie rzeczywistym dla klientów instytucjonalnych
Przeprowadzanie historycznej analizy porównawczej prognoz spółek z ich wynikami
Wyzwania Scrapowania
Wyzwania techniczne, które możesz napotkać podczas scrapowania Seeking Alpha.
Agresywne wykrywanie botów z wykorzystaniem zabezpieczeń brzegowych Cloudflare i DataDome
Wymóg logowania w celu uzyskania dostępu do pełnych tekstów transkrypcji earnings call
Dynamiczne ładowanie danych przez AJAX/XHR, które wymaga pełnego renderowania przeglądarki
Zaawansowane rate limiting, które powoduje trwałe blokady IP przy zapytaniach o wysokiej częstotliwości
Złożone struktury HTML z często zmieniającymi się selektorami CSS
Scrapuj Seeking Alpha z AI
Bez kodowania. Wyodrębnij dane w kilka minut dzięki automatyzacji opartej na AI.
Jak to działa
Opisz, czego potrzebujesz
Powiedz AI, jakie dane chcesz wyodrębnić z Seeking Alpha. Po prostu wpisz to w języku naturalnym — bez kodu czy selektorów.
AI wyodrębnia dane
Nasza sztuczna inteligencja nawiguje po Seeking Alpha, obsługuje dynamiczną treść i wyodrębnia dokładnie to, o co prosiłeś.
Otrzymaj swoje dane
Otrzymaj czyste, ustrukturyzowane dane gotowe do eksportu jako CSV, JSON lub do bezpośredniego przesłania do twoich aplikacji.
Dlaczego warto używać AI do scrapowania
AI ułatwia scrapowanie Seeking Alpha bez pisania kodu. Nasza platforma oparta na sztucznej inteligencji rozumie, jakich danych potrzebujesz — po prostu opisz je w języku naturalnym, a AI wyodrębni je automatycznie.
How to scrape with AI:
- Opisz, czego potrzebujesz: Powiedz AI, jakie dane chcesz wyodrębnić z Seeking Alpha. Po prostu wpisz to w języku naturalnym — bez kodu czy selektorów.
- AI wyodrębnia dane: Nasza sztuczna inteligencja nawiguje po Seeking Alpha, obsługuje dynamiczną treść i wyodrębnia dokładnie to, o co prosiłeś.
- Otrzymaj swoje dane: Otrzymaj czyste, ustrukturyzowane dane gotowe do eksportu jako CSV, JSON lub do bezpośredniego przesłania do twoich aplikacji.
Why use AI for scraping:
- Środowisko no-code eliminuje potrzebę zarządzania złożonymi bibliotekami automatyzacji przeglądarki
- Wbudowana zdolność do obsługi stron intensywnie korzystających z JavaScript i dynamicznego ładowania treści
- Wykonywanie zadań w chmurze pozwala na zaplanowane zbieranie dużych ilości danych bez obciążania lokalnych zasobów
- Automatyczna obsługa standardowych wzorców wykrywania botów i browser fingerprinting
Scrapery No-Code dla Seeking Alpha
Alternatywy point-and-click dla scrapingu opartego na AI
Różne narzędzia no-code jak Browse.ai, Octoparse, Axiom i ParseHub mogą pomóc w scrapowaniu Seeking Alpha bez pisania kodu. Te narzędzia używają wizualnych interfejsów do wyboru danych, choć mogą mieć problemy ze złożoną dynamiczną zawartością lub zabezpieczeniami anti-bot.
Typowy Workflow z Narzędziami No-Code
Częste Wyzwania
Krzywa uczenia
Zrozumienie selektorów i logiki ekstrakcji wymaga czasu
Selektory się psują
Zmiany na stronie mogą zepsuć cały przepływ pracy
Problemy z dynamiczną treścią
Strony bogate w JavaScript wymagają złożonych obejść
Ograniczenia CAPTCHA
Większość narzędzi wymaga ręcznej interwencji przy CAPTCHA
Blokowanie IP
Agresywne scrapowanie może prowadzić do zablokowania IP
Scrapery No-Code dla Seeking Alpha
Różne narzędzia no-code jak Browse.ai, Octoparse, Axiom i ParseHub mogą pomóc w scrapowaniu Seeking Alpha bez pisania kodu. Te narzędzia używają wizualnych interfejsów do wyboru danych, choć mogą mieć problemy ze złożoną dynamiczną zawartością lub zabezpieczeniami anti-bot.
Typowy Workflow z Narzędziami No-Code
- Zainstaluj rozszerzenie przeglądarki lub zarejestruj się na platformie
- Przejdź do docelowej strony i otwórz narzędzie
- Wybierz elementy danych do wyodrębnienia metodą point-and-click
- Skonfiguruj selektory CSS dla każdego pola danych
- Ustaw reguły paginacji do scrapowania wielu stron
- Obsłuż CAPTCHA (często wymaga ręcznego rozwiązywania)
- Skonfiguruj harmonogram automatycznych uruchomień
- Eksportuj dane do CSV, JSON lub połącz przez API
Częste Wyzwania
- Krzywa uczenia: Zrozumienie selektorów i logiki ekstrakcji wymaga czasu
- Selektory się psują: Zmiany na stronie mogą zepsuć cały przepływ pracy
- Problemy z dynamiczną treścią: Strony bogate w JavaScript wymagają złożonych obejść
- Ograniczenia CAPTCHA: Większość narzędzi wymaga ręcznej interwencji przy CAPTCHA
- Blokowanie IP: Agresywne scrapowanie może prowadzić do zablokowania IP
Przykłady kodu
import requests
from bs4 import BeautifulSoup
# URL do najnowszych wiadomości rynkowych
url = 'https://seekingalpha.com/market-news'
# Standardowe nagłówki przeglądarki, aby naśladować zachowanie człowieka
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'Accept-Language': 'pl-PL,pl;q=0.9,en-US;q=0.8,en;q=0.7',
'Referer': 'https://seekingalpha.com/'
}
def scrape_sa_news():
try:
response = requests.get(url, headers=headers, timeout=10)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
# Ekstrakcja nagłówków przy użyciu atrybutów data-test-id
headlines = soup.find_all('a', {'data-test-id': 'post-list-item-title'})
for item in headlines:
print(f'Tytuł wiadomości: {item.text.strip()}')
else:
print(f'Zablokowano, status: {response.status_code}')
except Exception as e:
print(f'Wystąpił błąd: {e}')
if __name__ == "__main__":
scrape_sa_news()Kiedy Używać
Najlepsze dla statycznych stron HTML z minimalnym JavaScript. Idealne dla blogów, serwisów informacyjnych i prostych stron produktowych e-commerce.
Zalety
- ●Najszybsze wykonanie (bez narzutu przeglądarki)
- ●Najniższe zużycie zasobów
- ●Łatwe do zrównoleglenia z asyncio
- ●Świetne dla API i stron statycznych
Ograniczenia
- ●Nie może wykonywać JavaScript
- ●Zawodzi na SPA i dynamicznej zawartości
- ●Może mieć problemy ze złożonymi systemami anti-bot
Jak scrapować Seeking Alpha za pomocą kodu
Python + Requests
import requests
from bs4 import BeautifulSoup
# URL do najnowszych wiadomości rynkowych
url = 'https://seekingalpha.com/market-news'
# Standardowe nagłówki przeglądarki, aby naśladować zachowanie człowieka
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'Accept-Language': 'pl-PL,pl;q=0.9,en-US;q=0.8,en;q=0.7',
'Referer': 'https://seekingalpha.com/'
}
def scrape_sa_news():
try:
response = requests.get(url, headers=headers, timeout=10)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
# Ekstrakcja nagłówków przy użyciu atrybutów data-test-id
headlines = soup.find_all('a', {'data-test-id': 'post-list-item-title'})
for item in headlines:
print(f'Tytuł wiadomości: {item.text.strip()}')
else:
print(f'Zablokowano, status: {response.status_code}')
except Exception as e:
print(f'Wystąpił błąd: {e}')
if __name__ == "__main__":
scrape_sa_news()Python + Playwright
from playwright.sync_api import sync_playwright
def run(playwright):
# Uruchomienie przeglądarki Chromium
browser = playwright.chromium.launch(headless=True)
context = browser.new_context(
user_agent='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
)
page = context.new_page()
try:
# Nawigacja do strony z transkrypcjami konkretnego symbolu
page.goto('https://seekingalpha.com/symbol/AAPL/transcripts')
# Czekanie na dynamiczne wyrenderowanie głównej treści
page.wait_for_selector('article', timeout=15000)
# Lokalizacja i ekstrakcja tytułów transkrypcji
titles = page.locator('h3').all_inner_texts()
for title in titles:
print(f'Znaleziono transkrypcję: {title}')
except Exception as e:
print(f'Ekstrakcja nie powiodła się: {e}')
finally:
browser.close()
with sync_playwright() as playwright:
run(playwright)Python + Scrapy
import scrapy
class SeekingAlphaSpider(scrapy.Spider):
name = 'sa_spider'
allowed_domains = ['seekingalpha.com']
start_urls = ['https://seekingalpha.com/latest-articles']
custom_settings = {
'DOWNLOAD_DELAY': 8,
'USER_AGENT': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/120.0.0.0',
'ROBOTSTXT_OBEY': False,
'COOKIES_ENABLED': True
}
def parse(self, response):
for article in response.css('article'):
yield {
'title': article.css('h3 a::text').get(),
'link': response.urljoin(article.css('h3 a::attr(href)').get()),
'author': article.css('span[data-test-id="author-name"]::text').get()
}
# Obsługa prostej paginacji przez linki 'następna'
next_page = response.css('a.next_page::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
// Ustawienie wysokiej jakości User-Agent
await page.setUserAgent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36');
try {
// Nawigacja do strony głównej Seeking Alpha
await page.goto('https://seekingalpha.com/', { waitUntil: 'networkidle2' });
// Ewaluacja skryptów w kontekście przeglądarki w celu wyodrębnienia tytułów
const trending = await page.evaluate(() => {
const nodes = Array.from(document.querySelectorAll('h3'));
return nodes.map(n => n.innerText.trim());
});
console.log('Trendujące treści:', trending);
} catch (err) {
console.error('Puppeteer napotkał błąd:', err);
} finally {
await browser.close();
}
})();Co Możesz Zrobić Z Danymi Seeking Alpha
Poznaj praktyczne zastosowania i wnioski z danych Seeking Alpha.
Ilościowa analiza sentymentu
Firmy finansowe wykorzystują artykuły analityków do określenia sentymentu rynkowego dla konkretnych sektorów giełdowych.
Jak wdrożyć:
- 1Wyodrębnij wszystkie artykuły analityczne dla tickera z konkretnej branży.
- 2Przetwórz treść przez silnik NLP, aby obliczyć polaryzację sentymentu.
- 3Zintegruj wyniki sentymentu z istniejącymi algorytmami transakcyjnymi.
- 4Uruchamiaj automatyczne alerty kupna/sprzedaży na podstawie zmian sentymentu.
Użyj Automatio do wyodrębnienia danych z Seeking Alpha i budowania tych aplikacji bez pisania kodu.
Co Możesz Zrobić Z Danymi Seeking Alpha
- Ilościowa analiza sentymentu
Firmy finansowe wykorzystują artykuły analityków do określenia sentymentu rynkowego dla konkretnych sektorów giełdowych.
- Wyodrębnij wszystkie artykuły analityczne dla tickera z konkretnej branży.
- Przetwórz treść przez silnik NLP, aby obliczyć polaryzację sentymentu.
- Zintegruj wyniki sentymentu z istniejącymi algorytmami transakcyjnymi.
- Uruchamiaj automatyczne alerty kupna/sprzedaży na podstawie zmian sentymentu.
- Ekstrakcja wniosków z wyników finansowych
Wyodrębniaj kluczowe wytyczne korporacyjne bezpośrednio z transkrypcji earnings call w celu szybkiego raportowania.
- Zautomatyzuj codzienny scraping sekcji Earnings Transcripts.
- Wyszukuj konkretne słowa kluczowe, takie jak 'EBITDA' lub 'Outlook'.
- Wyizoluj zdania zawierające wskaźniki dotyczące prognoz zarządu.
- Eksportuj wyniki do ustrukturyzowanego pliku CSV do przeglądu przez komitet inwestycyjny.
- Benchmarking stopy dywidendy
Porównuj wyniki dywidendowe tysięcy akcji, aby znaleźć okazje o wysokiej rentowności.
- Scrapuj historię dywidend i wskaźniki wypłat dla zdefiniowanej listy akcji.
- Oblicz średnią stopę zwrotu w porównaniu do trendów historycznych, korzystając ze zescrapowanych danych.
- Zidentyfikuj spółki, które ostatnio zwiększyły swoje wypłaty.
- Aktualizuj prywatny dashboard o porównania rentowności w czasie rzeczywistym.
- Śledzenie wyników analityków
Identyfikuj autorów o wysokiej sprawdzalności, aby śledzić lepsze pomysły inwestycyjne.
- Scrapuj historyczne ratingi i artykuły najlepiej ocenianych autorów.
- Zestaw daty publikacji artykułów z wynikami cen akcji.
- Rankuj autorów na podstawie celności ich rekomendacji 'Kup' lub 'Sprzedaj'.
- Wysyłaj automatyczne powiadomienia, gdy wysoko oceniani autorzy publikują nowe pomysły.
Przyspiesz swoj workflow z automatyzacja AI
Automatio laczy moc agentow AI, automatyzacji web i inteligentnych integracji, aby pomoc Ci osiagnac wiecej w krotszym czasie.
Profesjonalne Porady dla Scrapowania Seeking Alpha
Porady ekspertów dotyczące skutecznej ekstrakcji danych z Seeking Alpha.
Używaj premium residential proxies, aby skutecznie omijać zabezpieczenia Cloudflare/DataDome.
Rotuj ciągi User-Agent i zachowuj spójne browser fingerprints w ramach sesji.
Wprowadź losowe czasy oczekiwania od 10 do 30 sekund, aby naśladować naturalne zachowanie użytkownika.
Przeprowadzaj scraping po zamknięciu giełdy lub w weekendy, aby zmniejszyć prawdopodobieństwo nałożenia rate limits przy dużym natężeniu ruchu.
Sprawdź zakładkę 'Network' w DevTools pod kątem wewnętrznych endpointów JSON API (v3/api), aby uzyskać czystsze dane.
Zachowuj trwałe session cookies, jeśli musisz scrapować dane dostępne dopiero po zalogowaniu.
Opinie
Co mowia nasi uzytkownicy
Dolacz do tysiecy zadowolonych uzytkownikow, ktorzy przeksztalcili swoj workflow
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Powiazane Web Scraping
How to Scrape Moon.ly | Step-by-Step NFT Data Extraction Guide
How to Scrape Yahoo Finance: Extract Stock Market Data
How to Scrape Rocket Mortgage: A Comprehensive Guide
How to Scrape Open Collective: Financial and Contributor Data Guide
How to Scrape jup.ag: Jupiter DEX Web Scraper Guide
How to Scrape Indiegogo: The Ultimate Crowdfunding Data Extraction Guide
How to Scrape ICO Drops: Comprehensive Crypto Data Guide
How to Scrape Crypto.com: Comprehensive Market Data Guide
Często Zadawane Pytania o Seeking Alpha
Znajdź odpowiedzi na częste pytania o Seeking Alpha